Сэрвіс «Генератар арфаэпічнага слоўніка» выконвае задачу канвертавання электроннага арфаграфічнага запісу беларускіх слоў у фанетычную транскрыпцыю ў адпаведнасці з нормамі сучаснага беларускага маўлення. На ўваход сэрвісу падаецца тэкст на беларускай мове, далей сэрвіс прадстаўляе зыходныя дадзеныя ў транскрыбіраваным выглядзе: на выхадзе апрацоўкі падаецца кірылічная транскрыпцыя слова, якая адлюстроўвае яго правільнае вымаўленне.
Асноўныя тэрміны і паняцці
Арфаэпія (ад стар.-грэч. Ὀρθός — «правільны» і ἔπος — «маўленне») — сукупнасць правіл вуснага маўлення, замацаваных у літаратурнай мове. Шырокая трактоўка паняцця ўключае нормы вымаўлення і націску, вузкая трактоўка выключае націск з правілаў арфаэпіі.
Транскрыпцыя (літаральна перапісванне, лац. trans– — «праз, пера-» і scribo — «чарчу, пішу») — перадача элементаў гукавога маўлення (фанем, алафонаў, гукаў) на пісьме з дапамогай пэўнай сістэмы знакаў.
Фанетычная транскрыпцыя — перадача гучання слова.
Практычная каштоўнасць
Сёння правільная моўная практыка важная для тых, хто ў прафесійнай дзейнасці штодзённа карыстаецца вуснай і пісьмовай формамі літаратурнай мовы — настаўнікаў, выкладчыкаў, рэдакцыйна-выдавецкіх работнікаў, прадстаўнікоў інтэлігенцыі.
Прынцып генерацыі транскрыпцыі для беларускай мовы, рэалізаваны ў гэтым сэрвісе, лёг таксама ў аснову «Арфаэпічнага слоўніка беларускай мовы» [1], упершыню выдадзенага ў 2017 годзе. Сістэма аўтаматызаванай генерацыі транскрыпцыі дазволіла значна скараціць працу па стварэнні гэтага слоўніка, даючы дакладны вынік больш чым у 98% выпадкаў, а таксама аднастайна рэалізаваць канцэптуальную аснову слоўніка, які мае каля 117 000 загалоўных артыкулаў.
Каб паказаць рэальныя вынікі працы дадзенага сэрвіса, ніжэй прыведзены фрагмент электроннага арфаграфічнага слоўніка, які быў узяты за аснову для стварэння арфаэпічнага слоўніка (малюнак 1).

Малюнак 1. Фрагмент электроннага арфаграфічнага слоўніка, які быў узяты за аснову для стварэння арфаэпічнага слоўніка
Як бачна з малюнка, пасля рэестравага слова падаюцца некаторыя граматычныя пазнакі, а таксама ў дужках удакладненне таго, што менавіта абазначае слова, бо адрозненне, напрыклад, адушаўлёнасці/неадушаўлёнасці з’яўляецца абавязковым пры вызначэнні канчаткаў слова ў розных склонах. У дужках пасля формы слова таксама можа пазначацца варыянтны канчатак. Усе гэтыя дадатковыя дадзеныя ў арфаэпічным слоўніку не мусяць транскрыбіравацца, таму не павінны ўлічвацца сэрвісам генерацыі. Ніжэй прыведзены фрагмент апрацаванага электроннага арфаграфічнага слоўніка з пазначэннем транскрыпцыі (малюнак 2). На выхадзе апрацоўкі тэксту пасля загаловачнага слова і пасля кожнай з яго формаў падаецца кірылічная транскрыпцыя, якая адлюстроўвае правільнае вымаўленне.

Малюнак 2. Фрагмент апрацаванага электроннага арфаграфічнага слоўніка з пазначэннем транскрыпцыі
Такім чынам, створаны сэрвіс арфаэпічнага генератара слоўнікаў прызначаны для пераўтварэння зыходных дадзеных у транскрыбіраваны выгляд, што значна палягчае працу лінгвістаў па стварэнні арфаэпічнага слоўніка беларускай мовы, а таксама дае магчымасць прыстасаваць дадзены сэрвіс пад вырашэнне іншых лінгвістычных задач. Так, уяўляецца магчымым стварыць падобны сэрвіс для адлюстравання арфаэпіі дыялектнай мовы. Адпаведны аўтаматычны сэрвіс можна зрабіць і для іншых моў, у прыватнасці, для ўкраінскай.
Апісанне карыстальніцкага інтэрфейсу
Знешні інтэрфейс сэрвіса прадстаўлены на малюнку 3.
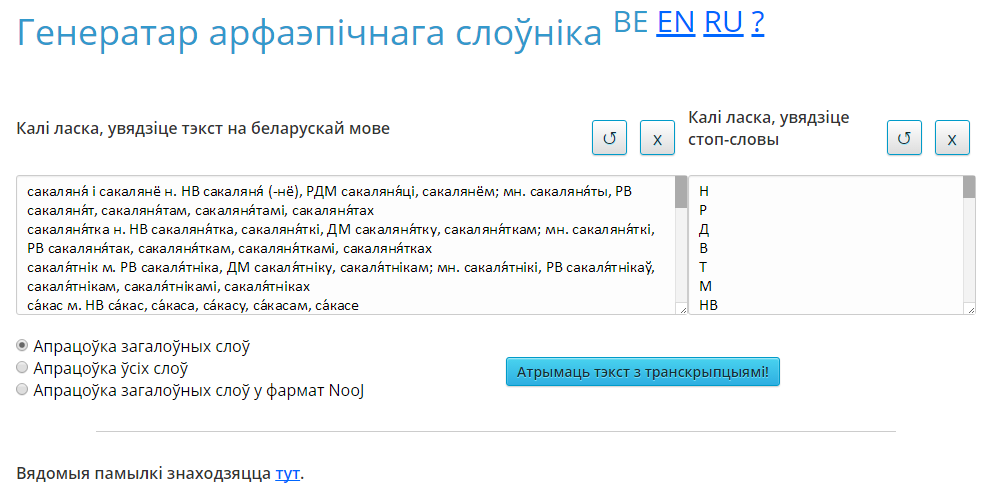
Малюнак 3. Знешні інтэрфейс сэрвісу «Генератар арфаэпічнага слоўніка»
Інтэрфейс змяшчае наступныя вобласці:
- поле ўводу электроннага тэксту з магчымасцю ачысціць яго ад прыкладу і вярнуць прыклад (правы верхні кут);
- поле ўводу стоп-слоў з магчымасцю ачысціць яго ад прыкладу і вярнуць прыклад (правы верхні кут) — акрамя рэестравага слова ў слоўніку часта падаюцца і яго пэўныя формы, а таксама граматычныя і стылістычныя прыкметы, таму праз іх можна атрымаць непатрэбную транскрыпцыю. Каб гэтага пазбегнуць, неабходна ўвесці гэтыя словы ў поле ўводу стоп-слоў, тады транскрыпцыі для іх генеравацца не будуць (па змаўчанні ўведзеныя тыповыя скарачэнні);
- поле выбару тыпу апрацоўкі:
- апрацоўка загалоўных слоў;
- апрацоўка ўсіх слоў;
- апрацоўка загалоўных слоў у фармат NooJ;
- кнопка «Атрымаць тэкст з транскрыпцыямі!»;
- поле вываду вынікаў, якое ўтвараецца пасля націскання папярэдняй кнопкі;
- спасылка на спампаванне файла, які змяшчае вядомыя памылкі транскрыбіравання.
Карыстальніцкі сцэнар працы з сэрвісам
- Увесці слова ці пэўную частку ўзятага за аснову арфаграфічнага слоўніка ў поле ўводу.
- У вобласці выбару спосабу апрацоўкі абраць адзін з варыянтаў:
- апрацоўка загалоўных слоў — будзе дадзеная транскрыпцыя першага слова ў радку (слова, распазнанага сэрвісам як загалоўнае);
- апрацоўка ўсіх слоў — будзе дадзеная транскрыпцыя ўсіх слоў, пададзеных на апрацоўку;
- апрацоўка загалоўных слоў у фармат NooJ — загалоўнае слова будзе апрацавана ў фармат NooJ, астатнія словы будуць транскрыбіраваныя.
- Націснуць кнопку «Атрымаць тэкст з транскрыпцыямі!» для запуску апрацоўкі і атрымання вынікаў (малюнак 4).

Малюнак 4. Вынікі працы сэрвіса «Генератар арфаэпічнага слоўніка»
Доступ да сэрвіса пра API
Для доступу да сэрвіса “Генератар арфаэпічнага слоўніка” праз API, неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/OrthoepicDictionaryGenerator/api.php. Праз масіў data перадаюцца наступныя параметры:
- text — уваходны тэкст, які можа ўяўляць сабой як адвольны тэкст, так і спіс слоў (па слове на радок) ці фрагмент слоўніка.
- stopWords — спіс слоў, якія пры апрацоўцы не павінны транскрыбавацца. Словы падаюцца праз прабел ці перавод радка. У выніковым тэксце пасля іх не будзе выводзіцца транскрыпцыя, а самі яны будуць пададзены курсівам.
- mode — фармат апрацоўкі. Даступна тры фарматы апрацоўкі:
- headwordsProcessing — выніковы тэкст будзе ўяўляць сабой толькі першае слова з кожнага радка і яго транскрыпцыю;
- allWordsProcessing — транскрыпцыя з’явіцца пасля кожнага слова за выключэннем стоп-слоў;
- noojFormatProcessing — будуць апрацаваны толькі першыя словы кожнага радка і прыведзены ў NooJ-фармат.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/OrthoepicDictionaryGenerator/api.php”,
data:{
“text”: “саке́ н., нескл.”,
“stopWords”: “н. нескл.”,
“mode”: “allWordsProcessing”
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з уваходным і выніковым тэкстамі. Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “саке́ н., нескл.”,
“result”: “<b>саке́ </b> [сак’э́] <i>н.</i>, <i>нескл.</i>”
}
]
Перакрыжаваныя спасылкі
- Арфаэпічны слоўнік беларускай мовы / Нац. акад. навук Беларусі, Інстытут мовазнаўства імя Якуба Коласа, Аб’яднаны інстытут праблем інфарматыкі ; уклад.: В. П. Русак, Ю. С. Гецэвіч, С. І. Лысы, В. А. Мандзік ; рэдкал.: В. П. Русак, Ю. С. Гецэвіч, С. І. Лысы. — Мінск : Беларуская навука, 2017. — 757 с.
Спасылкі на крыніцы
Старонка сэрвіса: https://corpus.by/OrthoepicDictionaryGenerator/?lang=be
Перакрыжаваныя спасылкі
- Гецэвіч, Ю.С. Праектаванне інтэрнэт-сервісаў для працэсараў сінтэзатара маўлення па тэксце з магчымасцю прадстаўлення бясплатных электронных паслуг насельніцтву / Ю.С. Гецэвіч, С.І. Лысы // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2014) : доклады XIII Международной конференции (Минск, 20 ноября 2014 г.). – Минск : ОИПИ НАН Беларуси, 2014. — C. 265-269.
- Русак, В.П. Першы даведнік па культуры беларускага вымаўлення / В.П. Русак, В.А. Мандзік, Ю.С. Гецэвіч, С.І. Лысы // Весці Нацыянальнай акадэміі навук Беларусі. Серыя гуманітарных навук. – 2019. – Т. 64, № 1. – С. 69-80.
- Русак, В.П. Сучасная беларуская лексікаграфія: новы фармат / В.П. Русак, Ю.С. Гецэвіч // Слово и словарь = Vocabulum et vocabularium : сборник научных статей / редкол.: И.Л. Копылов (гл. ред.). – Минск : Беларуская навука, 2019. – C. 120-124.
- Русак, В.П. Праблемы нормы, культура мовы і генератар маўлення / В.П. Русак, Ю.С. Гецэвіч, С.І. Лысы, В.А. Мандзік // Зборнiк дакладаў i тэзiсаў VIII Міжнароднай навукова-практычнай канферэнцыі «Традыцыі і сучасны стан культуры і мастацтваў» (Мiнск, Беларусь, 7–8 верасня 2017 года) / Цэнтр даследаванняў беларускай культуры, мовы і літаратуры НАН Беларусі ; гал. рэд. А. І. Лакотка. — Мінск : Права і эканоміка, 2018. — C. 748-752.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.
- Лысы С.І. Генерацыя нацыянальнай транскрыпцыі тэкстаў на беларускай мове / С.І. Лысы, Ю.С. Гецэвіч // Інфарматыка. — 2017. — №54. — C. 84-92.