Сэрвіс «Апрацоўка граматычнага слоўніка» дае магчымасць карыстальніку атрымаць у выглядзе HTML-табліцы папярэдне загружаныя і прыведзеныя да патрэбнага фармату лексікаграфічныя дадзеныя граматычнага слоўніка, а таксама атрымаць SQL-інструкцыі для стварэння базы дадзеных, якая змяшчае ўведзеную інфармацыю ў структурыраваным выглядзе.
Асноўныя тэрміны і паняцці
Парсінг (або сінтаксічны аналіз) – у лінгвістыцы і інфарматыцы – працэс супастаўлення лінейнай паслядоўнасці лексем (слоў, токенаў) натуральнай або фармальнай мовы з яе фармальнай граматыкай. У рамках працы дадзенага сэрвіса адбываецца разбор уведзеных тэкставых дадзеных згодна з шаблонамі разбору ўказанай карыстальнікам часціны мовы.
HTML-табліца – паслядоўнасць дадзеных і тэгаў, заключаных у цела тэга <table>. Структура HTML-табліцы апісваецца тэгамі <th>, <td>, <tr>.
SQL (англ. structured query language – «мова структураваных запытаў») – дэкларатыўная мова праграмавання, якая прымяняецца для стварэння, мадыфікацыі і кіравання дадзенымі ў рэляцыйнай базе дадзеных, якая падтрымліваецца адпаведнай сістэмай кіравання базамі дадзеных.
Практычная каштоўнасць
Вельмі многія сістэмы, арыентаваныя на тэкставы аналіз, патрабуюць вялікія і добра структураваныя слоўнікавыя базы – гэта, напрыклад, сістэмы аўтаматычнага анатавання і рэферавання, маркеталагічнага аналізу, прававой лінгвістычнай экспертызы. Акрамя таго, слоўнікавая база можа стаць асновай камерцыйных прадуктаў – такіх, напрыклад, як праграмы, прызначаныя дапамагчы карыстальніку ўдасканаліць граматыку напісанага ім тэксту, або папулярныя сёння забаўляльныя дадаткі, якія прапануюць карыстальніку славесныя гульні. Запаўненне падобных слоўнікавых баз (і ў асаблівасці запаўненне граматычных слоўнікаў) – працэс вельмі працаёмкі і карпатлівы. Сэрвіс «Апрацоўка граматычнага слоўніка» прызначаны спрасціць і аўтаматызаваць дадзены працэс у выпадку працы з беларускамоўнымі дадзенымі і, такім чынам, служыць дадатковай падтрымкай для ўмацавання пазіцый беларускай мовы ў электроннай прасторы.
Вынікі працы сэрвіса «Апрацоўка граматычнага слоўніка» былі неаднаразова прымененыя ў іншых сэрвісах платформы Corpus.by. Вынікі ўкаранення аказаліся здавальняючымі.
Асаблівасці сэрвіса
Сэрвіс апрацоўвае тэксты толькі на беларускай мове з улікам граматычных і акцэнталагічных асаблівасцей дадзенай мовы (у прыватнасці, літары «о» і «ё» аўтаматычна абазначаюцца сэрвісам як націскныя). Карыстальнік можа паспрабаваць апрацаваць дадзеныя на іншай мове, аднак вынік такога дзеяння, хутчэй за ўсё, будзе нездавальняючым.
Апрацоўка тэкставых дадзеных сэрвісам цалкам прыстасавана пад пэўны фармат. З дапамогай дадзенага фармату прадстаўлена граматычная інфармацыя ў наступных лексікаграфічных выданнях:
- Граматычны слоўнік назоўніка. Менск: Беларуская навука, 2013. ISBN 978-985-08-1559-0
- Граматычны слоўнік назоўніка. Менск: Беларуская навука, 2008. ISBN 978-985-08-0955-1
- Граматычны слоўнік дзеяслова. Менск: Беларуская навука, 2007. ISBN 978-985-0842-4
- Граматычны слоўнік дзеяслова. Менск: Беларуская навука, 2013. ISBN 978-985-08-1518-7
- Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя. Менск: Беларуская навука, 2009. ISBN 978-985-08-1114-1
- Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя. Менск: Беларуская навука, 2013. ISBN 978-985-08-1629-0
Калі карыстальнік жадае карэктна апрацаваць уласныя лексікаграфічныя дадзеныя, яму неабходна прывесці іх у адпаведнасць з фарматам. Звяртаем увагу, што ў пераважнай большасці выпадкаў націскі ў словаформах павінны быць расстаўленыя загадзя.
Алгарытм працы сэрвіса
Асноўны алгарытм
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, Text;
- Карыстальніцкі выбар шаблону апрацоўкі, Template. Можа прымаць значэнні Noun, Adjective, Numeral, Pronoun, Verb, Adverb;
- Пусты асацыятыўны масіў словаформ, Wordforms;
- Пустая пераменная для стварэння табліцы, Table;
- Пустая пераменная для запісу SQL–інструкцыі, Sql;
- Пустая пераменная для запісу памылак, Errors;
- 6 класаў для апрацоўкі тэкставага ўводу і стварэння асацыятыўнага масіву для наступнага фарміравання HTML–табліцы і SQL–інструкцый, Processors. Кожны клас наследуе функцыі галоўнага класа праграмы і прызначаны для апрацоўкі сваёй часціны мовы.
Пачатак алгарытму.
Крок 1.1. Загрузка PHP-файлаў, якія змяшчаюць класы-працэсары Processors.
Крок 1.2. Праверка ўмовы Text = ∅. Калі ўмова правільная, фарміраванне запісу пра гэта ў выніковую табліцу, выдача інфармацыі карыстальніку і завяршэнне алгарытму. Калі ўмова няправільная, пераход да наступнага кроку.
Крок 1.3. Фарміраванне назвы базы дадзеных, якая ствараецца выніковымі інструкцыямі SQL (dictionaryName) згодна са значэннем Template.
Крок 1.4. Стварэнне аб’екта класа-апрацоўшчыка карыстальніцага ўводу Text (Processor) згодна са значэннем Template.
Крок 2.1. Запіс пачатковых тэгаў для стварэння HTML-табліцы ў пераменную Table.
Крок 2.2. Запіс пачатковых інструкцый для стварэння табліцы базы дадзеных у пераменную Sql.
Крок 3.1. Стварэнне масіву ParagraphsArr. Запаўненне масіву элементамі Paragraph, атрыманымі шляхам раздзялення Text на асобныя параграфы паводле сімвала пераводу радка. Стварэнне пераменнай Cnt для наступнага падліку колькасці апрацаваных Paragraph. Стварэнне пераменнай Id = 0 для наступнага запісу пачатковага нумара словаформы.
Крок 3.2. Для кожнага Paragraph у ParagraphsArr выканаць крокі 3.2.1. – 3.2.9.
Крок 3.2.1. Ачышчэнне зместу Paragraph ад пачатковых і канечных прабелаў.
Крок 3.2.2. Калі Paragraph = ∅, перайсці да наступнага параграфа і кроку 3.2.1.
Крок 3.2.3. Інкрэментаваць Cnt.
Крок 3.2.4. Стварыць пусты масіў для наступнага захоўвання дадзеных Paragraph, якія падвергліся парсінгу.
Крок 3.2.5. Правесці парсінг бягучага Paragraph з дапамогай неабходнага метаду Processor, які залежыць ад значэння Template. Запісаць назву Template у пераменную Pos.
Крок 3.2.6. Стварэнне пераменнай Initial для захоўвання нумара першай словаформы з Wordforms, ініцыялізацыя пераменнай Initial бягучым значэннем пераменнай Id.
Крок 3.2.7. Калі Wordforms = ∅, дадаць да Errors радок «Не выдзелена ніводнай словаформы ў радку: $paragraph<br>», інакш – выканаць крокі 3.2.8 – 3.2.9.
Крок 3.2.8. Здзейсніць фарміраванне наступнага запісу ў HTML-табліцы – выканаць крокі 3.2.8.1 – 3.2.8.4.
Крок 3.2.8.1. Стварыць пераменную Id2 і ініцыялізаваць яе бягучым значэннем Initial.
Крок 3.2.8.2. Стварыць пераменную Cnt2 і ініцыялізаваць яе колькасцю элементаў Wordforms.
Крок 3.2.8.3. Для кожнай словаформы (Wordform) у Wordforms здзейсніць крокі 3.2.8.3.1 – 3.2.8.3.8.
Крок 3.2.8.3.1. Стварыць пераменную Result для запісу вынікаў стварэння бягучага запісу табліцы, ініцыялізацыя Result значэннем «<tr>».
Крок 3.2.8.3.2. Замяніць у Wordform сімвалы пабочнага націску на сімвал «=», сімвалы асноўнага націску – на сімвал «+».
Крок 3.2.8.3.3. Стварыць пераменную Accent. Калі ў Wordform адсутнічае сімвал «+», выканаць крокі 3.2.8.3.3.1 – 3.2.8.3.3.3, інакш – ініцыялізаваць Accent бягучым значэннем Wordform і перайсці да кроку 3.2.8.3.4.
Крок 3.2.8.3.3.1. Калі ў Wordform сустракаецца толькі адна галосная беларускага алфавіта, замяніць дадзеную галосную на спалучэнне [галосная+«+»] і прысвоіць атрыманую камбінацыю сімвалаў пераменнай Accent, папярэдне выдаліўшы з яе любыя сімвалы водступаў, інакш – перайсці да кроку 3.2.8.3.3.2.
Крок 3.2.8.3.3.2. Калі ў слове сустракаецца літара «о» або «ё», выканаць крокі 3.2.8.3.3.2.1 – 3.2.8.3.3.2.3, інакш – перайсці да кроку 3.2.8.3.3.3.
Крок 3.2.8.3.3.2.1. Стварыць масіў Chars і паслядоўна запісаць у яго ўсе сімвалы, з якіх складаецца Wordform. Стварыць пераменную Position для наступнага запісу пазіцыі знойдзенага сімвала.
Крок 3.2.8.3.3.2.2. Паслядоўна перабраць усе элементы масіву Chars. Калі які-небудзь элемент роўны «о» або «ё», запісаць яго нумар у пераменную Position.
Крок 3.2.8.3.3.2.3. Уставіць сімвал «+» у Wordform паміж сімвалам пад нумарам Position і сімвалам пад нумарам Position+1. Калі пры гэтым у Wordform дзе-небудзь утварылася камбінацыя сімвалаў «+=», дадаць у Errors паведамленне ««+=» Error in word $word<br>», замяніць камбінацыю сімвалаў «+=» на сімвал «+». Прысвоіць атрыманы Wordform пераменнай Accent, папярэдне выдаліўшы з Wordform усе сімвалы водступаў.
Крок 3.2.8.3.3.3. Калі не выканана ні адна з умоў, апісаных у кроках 3.2.8.3.3.1 і 3.2.8.3.3.2, прысвоіць Accent значэнне false.
Крок 3.2.8.3.4. Калі Accent = false, дапоўніць Errors радком «Немагчыма вызначыць націск у слове <b>$wordform</b>: $paragraph<br>».
Крок 3.2.8.3.5. Адкінуць пачатковыя і канцавыя прабелы ў пераменнай Accent.
Крок 3.2.8.3.6. Стварыць пераменную Word і запісаць у яе значэнне пераменнай Accent з выдаленымі сімваламі «+» і «=».
Крок 3.2.8.3.7. Калі Id2 = Initial, дапоўніць Result радком «<td>$id</td><td>$initial</td><td>$word</td><td>$accent</td><td>$pos</td><td rowspan=$cnt>$paragraph</td>», інакш – дапоўніць Result радком «<td>$id</td><td>$initial</td><td>$word</td><td>$accent</td><td>$pos</td>».
Крок 3.2.8.3.8. Дапоўніць Result радком «</tr>» і інкрэментаваць Id2.
Крок 3.2.8.4. Дапоўніць Table значэннем Result.
Крок 3.2.9. Здзейсніць фарміраванне наступнай SQL-інструкцыі – выканаць крокі 3.2.9.1. – 3.2.9.3.
Крок 3.2.9.1. Стварэнне пераменнай Id3 і прысваенне ёй значэння пераменнай Initial. Стварэнне пераменнай Pos2 і прысваенне ёй значэння пераменнай Pos, што знаходзіцца ў адзінарных двукоссях («’»). Стварэнне пустой пераменнай Result2 для наступнага запісу інструкцыі, што атрымалася.
Крок 3.2.9.2. Для кожнага Wordform у Wordforms выканаць крокі 3.2.9.2.1 – 3.2.9.2.7.
Крок 3.2.9.2.1. Замяніць у Wordform усе сімвалы пабочнага націску на сімвал «=», усе сімвалы асноўнага націску – на сімвал «+». Стварыць пераменную Accent. Калі ў Wordform не знойдзена ніводнага сімвала націску, ажыццявіць дзеянні, аналагічныя апісаным у кроках 3.2.8.3.3.1. – 3.2.8.3.3.3, інакш – прысвоіць Accent значэнне Wordform.
Крок 3.2.9.2.2. Калі Accent = false, дапоўніць Errors радком «Немагчыма вызначыць націск у слове <b>$wordform</b>: $paragraph<br>».
Крок 3.2.9.2.3. Замяніць у Accent усе сімвалы «’» на «”», выдаліць у Accent пачатковыя і канцавыя прабелы і заключыць тэкст Accent у адзінарныя двукоссі («’»). Стварыць пераменную Word і запісаць у яе радковае значэнне Accent з выдаленымі сімваламі «=» і «+». Стварыць пераменную Entry і запісаць у яе значэнне пераменнай Paragraph, заключанае ў адзінарныя двукоссі, пры гэтым усе сімвалы «’» у Paragraph павінны быць замененыя на «”».
Крок 3.2.9.2.4. Калі Id3 дзеліцца без астачы на 10000, дапоўніць Result2 радком «\nINSERT INTO `$dictionaryName` (`id`, `initial`, `word`, `accent`, `pos`, `entry`) VALUES\n».
Крок 3.2.9.2.5. Калі Id3 не роўнае Initial, прысвоіць Entry значэнне «”».
Крок 3.2.9.2.6. Калі астача ад дзялення Id3 на 10000 роўная 9999, дапоўніць Result2 радком «($id, $initial, $word, $accent, $pos, $entry);\n», інакш – дапоўніць Result2 радком «($id, $initial, $word, $accent, $pos, $entry),\n».
Крок 3.2.9.2.7. Інкрэментаваць Id3.
Крок 3.2.9.3. Дапоўніць Sql значэннем Result2.
Крок 3.3. Дапоўніць Table радком «</tbody></table>». Дапоўніць Sql радком «($id, $id, ”, ”, ”);».
Крок 4. Прадставіць карыстальніку змест Table у выглядзе вываду табліцы на экран і асобнага тэкставага файла, значэнне пераменный Cnt (колькасць апрацаваных слоў), а таксама змест Sql – у выглядзе асобнага тэкставага файла.
Канец алгарытму.
Алгарытм парсінгу назоўнікаў.
Уваходныя дадзеныя алгарытму:
- Тэкставыя дадзеныя ў спецыяльным фармаце, Str;
- Спіс выключэнняў, Exceptions;
- Спіс адфарматаваных тэкставых дадзеных, якія карэлююць з Exceptions, ExceptionsMatches;
- Пераменная для запісу памылак, Errors.
Пачатак алгарытму.
Крок 1.1. Стварэнне пераменнай Br і ініцыялізацыя яе значэннем «<br>\n». Стварэнне масіву Wordforms.
Крок 1.2. Праверка, ці змяшчаецца ў Str хаця б адзін прабел. Калі не, дапоўніць Errors радком «Аніводнага прабелу ў запісе: $str<br>».
Крок 1.3. Праверка, ці належыць Str да спісу выключэнняў Exceptions. Калі так, выбраць адпаведны элемент ExceptionsMatches, запісаць яго ў Wordforms, прысвоіць Wordforms пераменнай, для якой быў выкліканы метад, і завяршыць алгарытм. Калі не, перайсці да наступнага кроку.
Крок 2.1. Стварэнне пераменнай Pos і запіс у яе пазіцыі першага прабелу, які сустрэўся ў Str. Стварэнне пераменнай Headword і запіс у яе падрадка Str, які складаецца з усіх сімвалаў да пазіцыі Pos.
Крок 2.2. Калі апошні сімвал Headword з’яўляецца лічбай, выдаліць дадзены сімвал.
Крок 2.3. Стварэнне пераменнай Entry і паслядоўны запіс у яе ўсіх сімвалаў Str, якія знаходзяцца ў пазіцыі пасля Pos.
Крок 2.4. Калі Entry пачынаецца з паслядоўнасці сімвалаў «і» і прабела, выдаліць дадзеныя сімвалы з Entry, змяніць значэнне Pos на пазіцыю першага прабелу ў Entry, стварыць пераменную Headword2 і запісаць у яе ўсе сімвалы Entry да пазіцыі Pos, перазапісаць Entry, выдаліўшы ўсё, што ідзе да пазіцыі Pos.
Крок 2.5. Калі Entry пачынаецца з камбінацыі сімвалаў «м., толькі ў выразе: », «ж., толькі ў выразе: », «н., толькі ў выразе: », «мн., толькі ў выразе: », запісаць Headword у Wordforms. Калі пераменная Headwords2 створана і ініцыялізавана, запісаць у Wordforms таксама і яе. Вярнуць вынік у месца праграмы, дзе была выклікана функцыя, і завяршыць алгарытм.
Крок 3.1. Стварэнне масіву Paradigms і запіс у яго частак Entry, размежаваных паводле раздзяляльніка «; (». Стварэнне пераменнай Cnt і ініцыялізацыя яе колькасцю элементаў Paradigms.
Крок 3.2. Дадаць да кожнага элемента Paradigms сімвал «(» у пачатку.
Крок 3.3. Для кожнага элемента Paradigms выканаць крокі 3.3.1 – 3.3.8.
Крок 3.3.1. Стварэнне пераменнай subEntry і запіс у яе бягучага элемента Paradigms. Ператварэнне бягучага элемента Paradigms у масіў сімвалаў.
Крок 3.3.2. Выдзяленне семантыкі. Калі першы сімвал subEntry роўны «(», ініцыялізаваць Pos пазіцыяй першага ўваходжання сімвала «)» у subEntry, дадаць да бягучага элемента Paradigms асацыятыўны элемент Semantics, роўны камбінацыі сімвалаў ад першага сімвала «(» да першага сімвала «)» (не ўключаючы самі гэтыя сімвалы) і выдаліць з subentry усе сімвалы, якія ідуць да пазіцыі Pos+2. Калі не, дадаць да бягучага элемента Paradigms асацыятыўны элемент Semantics, роўны «unknown».
Крок 3.3.3.1. Апрацоўка нескланяльных назоўнікаў (1). Калі subentry роўны «м., нескл.», «ж., нескл.», «н., нескл.», «мн., нескл.», дадаць да Wordforms значэнне Headword, дадаць да бягучага элемента Paradigms асацыятыўны элемент [‘paradigm’][X], дзе X роўны NMN1, NFN1, NNN1 альбо NPN1 (адпаведна для назоўнікаў мужчынскага, жаночага, сярэдняга роду і назоўнікаў pluralia tantum); элемент [‘paradigm’][X] роўны Headword. Калі пры гэтым зададзена пераменная Headword2, дадаць да Wordforms значэнне Headword, дадаць да бягучага элемента Paradigms асацыятыўны элемент [‘paradigm’][Y], дзе Y роўны NMN2, NFN2, NNN2 альбо NPN2 (адпаведна для назоўнікаў мужчынскага, жаночага, сярэдняга роду і назоўнікаў pluralia tantum); элемент [‘paradigm’][Y] роўны Headword2. Прысвоіць Wordforms пераменнай, для якой быў выкліканы метад, і завяршыць алгарытм.
Крок 3.3.3.2. Апрацоўка нескланяльных назоўнікаў (2). Калі subentry роўны «н. і ж., нескл.», «м. і н., нескл.», «м. і ж., нескл.», дадаць да Wordforms значэнне Headword, дадаць да бягучага элемента Paradigms асацыятыўны элемент [‘paradigm’][X], дзе X роўны NMN1 альбо NNN1 (адпаведна для назоўнікаў мужчынскага і сярэдняга роду), а таксама элемент [‘paradigm’][Y], дзе Y роўны NFN1 альбо NNN1 (адпаведна для назоўнікаў жаночага і сярэдняга роду); і элемент [‘paradigm’][X], і элемент [‘paradigm’][Y] роўны Headword. Калі пры гэтым зададзена пераменная Headword2, дадаць да Wordforms значэнне Headword2, дадаць да бягучага элемента Paradigms асацыятыўны элемент [‘paradigm’][X], дзе X роўны NMN2 альбо NNN2 (адпаведна для назоўнікаў мужчынскага і сярэдняга роду), а таксама элемент [‘paradigm’][Y], дзе Y роўны NFN2 альбо NNN2 (адпаведна для назоўнікаў жаночага і сярэдняга роду); і элемент [‘paradigm’][X], і элемент [‘paradigm’][Y] роўны Headword2. Прысвоіць Wordforms пераменнай, для якой быў выкліканы метад, і завяршыць алгарытм.
Крок 3.3.4. Стварэнне асацыятыўнага элемента [paradigm] для бягучага элемента Paragigms. Элемент [paradigm] уяўляе сабой асацыятыўны масіў, у якім кожнай ячэйцы адпавядае канкрэтная родавая форма або форма множнага ліку ў канкрэтным склоне.
Крок 3.3.5. Стварэнне пераменнай bothGender = false. Калі subentry пачынаецца з камбінацыі сімвалаў «м. і ж., », зрабіць bothGender роўнай true і выдаліць дадзеную камбінацыю сімвалаў з subEntry.
Крок 3.3.6. Раздзяленне парадыгмы на фрагменты аднаго роду і ліку («шасцёркі»). Стварэнне масіву subSubEntryArr і запаўненне яго часткамі subEntry, размежаванымі з дапамогай раздзяляльніка «; ». Калі колькасць элементаў subSubEntryArr меншая, чым 2, або роўная 2, а bothGender = true, дадаць да Errors радок «Некарэктны запіс для агульнага роду: $str<br>», вярнуць у кропку выкліку метаду false і завяршыць алгарытм. Калі колькасць элементаў subSubEntryArr большая за 2, а bothGender = false, дадаць да Errors радок «Зашмат кропак з коскамі пры звычайных умовах: $str<br>», вярнуць у кропку выкліку метаду false і завяршыць алгарытм.
Крок 3.3.7. Для кожнага элемента subSubEntry у subSubEntryArr выканаць крокі 3.3.7.1. – 3.3.7.3.
Крок 3.3.7.1. Стварэнне пераменнай Gender і ініцыялізацыя яе пустым мноствам. Калі subSubEntry пачынаецца з «м. », «ж. », «н. », «мн. », «мн. для абодвух », «толькі мн.», прысвоіць Gender значэнне «M», «F», «N» або «P» для апошніх трох выпадкаў адпаведна і выдаліць пачатковыя камбінацыі сімвалаў з subSubEntry. Калі subSubEntry не пачынаецца ні з адной з дадзеных камбінацый сімвалаў, дадаць да Errors радок «Незразумелыя лікі і роды ў выразе ‘<i>$subSubEntry</i>'<br>», вярнуць у пункт выкліку метаду false і завяршыць алгарытм.
Крок 3.3.7.2. Стварэнне асацыятыўнага масіву caseArr і ініцыялізацыя яго наступным чынам: ‘Н’ => 0, ‘Р’ => 0, ‘Д’ => 0, ‘В’ => 0, ‘Т’ => 0, ‘М’ => 0. Стварэнне асацыятыўнага масіву caseTags і ініцыялізацыя яго наступным чынам: ‘Н’ => ‘N‘, ‘Р’ => ‘G‘, ‘Д’ => ‘D‘, ‘В’ => ‘A‘, ‘Т’ => ‘I‘, ‘М’ => ‘P‘. Стварэнне пераменнай casesCnt=0. Стварэнне масіву tmp і запаўненне яго часткамі subSubEntry, размежаванымі з дапамогай раздзяляльніка «, ».
Крок 3.3.7.3. Для кожнага элемента wordform у масіве tmp выканаць крок 3.3.7.3.1.
Крок 3.3.7.3.1. Стварэнне масіву match. Спроба запоўніць дадзены масіў часткамі wordform, якія адпавядаюць рэгулярнаму выразу /[НРДВТМ]{1,6} /, прычым нулявы элемент масіву павінен змяшчаць частку радка, якая адпавядае ўваходжанню ўсяго шаблону, а ўсе наступныя элементы – часткі радка, якія адпавядаюць падмаскам. Калі дадзеную аперацыю ўдалося здзейсніць, выканаць крокі 3.3.7.3.1.1. – 3.3.7.3.1.3. Калі не – пераход да кроку 3.3.7.3.2.
Крок 3.3.7.3.1.1. Ініцыялізацыя Pos даўжынёю радка match[0]. Стварэнне пераменнай cases і ініцыялізацыя яе камбінацыяй усіх сімвалаў match[0], акрамя апошняга. Ініцыялізацыя Wordform камбінацыяй усіх сімвалаў бягучага значэння Wordform да пазіцыі Pos. Стварэнне масіву chars і ініцыялізацыя яго сімваламі, з якіх складаецца cases.
Крок 3.3.7.3.1.2. Для кожнага char у масіве chars выканаць крок 3.3.7.3.1.2.1.
Крок 3.3.7.3.1.2.1. Калі элемент char прысутнічае ў caseArr, выканаць крокі 3.3.7.3.1.2.1.1. – 3.3.7.3.1.2.1.4., інакш – дадаць да Errors радок «У слоўнікавым артыкуле №$i некарэктны тэг ” . $cases . ‘.’ . $br;», вярнуць false у пункт праграмы, дзе быў выкліканы метад, і завяршыць алгарытм.
Крок 3.3.7.3.1.2.1.1. Ініцыялізацыя элемента масіву caseArr, які адпавядае char, значэннем 1.
Крок 3.3.7.3.1.2.1.2. Стварэнне масіву variants і яго ініцыялізацыя – выкананне крокаў 3.3.7.3.1.2.1.2.1. – 3.3.7.3.1.2.1.2.2.
Крок 3.3.7.3.1.2.1.2.1. Стварэнне пустога масіву Wordforms2.
Крок 3.3.7.3.1.2.1.2.2. Калі ў Wordform ёсць камбінацыя сімвалаў «прабел+(», выканаць крокі 3.3.7.3.1.2.1.2.2.1. – 3.3.7.3.1.2.1.2.2.5. Інакш – ініцыялізаваць Wordforms2 значэннем Wordform.
Крок 3.3.7.3.1.2.1.2.2.1. Ініцыялізацыя Pos пазіцыяй першага ўваходжання камбінацыі сімвалаў «прабел+(» у Wordform.
Крок 3.3.7.3.1.2.1.2.2.2. Стварэнне пераменнай wordform1 і ініцыялізацыя яе ўсімі сімваламі Wordform да пазіцыі Pos. Стварэнне пераменнай wordform2 і ініцыялізацыя яе ўсімі сімваламі Wordform пасля пазіцыі Pos.
Крок 3.3.7.3.1.2.1.2.2.3. Калі ў wordform1 галосная літара беларускага алфавіта сустракаецца роўна адзін раз, і пры гэтым адсутнічае сімвал націску, замяніць дадзеную галосную літару на тую ж галосную літару, але з сімвалам націску.
Крок 3.3.7.3.1.2.1.2.2.4. Дадаць wordform1 у Wordforms2.
Крок 3.3.7.3.1.2.1.2.2.5. Калі wordform2 пачынаецца з камбінацыі сімвалаў «(-», выканаць крокі 3.3.7.3.1.2.1.2.2.5.1. – 3.3.7.3.1.2.1.2.2.5.6. Інакш, калі wordform2 пачынаецца з сімвала «(», дадаць wordform2 з выдаленымі пачатковай і канцавой дужкай у Wordforms2.
Крок 3.3.7.3.1.2.1.2.2.5.1. Выдаліць з wordform2 пачатковую камбінацыю сімвалаў «(-» і канцавы сімвал.
Крок 3.3.7.3.1.2.1.2.2.5.2. Стварэнне пераменнай letter і дадаванне ў яе першага сімвала wordform2.
Крок 3.3.7.3.1.2.1.2.2.5.3. Стварэнне пераменнай rpos і ініцыялізацыя яе пазіцыяй апошняга ўваходжання letter у wordform1.
Крок 3.3.7.3.1.2.1.2.2.5.4. Рэініцыялізацыя значэння пераменнай wordform2 канкатэнацыяй камбінацыі сімвалаў wordform1 да пазіцыі rpos і бягучага значэння wordform2.
Крок 3.3.7.3.1.2.1.2.2.5.5. Калі ў wordform2 больш сімвалаў націску, чым у wordform1, дадаць у Errors радок «Пры расшыфроўцы скарачэння $wordform узніклі лішнія націскі<br>».
Крок 3.3.7.3.1.2.1.2.2.5.6. Дадаць wordform2 да Wordforms2.
Крок 3.3.7.3.1.2.1.3. Для k=0; k < [колькасць элементаў variants], k++ выканаць крок 3.3.7.3.1.2.1.3.1.
Крок 3.3.7.3.1.2.1.3.1. Калі variants[k] зададзены, выканаць крокі 3.3.7.3.1.2.1.3.1.1. – 3.3.7.3.1.2.1.3.1.3.
Крок 3.3.7.3.1.2.1.3.1.1. Ініцыялізацыя пераменнай tag канкатэнацыяй радка «N», значэння Gender, элементам caseTags, які адпавядае char, і радковым значэннем k+1.
Крок 3.3.7.3.1.2.1.3.1.2. Ініцыялізацыя асацыятыўнага элемента бягучага элемента paradigm [‘paradigm’][tag] значэннем variants[k].
Крок 3.3.7.3.1.2.1.3.1.3. Даданне ў Wordforms значэння variants[k].
Крок 3.3.7.3.1.2.1.4. Інкрэментаваць casesCnt.
Крок 3.3.7.3.1.3. Калі caseArr[‘Н’] = 0, выканаць крокі 3.3.7.3.1.3.1. – 3.3.7.3.1.3.4.
Крок 3.3.7.3.1.3.1. Ініцыялізаваць caseArr[‘Н’] значэннем 1.
Крок 3.3.7.3.1.3.2. Ініцыялізаваць tag канкатэнацыяй радка «N», значэння Gender і радка «N».
Крок 3.3.7.3.1.3.3. Задаць асацыятыўны элемент бягучага элемента Paradigm [[‘paradigm‘][$tag . ‘1’]] роўным Headword і дадаць Headword да Wordforms. Калі Headword2 зададзены, задаць асацыятыўны элемент бягучага элемента Paradigm [[‘paradigm‘][$tag . ‘2’]] роўным Headword і дадаць Headword2 да Wordforms.
Крок 3.3.7.3.1.3.4. Інкрэментаваць casesCnt.
Крок 3.3.7.3.2. Калі аперацыю, указаную ў кроку 3.3.7.3.1., выканаць не ўдалося, для кожнага элемента case у caseArr запісаць парадкавы нумар case у пераменную v і выканаць крок 3.3.7.3.2.1.
Крок 3.3.7.3.2.1. Калі значэнне v = 0, і пры гэтым умова <case = «Н» і Gender не роўны «P»> няправільная, выканаць крокі 3.3.7.3.2.1.1. – 3.3.7.3.2.1.4., інакш перайсці да наступнага элемента case і выканаць крок 3.3.7.3.2.1. яшчэ раз.
Крок 3.3.7.3.2.1.1. Зрабіць пераменную v роўнай 1.
Крок 3.3.7.3.2.1.2. Стварэнне масіву variants і яго ініцыялізацыя тым жа спосабам, што быў указаны ў кроках 3.3.7.3.1.2.1.2.1. – 3.3.7.3.1.2.1.2.2.
Крок 3.3.7.3.2.1.3. Для k=0; k<[колькасць элементаў variant], k++ выканаць крок 3.3.7.3.2.1.3.1.
Крок 3.3.7.3.2.1.3.1. Калі variants[k] зададзены, выканаць крокі 3.3.7.3.2.1.3.1.1. – 3.3.7.3.2.1.3.1.3.
Крок 3.3.7.3.2.1.3.1.1. Ініцыялізацыя tag канкатэнацыяй радка «N», значэння Gender, значэння caseTags[case] і лічбавага значэння k+1.
Крок 3.3.7.3.2.1.3.1.2. Дадаванне да бягучага элемента Paradigms асацыятыўнага элемента [‘paradigm‘][tag], роўнага variants[k].
Крок 3.3.7.3.2.1.3.1.3. Дадаванне variants[k] да Wordforms.
Крок 3.3.7.3.2.1.4. Інкрэментаваць casesCnt і скончыць перабор, пачаты ў кроку 3.3.7.3.2.1.
Крок 3.3.8. Калі casesCnt не роўнае 6 альбо 12, дадаць да Errors радок «$casesCnt слоў у парадыгме ‘<b><i>$subSubEntry</i></b>’, а не 6 і не 12<br>», вярнуць false у пункт выкліку метаду і завяршыць алгарытм.
Крок 4. Вярнуць Wordforms у пункт выкліку метаду і завяршыць алгарытм.
Канец алгарытму.
Алгарытм парсінгу прыметнікаў.
- Тэкставыя дадзеныя ў спецыяльным фармаце, Str;
- Спіс выключэнняў, Exceptions;
- Спіс адфарматаваных тэкставых дадзеных, якія карэлююць з Exceptions, ExeptionsMatches;
- Пераменная для запісу памылак, Errors.
Пачатак алгарытму.
Крок 1.1. Стварэнне пустога масіву Wordforms.
Крок 1.2. Праверка на наяўнасць прабелаў у Str. Калі прабелаў не выяўлена, дадаць да Errors радок «Аніводнага прабелу ў запісе: $str<br>», вярнуць пусты масіў і завяршыць алгарытм. Інакш – перайсці да наступнага кроку.
Крок 2.1. Стварэнне пераменнай Pos і запіс у яе пазіцыі першага прабелу ў Str.
Крок 2.2. Калі першым сімвалам да пазіцыі Pos з’яўляецца сімвал «:», праверыць Str на адпаведнасць элементам Exceptions – словам, якія сустракаюцца толькі ў некаторых выразах. Калі дадзеная адпаведнасць устаноўлена, выбраць элемент, які карэлюе, з ExceptionMatches, запісаць яго ў Wordforms, вярнуць Wordforms у пункт выкліку метаду і завяршыць алгарытм. Інакш – перайсці да наступнага кроку.
Крок 2.3. Стварэнне пераменных Singular і Plural і ініцыялізацыя іх пустым радком.
Крок 2.4. Калі ў Str не прысутнічае камбінацыя сімвалаў «; мн. », праверыць Str на адпаведнасць элементам Exceptions. Калі адпаведнасць знойдзена сярод слоў, якія не маюць формы адзіночнага ліку, запісаць неабходнае значэнне ў пераменную Plural. Калі адпаведнасць знойдзеная ў іншым раздзеле Exceptions (сярод радкоў для слоў «кайназо́йскі», «эазо́йскі», «эалі́тавы», «ю́рскі»), запісаць значэнне Str у пераменную Singular. Калі камбінацыя «; мн. » прысутнічае ў Str, разбіць Str паводле раздзяляльніка «; мн. » і запісаць першую частку (калі такая ёсць) у пераменную Singular, другую частку (калі такая ёсць) – у пераменную Plural.
(далейшыя крокі алгарытму ў працэсе напісання)
Алгарытм парсінгу лічэбнікаў.
Алгарытм у працэсе напісання.
Алгарытм парсінгу займеннікаў.
Алгарытм у працэсе напісання.
Алгарытм парсінгу дзеясловаў.
Алгарытм у працэсе напісання.
Алгарытм парсінгу прыслоўяў.
Алгарытм у працэсе напісання.
Апісанне інтэрфейсу карыстальніка
Знешні выгляд карыстальніцкага інтэрфейсу сэрвіса прадстаўлены на малюнку 1.

Малюнак 1 – Графічны інтэрфейс сэрвіса «Апрацоўка граматычнага слоўніка»
Інтэрфейс змяшчае наступныя вобласці:
- Поле для ўводу тэксту ў спецыяльным фармаце. Аснашчана кнопкамі «Абнавіць» (зварот дадзеных па змаўчанні) і «Ачысціць» (выдаленне ўсіх дадзеных);
- Выпадальнае меню для выбару шаблону апрацоўкі. Мае пункты «Назоўнік», «Прыметнік», «Лічэбнік», «Займеннік», «Дзеяслоў», «Прыслоўе»;
- Кропка «Апрацаваць!», якая запускае апрацоўку і дазваляе атрымаць вынікі.
Пасля націскання кнопкі «Апрацаваць» у ніжняй частцы экрана з’явяцца наступныя вобласці (гл. малюнак 2):
- Тэкставая інфармацыя з дадзенымі пра колькасць апрацаваных слоўнікавых артыкулаў і спасылкамі на спампоўванне тэкставых файлаў з HTML-табліцай і SQL-інструкцыямі;
- Вобласць «Памылкі» для вываду інфармацыі пра памылкі, якія ўзніклі ў працэсе апрацоўкі (з’яўляецца, калі памылкі сапраўды мелі месца);
- Вобласць выдачы вынікаў.
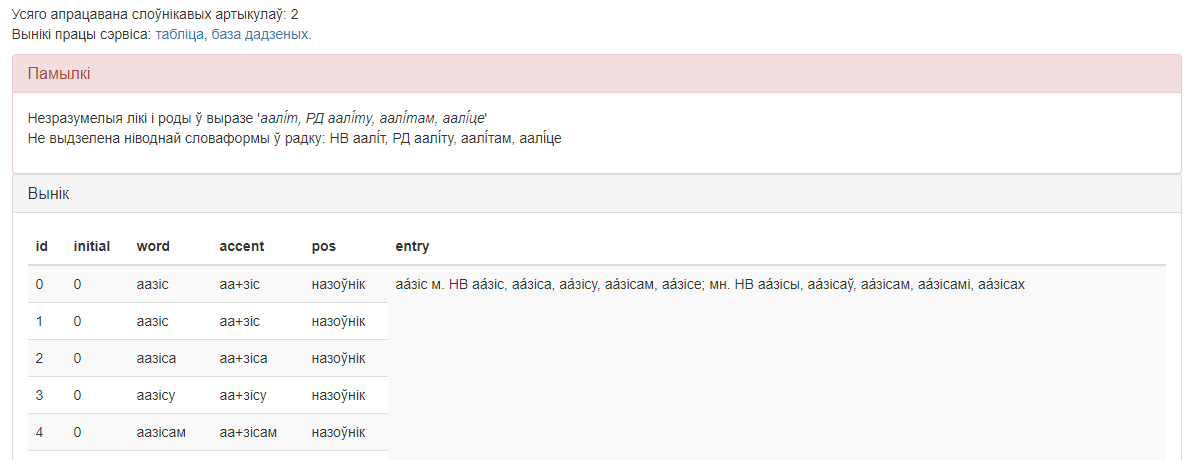
Малюнак 2 – Графічны інтэрфейс сэрвіса «Апрацоўка граматычнага слоўніка» – вобласці, якія з’яўляюцца пасля націскання на кнопку «Апрацаваць!»
Карыстальніцкія сцэнарыі працы з сэрвісам
Сцэнарый 1. Атрыманне граматычнага слоўніка ў выглядзе HTML-табліцы.
- Увесці дадзеныя ў правільным тэкставым фармаце ў полі ўводу.
- Выбраць неабходны шаблон апрацоўкі.
- Націснуць кнопку «Апрацаваць!».
- Прагледзець вынікі апрацоўкі і магчымыя памылкі, пры неабходнасці – выправіць памылкі і націснуць кнопку «Апрацаваць!» яшчэ раз.
- Націснуць на гіперспасылку «табліца» і захаваць HTML-код, які з’явіўся ў новым акне.
Магчымы вынік працы сэрвіса згодна з дадзеным сцэнарыем прадстаўлены на малюнку 3.

Малюнак 3 – Вынік працы сэрвіса згодна са сцэнарыем №1
Сцэнарый 2. Атрыманне SQL–інструкцый для стварэння базы дадзеных граматычнага слоўніка.
- Увесці дадзеныя ў правільным тэкставым фармаце ў полі ўводу.
- Выбраць неабходны шаблон апрацоўкі.
- Націснуць кнопку «Апрацаваць!».
- Прагледзець вынікі апрацоўкі і магчымыя памылкі, пры неабходнасці – выправіць памылкі і націснуць кнопку «Апрацаваць!» яшчэ раз.
- Націснуць на гіперспасылку «база дадзеных» і захаваць SQL-інструкцыі, якія з’явіліся ў новым акне.
Магчымы вынік працы сэрвіса згодна з дадзеным сцэнарыем прадстаўлены на малюнку 4.

Малюнак 4 – Вынік працы сэрвіса згодна са сцэнарыем №2
Незалежна ад рэалізаванага сцэнарыя вынікі працы сэрвіса будуць прадстаўленыя таксама ў выглядзе табліцы ў асноўным акне сэрвіса (малюнак 5).
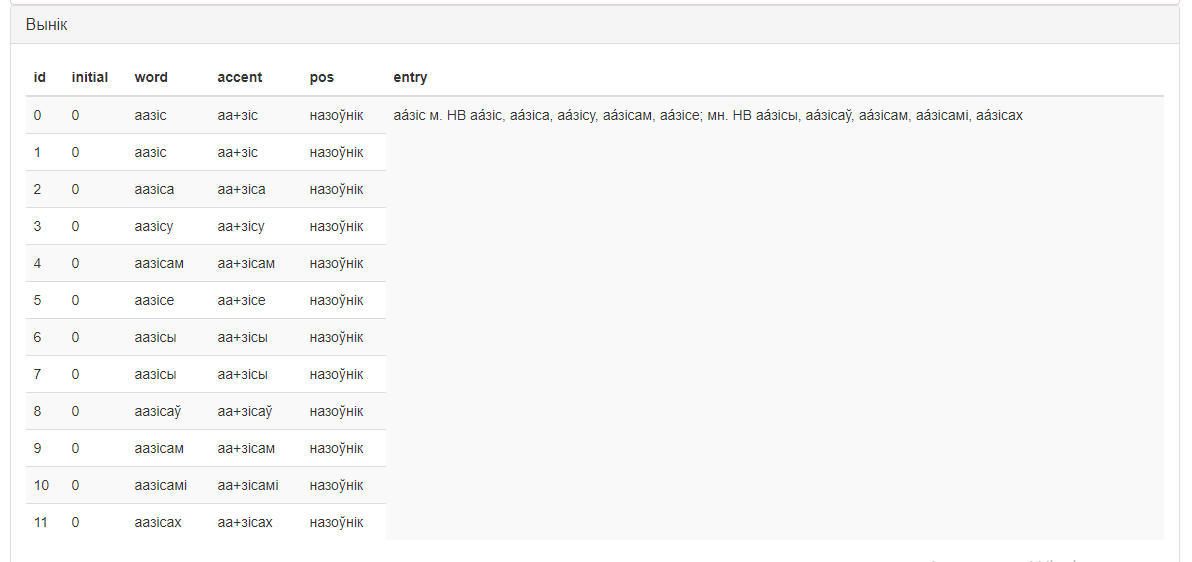
Малюнак 5 – Вынік працы сэрвіса «Апрацоўка граматычнага слоўніка»
Доступ да сэрвіса праз API
Для доступу да сэрвіса праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/GrammaticalDictionaryProcessor/api.php. Праз масіў data перадаюцца наступныя параметры:
- localization – мова лакалізацыі. Вызначае мову загалоўкаў выніковай табліцы;
- text – тэкставыя дадзеныя ў патрэбным фармаце;
- pos – тып шаблонаў апрацоўкі. Параметр можа прымаць наступныя значэнні:
- noun – апрацоўка згодна з шаблонамі апрацоўкі назоўніка;
- adjective – апрацоўка згодна з шаблонамі апрацоўкі прыметніка;
- numeral – апрацоўка згодна з шаблонамі апрацоўкі лічэбніка;
- pronoun – апрацоўка згодна з шаблонамі апрацоўкі займенніка;
- verb – апрацоўка згодна з шаблонамі апрацоўкі дзеяслова;
- adverb – апрацоўка згодна з шаблонамі апрацоўкі прыслоўя.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/GrammaticalDictionaryProcessor/api.php”,
data:{
“localization”: “en”
“text”: “аа́зіс м. НВ аа́зіс, аа́зіса, аа́зісу, аа́зісам, аа́зісе; мн. НВ аа́зісы, аа́зісаў, аа́зісам, аа́зісамі, аа́зісах”,
“pos”: “noun”
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з зыходным тэкстам (параметр text), выніковай табліцай (параметр table), выніковымі інструкцыямі для стварэння базы дадзеных з дапамогай сродкаў SQL (параметр sql), спасылкай на тэкставы файл з HTML-кодам табліцы (параметр tableUrl), спасылкай на тэкставы файл з SQL-інструкцыямі (параметр sqlUrl), агульнай колькасцю апрацаваных слоўнікавых артыкулаў (параметр cnt) і спісам памылак (параметр errors). Напрыклад, паводле прыведзенага вышэй AJAX–запыту будзе сфарміраваны наступны адказ:
[
{
“text”: “аа́зіс м. НВ аа́зіс, аа́зіса, аа́зісу, аа́зісам, аа́зісе; мн. НВ аа́зісы, аа́зісаў, аа́зісам, аа́зісамі, аа́зісах”,
“table”: “<table id=”resultTableId” class=”table table–sm table–striped“><thead><tr><th scope=”col“>id</th><th scope=”col“>initial</th><th scope=”col“>word</th><th scope=”col“>accent</th><th scope=”col“>pos</th><th scope=”col“>entry</th></thead><tbody><tr><td>0</td><td>0</td><td>аазіс</td><td>аа+зіс</td><td>назоўнік</td><td rowspan=12>аа́зіс м. НВ аа́зіс, аа́зіса, аа́зісу, аа́зісам, аа́зісе; мн. НВ аа́зісы, аа́зісаў, аа́зісам, аа́зісамі, аа́зісах</td></tr><tr><td>1</td><td>0</td><td>аазіс</td><td>аа+зіс</td><td>назоўнік</td></tr><tr><td>2</td><td>0</td><td>аазіса</td><td>аа+зіса</td><td>назоўнік</td></tr><tr><td>3</td><td>0</td><td>аазісу</td><td>аа+зісу</td><td>назоўнік</td></tr><tr><td>4</td><td>0</td><td>аазісам</td><td>аа+зісам</td><td>назоўнік</td></tr><tr><td>5</td><td>0</td><td>аазісе</td><td>аа+зісе</td><td>назоўнік</td></tr><tr><td>6</td><td>0</td><td>аазісы</td><td>аа+зісы</td><td>назоўнік</td></tr><tr><td>7</td><td>0</td><td>аазісы</td><td>аа+зісы</td><td>назоўнік</td></tr><tr><td>8</td><td>0</td><td>аазісаў</td><td>аа+зісаў</td><td>назоўнік</td></tr><tr><td>9</td><td>0</td><td>аазісам</td><td>аа+зісам</td><td>назоўнік</td></tr><tr><td>10</td><td>0</td><td>аазісамі</td><td>аа+зісамі</td><td>назоўнік</td></tr><tr><td>11</td><td>0</td><td>аазісах</td><td>аа+зісах</td><td>назоўнік</td></tr></tbody></table>”,
“sql”: “SET SQL_MODE=”NO_AUTO_VALUE_ON_ZERO”;
SET time_zone = “+00:00”;
CREATE TABLE IF NOT EXISTS `noun2013` (
`id` int NOT NULL,
`initial` int NOT NULL,
`word` varchar(32) COLLATE utf8_bin DEFAULT NULL,
`accent` varchar(32) COLLATE utf8_bin DEFAULT NULL,
`pos` varchar(16) DEFAULT NULL,
`entry` varchar(640) DEFAULT NULL,
PRIMARY KEY(`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE INDEX IDX_noun2013_initial ON noun2013 (initial);
CREATE INDEX IDX_noun2013_word ON noun2013 (word);
CREATE INDEX IDX_noun2013_accent ON noun2013 (accent);
CREATE INDEX IDX_noun2013_pos ON noun2013 (pos);
INSERT INTO `noun2013` (`id`, `initial`, `word`, `accent`, `pos`, `entry`) VALUES
(0, 0, ‘аазіс’, ‘аа+зіс’, ‘назоўнік’, ‘аа́зіс м. НВ аа́зіс, аа́зіса, аа́зісу, аа́зісам, аа́зісе; мн. НВ аа́зісы, аа́зісаў, аа́зісам, аа́зісамі, аа́зісах’),
(1, 0, ‘аазіс’, ‘аа+зіс’, ‘назоўнік’, ”),
(2, 0, ‘аазіса’, ‘аа+зіса’, ‘назоўнік’, ”),
(3, 0, ‘аазісу’, ‘аа+зісу’, ‘назоўнік’, ”),
(4, 0, ‘аазісам’, ‘аа+зісам’, ‘назоўнік’, ”),
(5, 0, ‘аазісе’, ‘аа+зісе’, ‘назоўнік’, ”),
(6, 0, ‘аазісы’, ‘аа+зісы’, ‘назоўнік’, ”),
(7, 0, ‘аазісы’, ‘аа+зісы’, ‘назоўнік’, ”),
(8, 0, ‘аазісаў’, ‘аа+зісаў’, ‘назоўнік’, ”),
(9, 0, ‘аазісам’, ‘аа+зісам’, ‘назоўнік’, ”),
(10, 0, ‘аазісамі’, ‘аа+зісамі’, ‘назоўнік’, ”),
(11, 0, ‘аазісах’, ‘аа+зісах’, ‘назоўнік’, ”),
(12, 12, ”, ”, ”);”,
“tableUrl”: “..\/_cache\/GrammaticalDictionaryProcessor\/out\/2020-06-04_23-13-27_37-214-33-191_621_table_out.txt”,
“sqlUrl”: “..\/_cache\/GrammaticalDictionaryProcessor\/out\/2020-06-04_23-13-27_37-214-33-191_621_sql_out.txt”,
“cnt”: 1,
“errors”: “”
}
]
Спасылкі на крыніцы
Старонка сэрвіса – https://corpus.by/GrammaticalDictionaryProcessor/