The «Nearest Words Finder» service processes sequences of characters separated by indentation characters and compares them with user dictionary sequences. The result of the service work is an HTML table with «word – match» pairs, where the word is the original sequence of characters, the match is the dictionary sequence of characters closest to the word according to Levenshtein distance.
Basic terms and concepts
Levenshtein distance (editorial distance, distance of editing) is a metric that measures the difference between two sequences of characters. It is defined as the minimum number of one-character operations (namely, insertion, deletion, replacement) needed to transform one sequence of characters into another. In the general case, the operations used in this transformation can be assigned different prices (within the framework of the service work, the operations are equivalent). Widely used in information theory and computer linguistics. For the first time the task of measuring the distance of editing was posed in 1965 by the Soviet mathematician Vladimir Levenshtein.
Practical value
The practical value of the service «Nearest Words Finder» is largely due to the sphere of using of the Levenshtein distance calculation. This calculation is actively used:
- to correct errors in a word (in search engines, databases, during text entering, with automatic recognition of scanned text or speech);
- for comparing text files (in case of such comparison, lines play the role of «characters», and files play the role of «lines»);
- in bioinformatics – to compare genes, chromosomes and proteins.
Service features
Some programming languages (such as PHP) have standard built-in functions for calculating the Levenshtein distance. Nevertheless, the implementation of these functions can seriously limit the length of the compared strings, as a result of that, processing of large strings leads to a deliberately incorrect result. In addition, there is no guarantee that this function is not implemented recursively. In many cases such an implementation may require undesired spending of system resources. Our calculation of the Levenshtein distance is implemented iteratively and has a high threshold for the length of the words being compared – 1 million characters (the restriction is set only to exclude server overloads).
All the words that the service analyzes are pre-processed. Thus, the service considers «words» only those sequences that consist of basic Cyrillic and Latin characters, the main characters of the apostrophe, accent and hyphen, and also correspond to a certain pattern (which corresponds to the vast majority of words in natural languages). Processing is case-insensitive – for example, the characters «k» and «K» are considered the same character.
Service operation algorithm
Basic algorithm
Algorithm input data:
- User text input, Text;
- User input of dictionary words, Dictionary;
- The value of the option responsible for including in the summary table words for which a full match is found in the dictionary, KnownWordsIgnore. If true, similar words will not appear in the output;
- Basic characters that the word can consist of (basic Cyrillic and Latin characters), MainChars;
- Additional characters that the word can consist of (characters of the apostrophe, main and secondary accent, hyphen), AdditionalChars.
The beginning of the algorithm.
Step 1.1. Turning all words in the Dictionary to the lowercase. Dividing of the Dictionary into separate elements; the separator is all possible indentation characters.
Step 1.2. Creating a Result variable and recording the initial code of the final HTML table into it:
<table id=”resultTableId” class=”table table-sm table-striped” style=”table-layout: fixed; width: 100%;”><thead><tr><th scope=”col”><b>Unknown word</b></th><th scope=”col”><b>Possible variant</b></th></tr></thead><tbody>’;
Step 1.3. Creation of the ParagrapsArr array and filling it with lines of user input Text (user input, separated by a line feed character).
Step 2. For each Paragraph element in ParagraphsArr, perform steps 2.1. – 2.3.
Step 2.1. Remove initial and last indent characters from Paragraph.
Step 2.2. Create the WordsArr array and fill it sequentially with all Paragraph elements matching the pattern [<one MainChars character> + <0 or more MainChars or AdditionalChars characters>] or the pattern [0 or more MainChars characters].
Step 2.3. For all Word elements in WordsArr, perform steps 2.3.1. – 2.3.3.
Step 2.3.1. Create a Nearest variable for the subsequent record of the word closest to Word and initialize it with a null value. Create the Distance variable for the subsequent recording of the Levenshtein distance and initialize it with the value 999999.
Step 2.3.2. For each Entry element in the Dictionary, perform steps 2.3.2.1. – 2.3.2.2.
Step 2.3.2.1. Create a Lev variable and record in it the distance between Word and Entry determined by the Levenshtein distance calculation function.
Step 2.3.2.2. If Lev = 0, make the Nearest variable equal to Word, set the Distance value to 0, and end the cycle that started in step 2.3.2. Otherwise, if Lev < Distance, make the Nearest variable equal to Entry, make the Distance variable equal to Lev. Repeating of this step at each iteration of the cycle that was started in step 2.3.2. will result in finding the word closest to Word.
Step 2.3.3. If KnownWordsIgnore = true, and Distance is not 0, add Result with a line of the form [«<tr> <td style =”word-wrap: break-word”>»+Word+«</td> <td style =”word -wrap: break-word”>»+Nearest+«</td> </tr>»]. If KnownWordsIgnore = false, add Result with this line anyway.
Step 3. Add Result with the string «</tbody> </table>» and finish the formation of the result table.
Step 4. Issue the result table to the user.
The end of the algorithm.
Levenshtein distance calculation function
Algorithm input data:
- The first word, First;
- The second word, Second.
The beginning of the algorithm.
Step 1. If the words First and Second are identical, return 0 and finish the algorithm.
Step 2.1. Create a FLen variable and record the length of the First string to it. Create a variable SLen and record the length of the Second string to it.
Step 2.2. If FLen = 0 or SLen = 0, return FLen (in the case of SLen = 0) or SLen (in the case of FLen = 0) and finish the algorithm.
Step 3. Create a Dist array and fill it with numbers from 0 to SLen, each number is bigger than the previous by one.
Step 4. For I = 0; I < FLen; I++ perform steps 4.1. – 4.3.
Step 4.1 Create a ForDist array consisting of a single element equal to I+1.
Step 4.2 For J = 0; J < SLen; J++ perform steps 4.2.1 – 4.2.2.
Step 4.2.1. Create a numeric variable Cost to record the «cost» adjustment of the replacement operation. If the character First[I] is equal to the character Second[J], initialize Cost with value 0, otherwise – with value 1.
Step 4.2.2. Attach a new element to ForDist (in the software implementation, the ordinal number of this element is J+1), equal to the minimum of the following three values:
- Dist[J+1] + 1 (cost of insertion operation);
- ForDist[J] + 1 (cost of deletion operation);
- Dist[J] + Cost (cost of replacement operation).
Step 4.3. Subsequently initialize the cells of the Dist array by the values of the corresponding cells of the ForDist array obtained after performing step 4.2. (the length of both arrays will be equal). This step is performed at the end of each iteration of the cycle that started in step 4.
Step 5. Return the value of the last cell in the Dist array (in the software implementation, the value of the cell whose ordinal number corresponds to SLen) and finish the algorithm.
The end of the algorithm.
User interface description
The appearance of the user interface is shown in Figure 1.
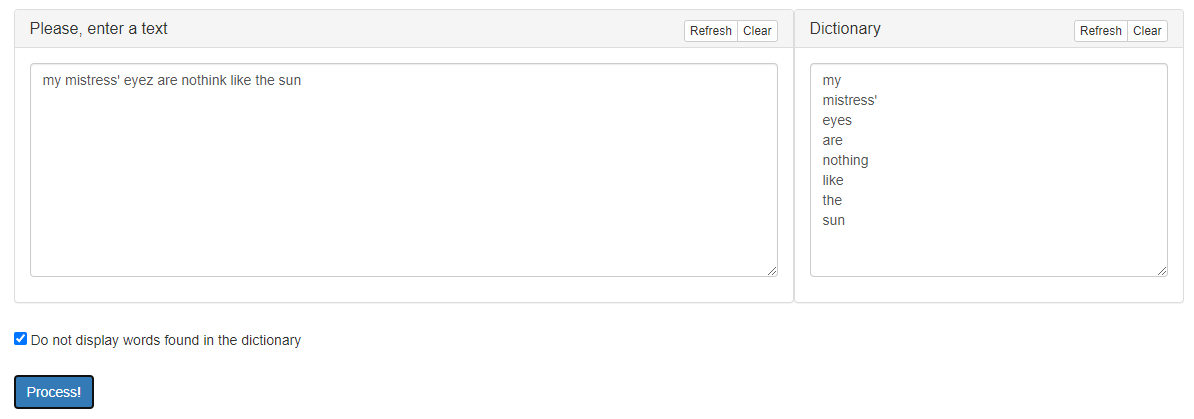
Figure 1 – Graphical interface of the service «Nearest Words Finder»
The interface has the following areas:
- Input field for text for processing. This field is equipped with the buttons «Refresh» (return default data) and «Clear» (delete all data);
- Field «Dictionary» for input of words for verification. This field is also equipped with the «Refresh» and «Clear» buttons;
- The option «Do not display words found in the dictionary», which affects the final result of the service work;
- The button «Process!», which starts processing and gives the opportunity to get results.
After clicking the «Process!» button and processing, a table with the results appears at the bottom of the screen.
User scenarios of work with the service
Scenario 1. Processing with displaying of all words of the source text
- Enter text in the text input field.
- Enter the words for verification, separated by spaces and/or tabs and line feeds, in the «Dictionary» field.
- Make sure that the option «Do not display words found in the dictionary» is disabled. If the option is enabled, clear the corresponding check box.
- Click the «Process!» Button.
- Obtain the result in the results issuing field. If necessary, make changes to the source text and click the «Process!» button again.
The possible result of the service work according to this scenario is presented in Figure 2.
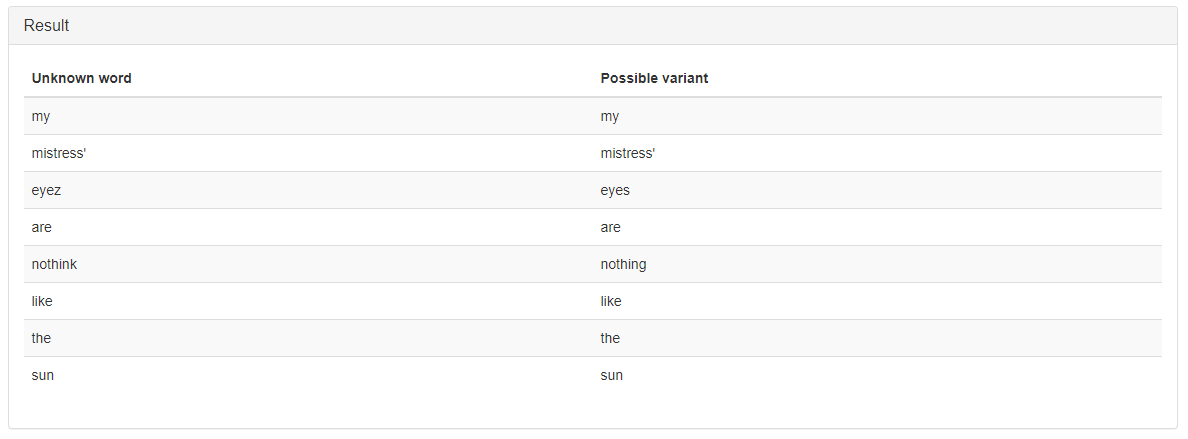
Figure 2 – The result of the «Nearest Words Finder» service work according to the scenario 1
Scenario 2. Processing with displaying only unknown words
- Enter text in the text input field.
- Enter the words for verification, separated by spaces and/or tabs and line feeds, in the «Dictionary» field.
- Make sure that the option «Do not display words found in the dictionary» is enabled. If the option is disabled, check the corresponding box.
- Click the «Process!» button.
- Obtain the result in the results issuing field. If necessary, make changes to the source text and click the «Process!» button again.
The possible result of the service work according to this scenario is presented in Figure 3.

Figure 3 – The result of the «Nearest Words Finder» service work according to the scenario 2
Access to the service via the API
To access the «Nearest Words Finder» service via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/NearestWordsFinder/api.php. The following parameters are passed through the data array:
- localization – localization language. It can take the values «en» (English) and «be» (Belarusian).
- text – sequences of characters located between indent characters, which will be compared with dictionary values.
- dictionary – sequences of characters located between indent characters, which will be compared with the words in the source text.
- knownWordsIgnore – parameter responsible for displaying text words found in the dictionary. It can take the values «0» (display) and «1» (do not display).
Example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/NearestWordsFinder/api.php”,
data:{
“localization”: “en”,
“text”: “укоз об налогах на растаможивании автомобилей”,
“dictionary”: “указ налоги на налогах автомобили растаможить растаможил растаможивании автомобилей об”,
“knownWordsIgnore”: 0
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with the source text (parameter text) and the code of the resulting HTML table (result parameter) with the «word – match» pairs, where the word is the original sequence of characters, the match is the dictionary sequence of characters closest to the word according to Levenshtein distance. For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “укоз об налогах на растаможивании автомобилей“,
“result”: <table id=\”resultTableId\” class=\”table table-sm table-striped\” style=\”table-layout: fixed; width: 100%;\”><thead><tr><th scope=\”col\”><b>Unknown word<\/b><\/th><th scope=\”col\”><b>Possible variant<\/b><\/th><\/tr><\/thead><tbody><tr><td style=\”word-wrap: break-word\”> укоз<\/td><td style=\”word-wrap: break-word\”> указ<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>об <\/td><td style=\”word-wrap: break-word\”>об<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>налогах<\/td><td style=\”word-wrap: break-word\”>налогах<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>на<\/td><td style=\”word-wrap: break-word\”>на<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>растаможивании<\/td><td style=\”word-wrap: break-word\”>растаможивании<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>автомобилей<\/td><td style=\”word-wrap: break-word\”>автомобилей<\/td><\/tr><\/tbody><\/table> “,
}
]
Source references
Service page – https://corpus.by/NearestWordsFinder/
Levenshtein distance (Wikipedia article) – https://en.wikipedia.org/wiki/Levenshtein_distance