The «Alphabetical Subject Index Generator» service makes it possible to convert the text of universal decimal classification tables (UDC) into an alphanumeric subject index (ASI). The UDC tables in the format “class code – class description” through a tab are sent to the service as an input, one class per line. The result of the service work is a fragment of ASI.
Basic terms and concepts
Alphabetical subject index (ASI) — the index that is made up from a set of alphabetically ordered words, wordgroups and phrases of the natural language, denoting objects of any branch of science or practical activity [1].
ASI for UDC — the array of matches «terminological unit – coordination code/index» Each match is a separate subject heading [2].
Universal Decimal Classification (UDC) is an international classification system that meets the most essential requirements for classifications: internationality, universality, and extensibility. UDC tables have been translated and published in whole or in part in more than 40 languages, and UDC is used in approximately 130 countries of the world. UDC has been operating in Belarus for the past 50 years. However, only in 2016 the official publication of the UDC in Belarusian appeared. The alphabetical subject index (ASI), which makes up more than a quarter of the publication, was prepared using an algorithm that automated the process of its creation [2].
Practical value
Using this service, ASI for the publication «Universal Decimal Classification» was generated [3].
The algorithm for the automated creation of the alphabetical subject index of UDC in Belarusian
The algorithm makes it possible to form the ASI of UDC based on the texts of its tables and is focused on working with the Belarusian edition of UDC, but the separation of the linguistic and thematic resources used in the algorithm from the algorithm itself allows to adapt it to work with UDC in other languages.
Algorithm input: full text of the main tables of UDC TUDC.
Algorithm Resources:
- text file Fsc containing a list of stop classes;
- text file Fsw containing a list of stop words;
- text file Fdic containing lexicon which is characteristic for UDC with indication of certain grammatical characteristics;
- text file Fdom containing a list of matches «class code – domain».
Input:
Step 1. Loading resources. The Fsc, Fsw, Fdic, Fdom files with special resources are loaded into the computer’s memory, the corresponding lists are formed.
Step 1.1 Creating a list of stop classes. A Fsc file with a list of stop classes is loaded. The list Lsc = <sc1, …, scA> is formed, where sca is the nth stop class, a = 1, …, A.
Step 1.2 Creating a list of stop words. The Fsw file with the list of stop words is loaded. The list Lsw = <sw1, …, swB> is formed, where swb is the bth stop word, b = 1, …, B.
Step 1.3 Formation of a specialized dictionary. The Fdic dictionary file is loaded. The list Ldic = <<w1,wa1,wc1,wi1>, …, <wC,waC,wcC,wiC>> is formed, where wc is the cth word of the dictionary, wac is the emphasis of the cth word of the dictionary, wcc is the category cth word of the dictionary, wic is the initial form of the cth word of the dictionary, c = 1, …, C.
Step 1.4 Formation of a list of classes belonging to domains. The Fdom file is loaded. The list Ldom = <<cl1,dom1>, …, <clD,domD>> is formed, where cld is the dth class of the list, domd is the domain that corresponds to the dth class of the list, d = 1, …, D.
Step 2. Formation of the list of UDC classes. The TUDC input text is divided into separate records – UDC classes, in each notation the class code and the class description are distinguished. Thus, based on the TUDC input text, the list LUDC = <Cl1, … , ClN>, is formed, where Cln = <Notn, Capn>, Notn is the nth code of the class, Capn is the nth class description, n = 1, …, N.
Step 3. Processing the list of UDC classes. A Lres list of correspondences «word – a set of class codes» is created, in which the processing results will be entered. Each Cln element of the LUDC list goes through steps 3.1–3.6.
Step 3.1 Filtering by the list of stop classes. A determination whether the code for the Notn class belongs to the list of stop classes Lsc is made. If affiliation is identified, then the transition to the next element Cln+1 and step 3.1 occurs (for n = N – to step 4). Otherwise there is transition to step 3.2.
Step 3.2 Words distinguishing. In the description of the Capn class, all character sequences matching the pattern structure of the word Ptw are distinguished. Using the PCRE regular expression syntax (https://www.pcre.org/original/doc/html/pcrepattern.html), this template can be represented as follows:
Ptw = [set1][set1set2]* ,
where set1 is the set of characters with which the word can begin, set2 is the set of characters of which the word can consist, but with which the word cannot begin, set1set2 = set1 ∪ set2. The set1 consists of the letters of the Belarusian alphabet; the set2 set consists of a hyphen, an apostrophe, emphasis symbols, etc.
The words distinguished in the description of the class Capn are entered in the list Wcap = <wrd1, … , wrdM>, where wrdm is the mth distinguished word, m = 1, …, M.
Step 3.3 Normalization of words. Each word wrdm from the Wcap list is reduced to a normalized electronic form (words are reduced to lower case; the apostrophes are unified, the letter «ў» is replaced with «y» at the beginning of the word, etc.). The result of this processing is a list of normalized words W’cap = <wrd’1, … , wrd’M>, where wrd’m is the mth normalized word, m = 1, …, M.
Step 3.4 Filter by stop word list. For each word from the W’cap list, a determination whether it belongs to the Lsw stop word list is made. If no belonging is identified, then the word is entered in the list W”cap = <wrd”1, … , wrd”K>, where wrd’k is the kth valid word, k = 1, …, K.
Step 3.5 Filtering by part of speech and reduction to the initial form. For each word from the list W”cap , the part of speech wc and the initial form wi are determined by the list of lexicon typical for UDC Ldic. If the current word is a noun, adjective or participle, then its initial form wi is entered in the list W”’cap = <wrd”’1, … , wrd”’J>, where wrd’j is the jth valid word in the initial form , j = 1, …, J.
Step 3.6 Listing in the final list. Each word in the W”’cap list is listed in the Lres summary list. If the current word does not yet appear in the Lres summary list, the word is added as a new element, which corresponds to an array with one element – the code of the processed class Notn. If the word is already listed in the Lres summary list, then the code of the processed class Notn is listed into the array of class codes corresponding to the processed word.
Step 4. Domains assigning. The elements of the Lres list are enumerated. In each element of Lres, for each class code, the thematic domain dom is determined by the Ldom list. Codes of classes whose domains coincide are grouped into one array.
Thus, the result is the list Lres = <<wrd1, ent1>, …, <wrdR, entR>, where wrdr is the rth word of the final list r = 1, …, R; in its turn, entr = <<dom1, Lnot1>, …, <domS, LnotS>>,, where doms is the sth domain to which the word wrdr, belongs, s = 1, …, S; and at the end, Lnots = <not1, …, notT>,, where nott is the tth code of the class corresponding to the doms domain to which the word wrdr belongs, t = 1, …, T.
Step 5. Formation of the result. The final list Lres is sorted by the Belarusian alphabet and converted to a text format with the necessary formatting. The TASI result is displayed on the screen and saved in the corresponding file on the server.
The end of the algorithm [2].
As a result of the execution of the described algorithm on the basis of the UDC tables in Belarusian language, the ASI is formed. It is worth noting that the proposed algorithm is suitable for expansion to other languages, since the linguistic and thematic resources used in it are separated from the algorithm and can be developed for another language.
User interface description
The service interface is shown in Figure 1.

Figure 1. Interface of the service «Alphabetical Subject Index Generator»
The interface contains the following areas:
- input field;
- option «Get additional information» – the service will provide information about words that could not be processed due to the lack of any necessary information in the database, and also provide a list of amographs found in the input text;
- «Generate Alphabetical Subject Index» button, thanks to which it is possible to get the result.
User work with the service scenario
For the correct work of web service, the UDC tables should be presented in the following format: UDC classes are separated from each other by a line feed, in borders of one notation the class code is separated from the class description by tab (Figure 1).
Scenario 1. ASI Generation
- Enter the correct input data in the input field.
- Click the “Generate Alphabetical Subject Index” button. The results will look like in Figure 2.
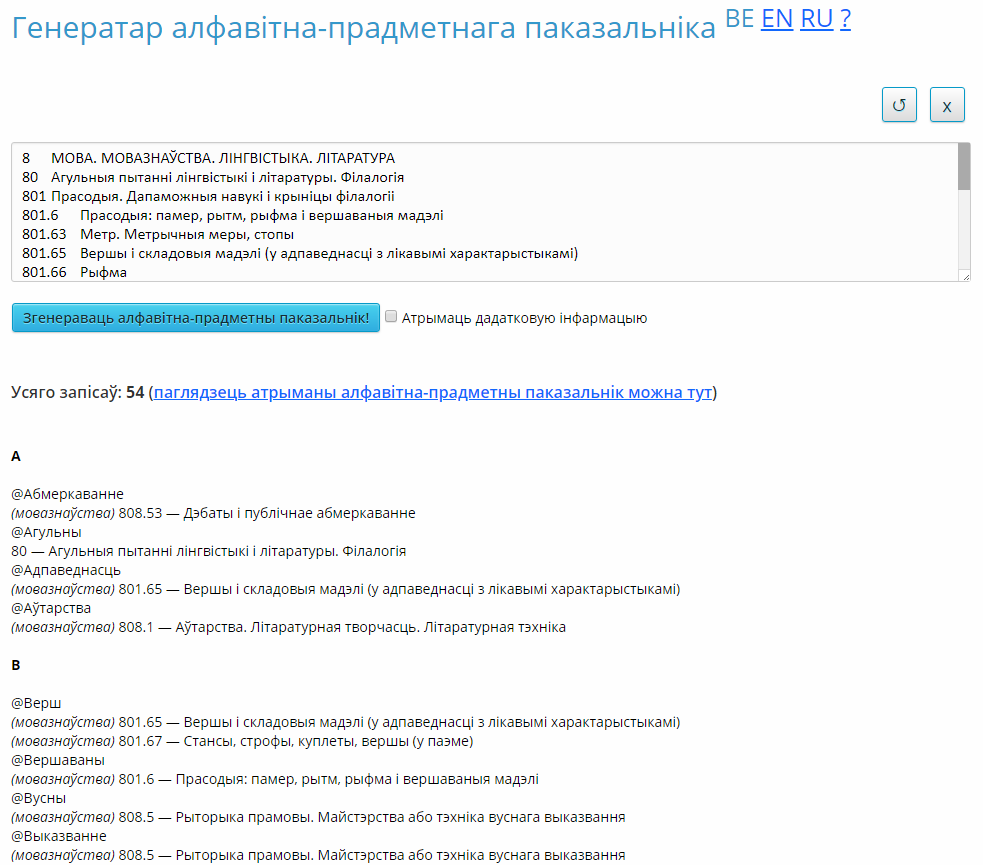
Figure 2. «Alphabetical Subject Index Generator» service results
Scenario 2. Generation of ASI with additional information
The service enables the user not only to generate the ASI based on the entered text, but also to track certain additional information regarding the processing (for this, the «Get additional information» item should be marked). The service will provide information about words that could not be processed due to the lack of any necessary information in the database, as well as provide a list of amographs found in the input text. The table shows an example of the final ASI generated on the basis of a fragment of the UDC tables using the web service «Alphabetical Index Subject Generator».
- Enter the correct input data in the input field.
- Check the option «Get additional information».
- Click the «Generate Alphabetical Subject Index» button. The results will look like in Figure 3.

Figure 3. Results of generation of ASI with additional information. During processing of this input text no additional information was revealed.
Access to the service via the API
To access the «Alphabetical Subject Index Generator» service via the API, you must send an AJAX request of the POST type to the address https://corpus.by/AlphabeticalSubjectIndexGenerator/api.php. The following parameters are passed through the data array:
- text — a fragment of UDC tables in the format «class code — class description» through tabs, one class per line.
- additionalInfo — marker of the need for additional information.
Example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/AlphabeticalSubjectIndexGenerator/api.php”,
data:{
“text”: “8 МОВА. МОВАЗНАЎСТВА. ЛІНГВІСТЫКА. ЛІТАРАТУРА
80 Агульныя пытанні лінгвістыкі і літаратуры. Філалогія
801 Прасодыя. Дапаможныя навукі і крыніцы філалогіі
801.6 Прасодыя: памер, рытм, рыфма і вершаваныя мадэлі
801.63 Метр. Метрычныя меры, стопы
801.65 Вершы і складовыя мадэлі (у адпаведнасці з лікавымі характарыстыкамі)
801.66 Рыфма
801.67 Стансы, строфы, куплеты, вершы (у паэме)
801.7 Дапаможныя філалагічныя дысцыпліны
801.8 Філалагічныя і лінгвістычныя крыніцы. Зборнікі тэкстаў”,
“additionalInfo”: 1
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with the following parameters:
- text — the input fragment of UDC tables.
- result — the final fragment of the alphabetical subject index.
- ResultUrl — the address where the result is saved.
- ResultCnt — the number of semantic units in the result.
- UnknownWordsList — a list of words unknown to the service.
- UnknownWordsListUrl — the address where the UnknownWordsList is saved.
- HomographList — the list of homographs.
- HomographListUrl — the address where the HomographList is saved.
- UnaccentedWordsList — the list of words for which it was not possible to determine the emphasis.
- UnaccentedWordsListUrl — the address where the UnaccentedWordsList is saved.
For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “8 МОВА. МОВАЗНАЎСТВА. ЛІНГВІСТЫКА. ЛІТАРАТУРА <…>“,
“result”: “<b>А</b><br><br>@Агульны<br>80 — Агульныя пытанні лінгвістыкі і літаратуры. Філалогія<br> <…>“,
“UnknownWordsList”: “”,
“UnknownWordsListUrl”: “”,
“HomographList”: “”,
“HomographListUrl”: “”,
“UnaccentedWordsList”: “”,
“UnaccentedWordsListUrl”: “”,
“ResultCnt”: 31,
“ResultUrl”: “https://corpus.by/showCache.php?s=AlphabeticalSubjectIndexGenerator&t=out&f=2018-06-25_17-17-47_80-94-162-88_326_out.txt”
}
]
Sources references
Page of the service: https://corpus.by/AlphabeticalSubjectIndexGenerator/?lang=en
Related articles: https://ssrlab.by/tag/udc
Cross references
- Профессиональное образование. Словарь. Ключевые понятия, термины, актуальная лексика. — М.: НМЦ СПО. С.М. Вишнякова. 1999.
- Лысы, С. І. Аўтаматызаваная генерацыя алфавітна-прадметнага паказальніка Універсальнай дзесятковай класіфікацыі на беларускай мове / С. І. Лысы, Г. Р. Станіславенка, Ю. С. Гецэвіч // Информатика. – 2018. − Т. 15, № 2. – С. 7–16.
- Універсальная дзесятковая класіфікацыя : звыш 10 000 асноўных і дапаможных класаў / Аб’яднаны інстытут праблем інфарматыкі Нацыянальнай акадэміі навук Беларусі, Нацыянальная бібліятэка Беларусі; [рэдакцыйная калегія: Ю. С. Гецэвіч, С. А. Пугачова, Г. Р. Станіславенка і інш. ; укладальнікі алфавітна‑прадметнага паказальніка: С. І. Лысы, Г. Р. Станіславенка, Ю. С. Гецэвіч]. – Мінск, 2016. – 370 с.
- Драгун, А. Я. Аўтаматызаваныя сродкі атрымання расшыфроўкі і спісаў кодаў беларускамоўнай Універсальнай дзесятковай класіфікацыі / А. Я. Драгун, Я. С. Зяноўка, М. С. Галаўчак, С. С. Маеўскі, Ю. С. Гецэвіч // Материалы VII Международного конгресса «Библиотека как феномен культуры» : Краеведение и страноведение в сохранении культурного разнообразия, Минск, 21–22 октября 2020 г. / Национальная библиотека Беларуси ; [сост.: Т. В. Кузьминич, А. А. Суша]. – Минск, 2020. – С. 300-306.
- Універсальная дзесятковая класіфікацыя : Асноўная табліца. Класы 0-9. Дапаможныя табліцы. Алфавітна-прадметны паказальнік : першае скарочанае выданне на беларускай мове.
- Hetsevich, Yu.S. Preparation of the First UDC Abridged Edition in Belarusian / Yu.S. Hetsevich, A.M. Skopinava, T.I. Okrut, S.A. Hetsevich, S.A. Pugachova // Extensions and Corrections to the UDC. – 2014-2015. – №36-37. – P. 23-30.
- Станіславенка, Г.Р. Выкарыстанне камп’ютарна-лінгвістычных сродкаў для перакладу ўніверсальнай дзесятковай класіфікацыі дамена “тэатр” з англійскай на беларускую мову і генерацыя алфавітна-прадметнага паказальніка / Г.Р. Станіславенка, Ю.С. Гецэвіч, С.І. Лысы // Актуальные вопросы германской филологии и лингводидактики: материалы XX Междунар. науч.-практ. конф. / Брест. гос. ун-т имени А.С. Пушкина; редкол.: Е. Г. Сальникова [и др.]. — Брест : Альтернатива, 2016. — C. 264-266.
- Станиславенко, А.Г. Этапы подготовки первого издания УДК на беларусском языке / А.Г. Станиславенко, С.И. Лысы, Ю.С. Гецевич // Информация в современном мире : доклады Международной конференции, Москва, 25-26 октября 2017 г. / ВИНИТИ РАН. — Москва : ВИНИТИ РАН, 2017. — C. 297-303.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.