The «Grammatical Dictionary Processor» service allows the user to receive previously loaded and converted to the required format lexicographic data of the grammar dictionary in the form of an HTML table, and to receive SQL instructions for creating a database that contains the entered information in a structured form.
Basic terms and concepts
Parsing (or syntactic analysis) – in linguistics and computer science – the process of comparing a linear sequence of lexical units (words, tokens) of a natural or formal language with its formal grammar. In terms of the work of this service, the input of textual data is parsed according to the parsing patterns of the user-specified part of speech.
HTML table – a sequence of data and tags enclosed in the body of the <table> tag. The structure of the HTML table is described by the tags <th>, <td>, <tr>.
SQL (Structured Query Language) – a declarative programming language that is used to create, modify and manage data in a relational database supported by the corresponding database management system.
Practical value
Many text analysis-oriented systems need extensive and well-structured vocabulary databases – for example, automatic annotation and abstracting systems, systems of market analysis, legal linguistic examination. In addition, the vocabulary base can become the basis of commercial products – such as, for example, programs designed to help the user improve the grammar of the text he or she wrote, or popular now entertainment applications that offer word games to the user. Filling such vocabulary databases (and especially filling grammatical dictionaries) is a very time-consuming and painstaking process. The «Grammatical Dictionary Processor» service is designed to simplify and automate this process in the case of working with Belarusian-language data and, thus, the service devotes to provide additional support to strengthen the position of the Belarusian language in the electronic space.
The results of the «Grammatical Dictionary Processor» service were repeatedly applied in other services of the Corpus.by platform. The implementation results appeared to be satisfactory.
Service features
The service processes texts only in Belarusian, taking into account the grammatical and accentological features of the language (in particular, the letters «о» and «ё» are automatically marked by the service as accented). The user may try to process the data written in another language, but the result of such action is likely to be unsatisfactory.
The processing of text data by the service is fully adapted to a specific format. Grammatical information in such format is presented in the following lexicographic publications:
- Граматычны слоўнік назоўніка. Менск: Беларуская навука, 2013. ISBN 978-985-08-1559-0
- Граматычны слоўнік назоўніка. Менск: Беларуская навука, 2008. ISBN 978-985-08-0955-1
- Граматычны слоўнік дзеяслова. Менск: Беларуская навука, 2007. ISBN 978-985-0842-4
- Граматычны слоўнік дзеяслова. Менск: Беларуская навука, 2013. ISBN 978-985-08-1518-7
- Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя. Менск: Беларуская навука, 2009. ISBN 978-985-08-1114-1
- Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя. Менск: Беларуская навука, 2013. ISBN 978-985-08-1629-0
If the user wants to process his own lexicographic data correctly, he needs to bring them into line with the format. Please note that in the vast majority of cases accents in word forms should be marked before processing.
Service operation algorithm
Basic algorithm
- Algorithm input data:
- User text input, Text;
- User selection of processing template, Template. May take the values Noun, Adjective, Numeral, Pronoun, Verb, Adverb;
- An empty associative array of word forms, Wordforms;
- An empty variable to create a table, Table;
- An empty variable for writing SQL instructions, Sql;
- An empty variable for recording errors, Errors;
- 6 classes for processing text input and creating an associative array for the subsequent formation of HTML table and SQL instructions, Processors. Each class inherits the functions of the main class of the program and is designed to process its own part of speech.
The beginning of the algorithm.
Step 1.1. Loading PHP files containing classes for processing (Processors).
Step 1.2. Checking condition Text = ∅. If the condition is true, implement the formation of a record about this in the final table, making the issuance of information to the user and finish the algorithm. If the condition is false, go to the next step.
Step 1.3. Formation of the database name created by the resulting SQL instructions (dictionaryName) according to the value of Template.
Step 1.4. Creating an object of the user input Text handler class (Processor) according to the value of Template.
Step 2.1. Recording of initial tags for creating an HTML table into the Table variable.
Step 2.2. Recording the initial instructions for creating the database table to the Sql variable.
Step 3.1. Creating a ParagraphsArr array. Filling the array with Paragraph elements obtained by dividing Text into separate paragraphs by line feed character. Creating of a Cnt variable for subsequent calculation of the number of processed Paragraph. Creating a variable Id = 0 for the subsequent recording of the initial number of the word form.
Step 3.2. For each Paragraph in ParagraphsArr, perform steps 3.2.1. – 3.2.9.
Step 3.2.1. Clear the contents of Paragraph from initial and last spaces.
Step 3.2.2. If Paragraph = ∅, go to the next paragraph and step 3.2.1.
Step 3.2.3. Increment Cnt.
Step 3.2.4. Create an empty array for subsequent storage of parsed Paragraph data.
Step 3.2.5. Parsing the current Paragraph using the required Processor method, depending on the value of Template. Write the name of the Template to the Pos variable.
Step 3.2.6. Creating an Initial variable to store the number of the first word form from Wordforms, initializing the Initial variable with the current value of the Id variable.
Step 3.2.7. If Wordforms = ∅, add to Errors the line «Не выдзелена ніводнай словаформы ў радку: $paragraph<br>», otherwise – perform steps 3.2.8 – 3.2.9.
Step 3.2.8. Generate the next entry in the HTML table – perform steps 3.2.8.1 – 3.2.8.4.
Step 3.2.8.1. Create an Id2 variable and initialize it with the current Initial value.
Step 3.2.8.2. Create a variable Cnt2 and initialize it with the number of Wordforms elements.
Step 3.2.8.3. For each Wordform in Wordforms, perform steps 3.2.8.3.1 – 3.2.8.3.8.
Step 3.2.8.3.1. Create a Result variable to record the results of creating the current table entry, initializing the Result by the value «<tr>».
Step 3.2.8.3.2. Replace the secondary accent characters in Wordform with the «=» character, and the primary accent characters with the «+» character.
Step 3.2.8.3.3. Create an Accent variable. If the «+» symbol is missing in Wordform, perform steps 3.2.8.3.3.1 – 3.2.8.3.3.3; otherwise, initialize Accent with the current Wordform value and go to step 3.2.8.3.4.
Step 3.2.8.3.3.1. If only one vowel of the Belarusian alphabet is found in Wordform, replace this vowel with the combination [vowel + «+»] and assign the resulting combination of characters to the variable Accent, having previously removed any indentation characters from it, otherwise go to step 3.2.8.3.3.2.
Step 3.2.8.3.3.2. If the word contains the letter «о» or «ё», perform steps 3.2.8.3.3.2.1 – 3.2.8.3.3.2.3, otherwise go to step 3.2.8.3.3.3.
Step 3.2.8.3.3.2.1. Create a Chars array and sequentially record into it all the characters that Wordform consists of. Create a Position variable for subsequent recording of the position of the found symbol.
Step 3.2.8.3.3.2.2. Iterate over all elements of the Chars array sequentially. If any element is equal to «о» or «ё», record its number to the Position variable.
Step 3.2.8.3.3.2.3. Insert the «+» symbol in Wordform between the symbol under the Position number and the symbol under the Position + 1 number. If at the same time a combination of characters «+=» was formed somewhere in Wordform, add the message ««+=» Error in word $word<br>» to Errors, replace the combination of characters «+= »with the character «+». Assign the resulting Wordform to the Accent variable after removing all indent characters from Wordform.
Step 3.2.8.3.3.3. If none of the conditions described in steps 3.2.8.3.3.1 and 3.2.8.3.3.2 are implemented, set Accent to false.
Step 3.2.8.3.4. If Accent = false, add the line «Немагчыма вызначыць націск у слове <b>$wordform</b>: $paragraph<br>» to Errors.
Step 3.2.8.3.5. Discard initial and last spaces in the variable Accent.
Step 3.2.8.3.6. Create a Word variable and record the value of the Accent variable with the removed characters «+» and «=» into it.
Step 3.2.8.3.7. If Id2 = Initial, fill up Result with the string «<td>$id</td><td>$initial</td><td>$word</td><td>$accent</td><td>$pos</td><td rowspan=$cnt>$paragraph</td>», otherwise – fill up Result with the string «<td>$id</td><td>$initial</td><td>$word</td><td>$accent</td><td>$pos</td>».
Step 3.2.8.3.8. Fill up Result with the string «</tr>» and increment Id2.
Step 3.2.8.4. Supplement Table with Result.
Step 3.2.9. Generate further SQL instruction – perform steps 3.2.9.1. – 3.2.9.3.
Step 3.2.9.1. Create an Id3 variable and assign it the value of the Initial variable. Create a Pos2 variable and assign it the value of the Pos variable enclosed in single quotes («’»). Create an empty variable Result2 for the subsequent record of the resulting instruction.
Step 3.2.9.2. For each Wordform in Wordforms, perform steps 3.2.9.2.1 – 3.2.9.2.7.
Step 3.2.9.2.1. Replace in Wordform all the characters of the secondary accent with the symbol «=», all the symbols of the main accent with the symbol «+». Create the Accent variable. If no accent characters are found in Wordform, perform actions similar to the actions described in steps 3.2.8.3.3.1. – 3.2.8.3.3.3; otherwise, set Accent to Wordform.
Step 3.2.9.2.2. If Accent = false, fill up Errors with the line «Немагчыма вызначыць націск у слове <b>$wordform</b>: $paragraph<br>».
Step 3.2.9.2.3. Replace all «’» characters with «”» in Accent, delete initial and last spaces in Accent, and enclose the text of Accent in single quotation marks («’»). Create a Word variable and record the Accent string value with the removed characters «=» and «+» into it. Create an Entry variable and record the Paragraph variable value enclosed in single quotes into it, all the «’» characters in Paragraph should be replaced with «”».
Step 3.2.9.2.4. If Id3 can be divided by 10000 leaving no remainder, fill up Result2 with the string «\nINSERT INTO `$dictionaryName` (`id`, `initial`, `word`, `accent`, `pos`, `entry`) VALUES\n».
Step 3.2.9.2.5. If Id3 is not equal to Initial, set Entry to «”».
Step 3.2.9.2.6. If the remainder of dividing Id3 by 10000 is 9999, fill up Result2 with the string «($id, $initial, $word, $accent, $pos, $entry);\n», иначе – дополнить Result2 строкой «($id, $initial, $word, $accent, $pos, $entry),\n».
Step 3.2.9.2.7. Increment Id3.
Step 3.2.9.3. Supplement Sql with Result2.
Step 3.3 Supplement Table with the string «</tbody></table>». Supplement Sql with the string «($id, $id, ”, ”, ”);».
Step 4. Present the contents of Table to the user in the form of the output of the table on the screen and a separate text file, perform to the user the value of the variable Cnt (the number of processed words), and the contents of Sql as a separate text file.
The end of the algorithm.
Nouns parsing algorithm.
Algorithm input data:
- Text data in a special format, Str;
- List of exceptions; Exceptions;
- A list of formatted text data correlating with Exceptions, ExceptionsMatches;
- Variable for recording errors, Errors.
The beginning of the algorithm.
Step 1.1. Creating the variable Br and initializing it with the value «<br>\n». Creating the Wordforms array.
Step 1.2. Checking if Str contains at least one space. If not, fill up Errors with the line «Аніводнага прабела ў запісе: $str<br>».
Step 1.3. Checking whether Str belongs to the Exceptions exception list. If so, select the appropriate ExceptionsMatches element, write it in Wordforms, assign Wordforms to the variable for which the method was called, and finish the algorithm. If not, go to the next step.
Step 2.1. Creating a Pos variable and recording to it the position of the first space encountered in Str. Creating a Headword variable and recording the Str substring that consists of all characters up to the Pos position into it.
Step 2.2. If the last character of the Headword is a digit, delete this character.
Step 2.3. Create an Entry variable and record all the Str characters in the position after Pos into it sequentially.
Step 2.4. If Entry starts with a sequence of «і» character and a space, delete these characters from Entry, change the Pos value to the position of the first space in Entry, create the Headword2 variable and record into it all Entry characters before the Pos position, then overwrite Entry deleting everything that is before the Pos position.
Step 2.5. If Entry begins with the combinations of characters «м., толькі ў выразе: », «ж., толькі ў выразе: », «н., толькі ў выразе: », «мн., толькі ў выразе: », record Headword in Wordforms . If the Headwords2 variable is created and initialized, write it in Wordforms as well. Return the result to the part of the program where the function was called and finish the algorithm.
Step 3.1. Creating the Paradigms array and recording Entry parts delimited by the separator «; (» into it. Creating a Cnt variable and initializing it with the number of Paradigms elements.
Step 3.2. Add a «(» symbol at the beginning to each Paradigms element.
Step 3.3. For each Paradigms element, perform steps 3.3.1 – 3.3.8.
Step 3.3.1. Creating a subEntry variable and writing the current Paradigms element to it. Turning the current Paradigms element into an array of characters.
Step 3.3.2. Extracting of semantics. If the first subEntry character is «(», initialize Pos with the position of the first occurrence of the character «)» in subEntry, add the Semantics associative element to the current Paradigms element; this associative element is equal to the combination of characters from the first character «(» to the first character «)» (not including these characters) and remove from subEntry all the characters before the position Pos+2. If not, add a Semantics associative element equal to «unknown» to the current Paradigms element.
Step 3.3.3.1. Processing non-declining nouns (1). If subEntry is «м., нескл.», «ж., нескл.», «н., нескл.», «мн., нескл.», add the Headword value to Wordforms, add an associative element [‘paradigm’][X] to the current Paradigms element, where X is equal to NMN1, NFN1, NNN1 or NPN1 (respectively for masculine, feminine, neuter and pluralia tantum nouns); the element [‘paradigm’][X] is equal to Headword. If at the same time the Headword2 variable is set, add the Headword value to Wordforms, add the associative element [‘paradigm’][Y] to the current Paradigms element, where Y is NMN2, NFN2, NNN2 or NPN2 (respectively for masculine, feminine, neuter and nouns pluralia tantum); the element [‘paradigm’][Y] is equal to Headword2. Assign Wordforms to the variable for which the method was called, and finish the algorithm.
Step 3.3.3.2. Processing non-declining nouns (2). If subEntry is «н. і ж., нескл.», «м. і н., нескл.», «м. і ж., нескл.», add the Headword value to Wordforms, add the associative element [‘paradigm’][X] to the current Paradigms element, where X is equal to NMN1 or NNN1 (respectively for masculine and neuter nouns), and the element [‘paradigm’][Y], where Y is equal to NFN1 or NNN1 (respectively for feminine and neuter nouns); both the [‘paradigm’][X] element and the [‘paradigm’][Y] element are equal to Headword. If at the same time the variable Headword2 is set, add the value Headword2 to Wordforms, add the associative element [‘paradigm’][X] to the current Paradigms element, where X is equal either to NMN2 or NNN2 (respectively for masculine and neuter nouns), as well as the element [‘paradigm’][Y], where Y is equal to NFN2 or NNN2 (respectively for feminine and neuter nouns); both the element [‘paradigm’][X] and the element [‘paradigm’][Y] is equal to Headword2. Assign Wordforms to the variable for which the method was called, and finish the algorithm.
Step 3.3.4. Create an associative [paradigm] element for the current Paradigms element. The [paradigm] element is an associative array in which each cell corresponds to a specific gender form or plural form in a specific case.
Step 3.3.5. Creating the variable bothGender = false. If subEntry begins with the character combination «м. і ж., », make bothGender equal to true and remove the given combination of characters from subEntry.
Step 3.3.6. The division of the paradigm into fragments of the same gender and number («sixes»). Creating the subSubEntryArr array and filling it with subEntry parts delimited by the separator «; ». If the number of subSubEntryArr elements is less than or equal to 2 and bothGender = true, add to Errors the string «Некарэктны запіс для агульнага роду: $str<br>», return false to the method call point and finish the algorithm. If the number of elements of subSubEntryArr is more than 2 and bothGender = false, add to Errors the string «Зашмат кропак з коскамі пры звычайных умовах: $str<br>», return false to the method call point and finish the algorithm.
Step 3.3.7. For each subSubEntry in subSubEntryArr, perform steps 3.3.7.1. – 3.3.7.3.
Step 3.3.7.1. Creating a Gender variable and initializing it with an empty set. If subSubEntry begins with «м. », «ж. », «н. », «мн. », «мн. для абодвух », «толькі мн.», assign Gender the value «M», «F», «N» or «P» for the last three cases respectively, and delete the initial character combinations from subSubEntry. If subSubEntry does not start with any of these character combinations, add to Errors the string «Незразумелыя лікі і роды ў выразе ‘<i>$subSubEntry</i>'<br>», return false to the call point of the method and finish the algorithm.
Step 3.3.7.2. Creating an associative array caseArr and initializing it in the following way: ‘Н‘ => 0, ‘Р‘ => 0, ‘Д‘ => 0, ‘В‘ => 0, ‘Т‘ => 0, ‘М‘ => 0. Creating an associative array caseTags and initializing in the following way: ‘Н‘ => ‘N’, ‘Р‘ => ‘G’, ‘Д‘ => ‘D’, ‘В‘ => ‘A’, ‘Т‘ => ‘I’, ‘М‘ => ‘P’. Creating the variable casesCnt = 0. Creating a tmp array and filling it with subSubEntry parts delimited by the separator «, ».
Step 3.3.7.3. For each wordform element in the tmp array, perform step 3.3.7.3.1.
Step 3.3.7.3.1. Creating a match array. An attempt to fill this array with wordform parts corresponding to the regular expression /[НРДВТМ]{1,6} /, and the zero element of the array must contain the part of the string corresponding to the occurrence of the entire template, and all subsequent elements should be the parts of the string that correspond to submasks. If this operation was completed, perform steps 3.3.7.3.1.1. – 3.3.7.3.1.3. If not, go to step 3.3.7.3.2.
Step 3.3.7.3.1.1. Initialization of Pos with length of string match[0]. Creating the variable cases and initializing it with a combination of all characters of match[0], except the last character. Initialization of Wordform by a combination of all characters of the current Wordform value before the Pos position. Creating the chars array and initializing it with the symbols that make up cases.
Step 3.3.7.3.1.2. For each char in the chars array, perform step 3.3.7.3.1.2.1.
Step 3.3.7.3.1.2.1. If the char element is present in caseArr, perform steps 3.3.7.3.1.2.1.1. – 3.3.7.3.1.2.1.4., otherwise add to Errors the string «У слоўнікавым артыкуле №$i некарэктны тэг ” . $cases . ‘.’ . $br;», return false to the point in the program where the method was called, and finish the algorithm.
Step 3.3.7.3.1.2.1.1. Initializing the element of the caseArr array corresponding to char with a value of 1.
Step 3.3.7.3.1.2.1.2. Creating the variants array and its initialization – the execution of steps 3.3.7.3.1.2.1.2.1. – 3.3.7.3.1.2.1.2.2.
Step 3.3.7.3.1.2.1.2.1. Creating an empty Wordforms2 array.
Step 3.3.7.3.1.2.1.2.2. If Wordform has a combination of characters «пробел+(», perform steps 3.3.7.3.1.2.1.2.2.1. – 3.3.7.3.1.2.1.2.2.5. Otherwise, initialize Wordforms2 with the value of Wordform.
Step 3.3.7.3.1.2.1.2.2.1. Initialization of Pos by the position of the first occurrence of the combination of characters «пробел+(» in Wordform.
Step 3.3.7.3.1.2.1.2.2.2. Create the wordform1 variable and initialize it with all Wordform characters before the Pos position. Creating the wordform2 variable and initializing it with all Wordform characters after the Pos position.
Step 3.3.7.3.1.2.1.2.2.3. If the vowel letter of the Belarusian alphabet occurs exactly once in wordform1, and there is no accent symbol, replace this vowel letter with the same vowel letter, but with an accent symbol.
Step 3.3.7.3.1.2.1.2.2.4. Add wordform1 to Wordforms2.
Step 3.3.7.3.1.2.1.2.2.5. If wordform2 begins with a combination of characters «(-», perform steps 3.3.7.3.1.2.1.2.2.5.1. – 3.3.7.3.1.2.1.2.2.5.6. Otherwise, if wordform2 begins with a character «(», add wordform2 with removed initial and last brackets in Wordforms2.
Step 3.3.7.3.1.2.1.2.2.5.1. Remove from wordform2 the initial combination of characters «(-» and the ending character.
Step 3.3.7.3.1.2.1.2.2.5.2. Create a letter variable and add the first wordform2 character to it.
Step 3.3.7.3.1.2.1.2.2.5.3. Creating the rpos variable and initializing it with the position of the last occurrence of letter in wordform1.
Step 3.3.7.3.1.2.1.2.2.5.4. Reinitialization of a wordform2 variable by concatenating a combination of wordform1 characters before the position rpos and the current value of wordform2.
Step 3.3.7.3.1.2.1.2.2.5.5. If there are more accent characters in wordform2 than in wordform1, add to Errors the string «Пры расшыфроўцы скарачэньня $wordform узніклі лішнія націскі<br>».
Step 3.3.7.3.1.2.1.2.2.5.6. Add wordform2 to Wordforms2.
Step 3.3.7.3.1.2.1.3. For k=0; k < [number of variants elements], k++ perform step 3.3.7.3.1.2.1.3.1.
Step 3.3.7.3.1.2.1.3.1. If variants[k] is specified, perform steps 3.3.7.3.1.2.1.3.1.1. – 3.3.7.3.1.2.1.3.1.3.
Step 3.3.7.3.1.2.1.3.1.1. The initialization of the tag variable by concatenation of the string «N», the Gender value, the caseTags element that corresponds to char, and the string value of k+1.
Step 3.3.7.3.1.2.1.3.1.2. Initialization of the associative element of the current paradigm [‘paradigm’][tag] element with the variants[k] value.
Step 3.3.7.3.1.2.1.3.1.3. Adding the value of variants[k] in Wordforms.
Step 3.3.7.3.1.2.1.4. Increment casesCnt.
Step 3.3.7.3.1.3. If caseArr [‘H’] = 0, perform steps 3.3.7.3.1.3.1. – 3.3.7.3.1.3.4.
Step 3.3.7.3.1.3.1. Initialize caseArr [‘H’] with a value of 1.
Step 3.3.7.3.1.3.2. Initialize the tag by concatenation of the string «N», the value of the Gender, and the string «N».
Step 3.3.7.3.1.3.3. Set the associative element of the current element Paradigm [[‘paradigm’][$tag. ‘1’]] equal to Headword and add Headword in Wordforms. If Headword2 is specified, set the associative element of the current element. Paradigm [[‘paradigm’][$tag . ‘2’]] equal to Headword and add Headword2 in Wordforms.
Step 3.3.7.3.1.3.4. Increment casesCnt.
Step 3.3.7.3.2. If the operation specified in step 3.3.7.3.1. is failed to implement, for each case element in caseArr, record the sequence number of the case into the variable v and perform step 3.3.7.3.2.1.
Step 3.3.7.3.2.1. If v = 0, and the condition <case = «Н» and the Gender is not equal to «P»> is incorrect, perform steps 3.3.7.3.2.1.1. – 3.3.7.3.2.1.4., otherwise go to the next case element and perform step 3.3.7.3.2.1. once again.
Step 3.3.7.3.2.1.1. Make the variable v equal to 1.
Step 3.3.7.3.2.1.2. Creating the variants array and initializing it in the same way as it was specified in steps 3.3.7.3.1.2.1.2.1. – 3.3.7.3.1.2.1.2.2.
Step 3.3.7.3.2.1.3. For k=0; k < [number of variant elements], k++ perform step 3.3.7.3.2.1.3.1.
Step 3.3.7.3.2.1.3.1. If variants[k] is specified, perform steps 3.3.7.3.2.1.3.1.1. – 3.3.7.3.2.1.3.1.3.
Step 3.3.7.3.2.1.3.1.1. Initialization of the tag by concatenation of the string «N», the Gender value, the caseTags [case] value, and the numerical value of k+1.
Step 3.3.7.3.2.1.3.1.2. Adding an associative element [‘paradigm’][tag] equal to variants[k] to the current Paradigms element.
Step 3.3.7.3.2.1.3.1.3. Adding variants[k] to Wordforms.
Step 3.3.7.3.2.1.4. Increment casesCnt and end the search that started in step 3.3.7.3.2.1.
Step 3.3.8. If casesCnt is not equal to 6 or 12, add to Errors the string «$casesCnt слоў у парадыгме ‘<b><i>$subSubEntry</i></b>’, а не 6 і не 12<br>», return false to the method call point and finish the algorithm.
Step 4. Return Wordforms to the method call point and finish the algorithm.
The end of the algorithm.
Adjectives parsing algorithm.
- Text data in a special format, Str;
- List of exceptions; Exceptions;
- A list of formatted text data that correlates with Exceptions, ExceptionsMatches;
- Variable for recording errors, Errors.
The beginning of the algorithm.
Step 1.1. Create an empty array Wordforms.
Step 1.2. Checking for presence of spaces in Str. If no spaces are found, add to Errors the string «Аніводнага прабела ў запісе: $str<br>», return an empty array and finish the algorithm. Otherwise, go to the next step.
Step 2.1. Creating a Pos variable and recording the position of the first space in Str into it.
Step 2.2. If the first character before the Pos position is the «:» character, check Str for correspondence with Exceptions – words that are found only in some expressions. If this correspondence is established, select the correlating element from ExceptionMatches, record it in Wordforms, return Wordforms to the method call point and finish the algorithm. Otherwise, go to the next step.
Step 2.3. Create Singular and Plural variables and initialize them with an empty string.
Step 2.4. If the combination of characters «; мн. » is not presented in Str, check Str for correspondence with Exceptions elements. If a match is found among words that don’t have a singular form, write the desired value in the Plural variable. If the match is found in another section of Exceptions (among the strings for the words «кайназо́йскі», «эазо́йскі», «эалі́тавы», «ю́рскі»), record the value of Str in the Singular variable. If the combination of «; мн. » is presented in Str, split Str by delimiter «; мн. » and record the first part (if any) to the Singular variable, the second part (if any) to the Plural variable.
(further steps of the algorithm are under construction)
Numbers parsing algorithm.
Algorithm is under construction.
Pronouns parsing algorithm.
Algorithm is under construction.
Verbs parsing algorithm.
Algorithm is under construction.
Adverbs parsing algorithm.
Algorithm is under construction.
User interface description
The appearance of the service user interface is shown in Figure 1.
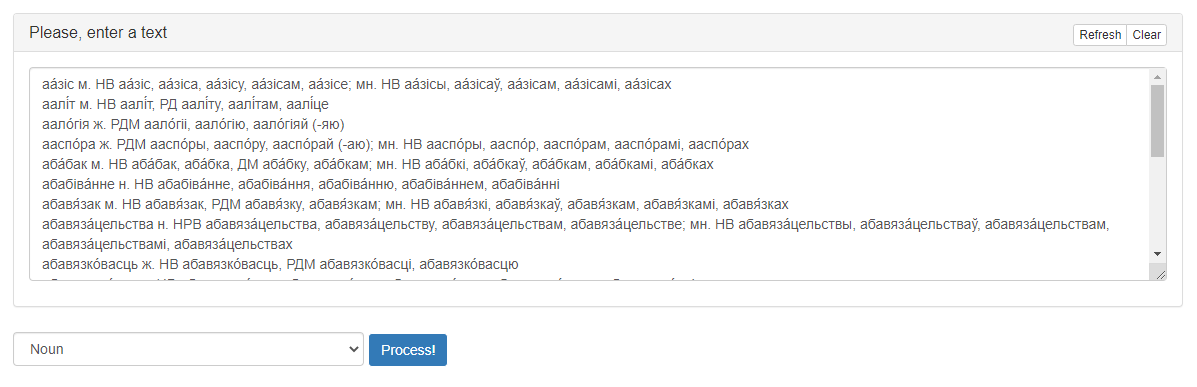
Figure 1 – The graphical interface of the service «Grammatical Dictionary Processor»
The interface contains the following areas:
- A field for entering text in a special format. Equipped with the buttons «Refresh» (return data by default) and «Clear» (delete all data);
- Drop-down menu for selecting a processing template. It has the clauses «Noun», «Adjective», «Numeral», «Pronoun», «Verb», «Adverb»;
- The «Process!» button, which starts processing and allows to get results.
After clicking the «Process!» button, the following areas appear at the bottom of the screen (see Figure 2):
- Text information with data about the number of processed dictionary articles and links to download text files with an HTML table and SQL instructions;
- The «Errors» area for displaying information about errors that occurred during processing (appears if errors actually occurred);
- Area of delivery of results.
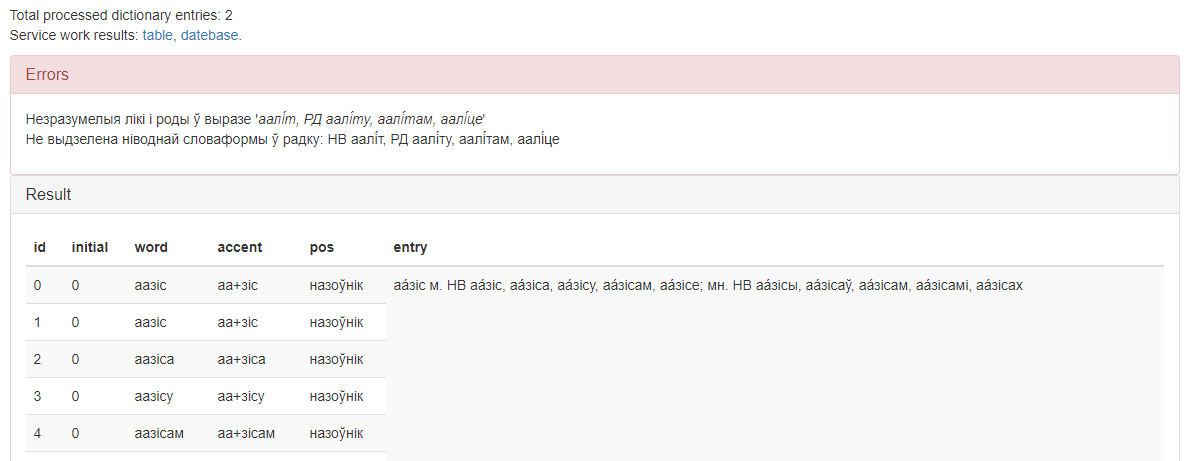
Figure 2 – The graphical interface of the service «Grammatical Dictionary Processor» – areas that appear after clicking on the button «Process!»
User scenarios of work with the service
Scenario 1. Obtaining a grammar dictionary in the form of an HTML table.
- Enter the data in the correct text format in the input field.
- Select the required processing template.
- Click the “Process!” button.
- View the processing results and possible errors; if necessary, correct the errors and click the «Process!» button once again.
- Click on the «table» hyperlink and save the HTML code that has appeared in a new window.
The possible result of the service work according to this scenario is presented in Figure 3.

Figure 3 – The result of the service work according to the scenario №1
Scenario 2. Obtaining SQL instructions for creating a grammar dictionary database.
- Enter the data in the correct text format in the input field.
- Select the required processing template.
- Click the “Process!” button.
- View the processing results and possible errors; if necessary, correct the errors and click the «Process!» button once again.
- Click on the “database” hyperlink and save the SQL instructions that appeared in a new window.
The possible result of the service work according to this scenario is presented in Figure 4.
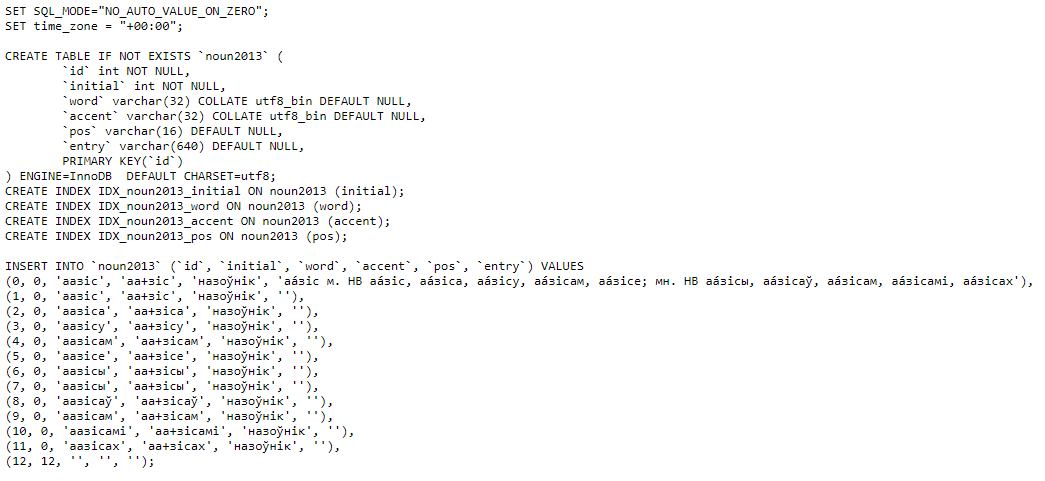
Figure 4 – The result of the service work according to the scenario №2
Regardless of the implemented scenario, the results of the service work will also be presented in the form of a table in the main window of the service (Figure 5).
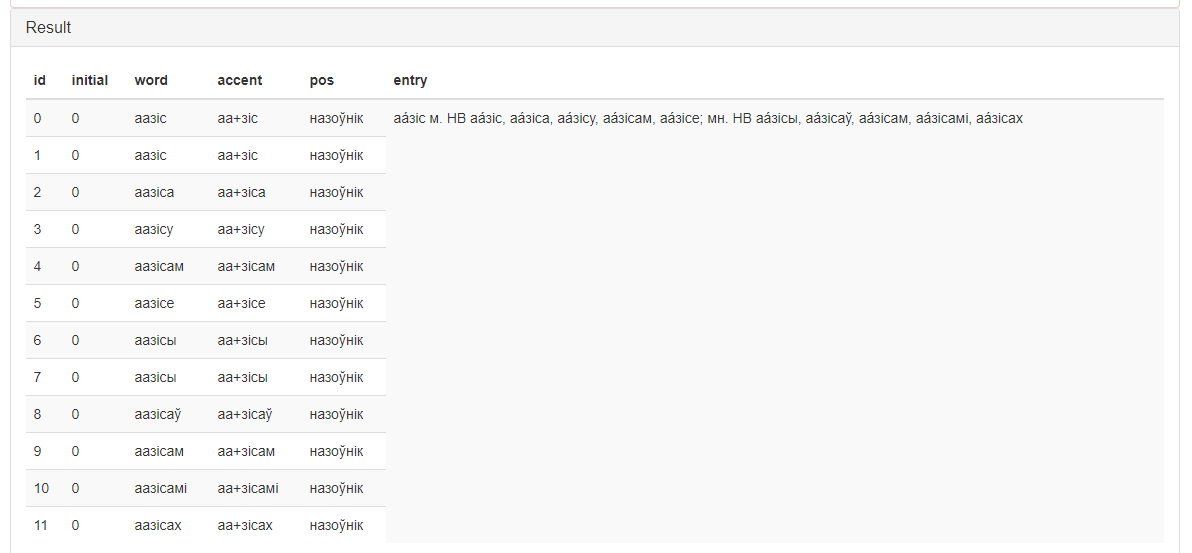
Figure 5 – The work result of the service «Grammatical Dictionary Processor»
Access to the service via the API
To access the service via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/GrammaticalDictionaryProcessor/api.php. The following parameters are passed through the data array:
- localization – localization language. Defines the language of the headers of the result table;
- text – text data in the necessary format;
- pos – type of processing templates. The parameter can take the following values:
- noun – processing according to the noun processing patterns;
- adjective – processing according to the adjective processing templates;
- numeral – processing according to the numeral processing patterns;
- pronoun – processing according to the pronoun processing templates;
- verb – processing according to the verb processing patterns;
- adverb – processing according to the adverb processing templates.
Example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/GrammaticalDictionaryProcessor/api.php”,
data:{
“localization”: “en”
“text”: “аа́зіс м. НВ аа́зіс, аа́зіса, аа́зісу, аа́зісам, аа́зісе; мн. НВ аа́зісы, аа́зісаў, аа́зісам, аа́зісамі, аа́зісах”,
“pos”: “noun”
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with the original test (text parameter), the final table (table parameter), the final instructions for creating the database using SQL tools (sql parameter), a link for a text file with the code of the HTML table (tableUrl parameter), a link for a text file with SQL instructions (sqlUrl parameter), the total number of processed dictionary entries (cnt parameter) and a list of errors (errors parameter). For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “аа́зіс м. НВ аа́зіс, аа́зіса, аа́зісу, аа́зісам, аа́зісе; мн. НВ аа́зісы, аа́зісаў, аа́зісам, аа́зісамі, аа́зісах”,
“table”: “<table id=”resultTableId” class=”table table-sm table-striped”><thead><tr><th scope=”col”>id</th><th scope=”col”>initial</th><th scope=”col”>word</th><th scope=”col”>accent</th><th scope=”col”>pos</th><th scope=”col”>entry</th></thead><tbody><tr><td>0</td><td>0</td><td>аазіс</td><td>аа+зіс</td><td>назоўнік</td><td rowspan=12>аа́зіс м. НВ аа́зіс, аа́зіса, аа́зісу, аа́зісам, аа́зісе; мн. НВ аа́зісы, аа́зісаў, аа́зісам, аа́зісамі, аа́зісах</td></tr><tr><td>1</td><td>0</td><td>аазіс</td><td>аа+зіс</td><td>назоўнік</td></tr><tr><td>2</td><td>0</td><td>аазіса</td><td>аа+зіса</td><td>назоўнік</td></tr><tr><td>3</td><td>0</td><td>аазісу</td><td>аа+зісу</td><td>назоўнік</td></tr><tr><td>4</td><td>0</td><td>аазісам</td><td>аа+зісам</td><td>назоўнік</td></tr><tr><td>5</td><td>0</td><td>аазісе</td><td>аа+зісе</td><td>назоўнік</td></tr><tr><td>6</td><td>0</td><td>аазісы</td><td>аа+зісы</td><td>назоўнік</td></tr><tr><td>7</td><td>0</td><td>аазісы</td><td>аа+зісы</td><td>назоўнік</td></tr><tr><td>8</td><td>0</td><td>аазісаў</td><td>аа+зісаў</td><td>назоўнік</td></tr><tr><td>9</td><td>0</td><td>аазісам</td><td>аа+зісам</td><td>назоўнік</td></tr><tr><td>10</td><td>0</td><td>аазісамі</td><td>аа+зісамі</td><td>назоўнік</td></tr><tr><td>11</td><td>0</td><td>аазісах</td><td>аа+зісах</td><td>назоўнік</td></tr></tbody></table>”,
“sql”: “SET SQL_MODE=”NO_AUTO_VALUE_ON_ZERO”;
SET time_zone = “+00:00”;
CREATE TABLE IF NOT EXISTS `noun2013` (
`id` int NOT NULL,
`initial` int NOT NULL,
`word` varchar(32) COLLATE utf8_bin DEFAULT NULL,
`accent` varchar(32) COLLATE utf8_bin DEFAULT NULL,
`pos` varchar(16) DEFAULT NULL,
`entry` varchar(640) DEFAULT NULL,
PRIMARY KEY(`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE INDEX IDX_noun2013_initial ON noun2013 (initial);
CREATE INDEX IDX_noun2013_word ON noun2013 (word);
CREATE INDEX IDX_noun2013_accent ON noun2013 (accent);
CREATE INDEX IDX_noun2013_pos ON noun2013 (pos);
INSERT INTO `noun2013` (`id`, `initial`, `word`, `accent`, `pos`, `entry`) VALUES
(0, 0, ‘аазіс’, ‘аа+зіс’, ‘назоўнік’, ‘аа́зіс м. НВ аа́зіс, аа́зіса, аа́зісу, аа́зісам, аа́зісе; мн. НВ аа́зісы, аа́зісаў, аа́зісам, аа́зісамі, аа́зісах’),
(1, 0, ‘аазіс’, ‘аа+зіс’, ‘назоўнік’, ”),
(2, 0, ‘аазіса’, ‘аа+зіса’, ‘назоўнік’, ”),
(3, 0, ‘аазісу’, ‘аа+зісу’, ‘назоўнік’, ”),
(4, 0, ‘аазісам’, ‘аа+зісам’, ‘назоўнік’, ”),
(5, 0, ‘аазісе’, ‘аа+зісе’, ‘назоўнік’, ”),
(6, 0, ‘аазісы’, ‘аа+зісы’, ‘назоўнік’, ”),
(7, 0, ‘аазісы’, ‘аа+зісы’, ‘назоўнік’, ”),
(8, 0, ‘аазісаў’, ‘аа+зісаў’, ‘назоўнік’, ”),
(9, 0, ‘аазісам’, ‘аа+зісам’, ‘назоўнік’, ”),
(10, 0, ‘аазісамі’, ‘аа+зісамі’, ‘назоўнік’, ”),
(11, 0, ‘аазісах’, ‘аа+зісах’, ‘назоўнік’, ”),
(12, 12, ”, ”, ”);”,
“tableUrl”: “..\/_cache\/GrammaticalDictionaryProcessor\/out\/2020-06-04_23-13-27_37-214-33-191_621_table_out.txt”,
“sqlUrl”: “..\/_cache\/GrammaticalDictionaryProcessor\/out\/2020-06-04_23-13-27_37-214-33-191_621_sql_out.txt”,
“cnt”: 1,
“errors”: “”
}
]
Source references
Service page – https://corpus.by/GrammaticalDictionaryProcessor/