The service «Language Identifier» is designed for identification of the language of the arbitrary text submitted to the input. At the moment, the service recognizes 5 languages: Belarusian, Russian, Ukrainian, English and German.
Basic terms and concepts
«Language Identifier» (or language guessing) – a problem related to the field of natural language text processing, which consists in determining which language the content is presented in. In the framework of technologies using computational approaches, this problem is considered as a special case of text categorization and is solved by various statistical methods.
Practical value
The problem of preliminary automatic determination of the text language is faced by many modern applications that process and re-process text – for example, machine translation systems, various parsing programs and speech synthesis systems. Correct recognition of at least the main language significantly saves the resources of such systems, improves their performance, and corrects the operation of algorithms.
The solution of the problem of text language identifying is high-demand on the Internet. In particular, this concerns the identification of the user’s language, since such identification, along with geolocation technology, allows to fine-tune the site or application to the user’s needs, to make the content as clear and accessible as possible. Our service has access via the API, which makes it a good helper for the web developer.
Service features
The text language is identified by the service using the statistical method and the rule application method. The priority of statistics over rules or rules over statistics is determined by the position of a special toggle switch variable. The ability to change the position of this toggle switch is currently hidden from the user, however, if necessary, it can always be used by the developer. The sensitivity threshold of the algorithm, the minimum and maximum number of characters of the text to be processed can be just as easily changed (to ensure performance, at the moment the last two parameters are 80 and 1680 respectively).
The plans for the improvement of the service include the ability to define several languages of multilingual text and the generation of statistics on the use of each individual language, the expansion of the language palette, using of new identification rules.
Service operation algorithm
Basic algorithm
Algorithm input data:
- User text input, Text;
- Minimum text input length, MinLength. Equals 80 characters;
- Maximum text input length, MaxLength. Equals 1680 characters;
- Toggle switch variable, which is responsible for using an additional system of rules and exceptions, UseRules. Equals false;
- Toggle switch variable, which is responsible for applying only rules in the text processing (without statistics), UseRulesOnly. Equals false;
- Toggle switch variable, which is responsible for the priority of rules over statistics, UseRulesPriory. Equals true.
The beginning of the algorithm.
Step 1. Checking the condition Text = ∅. If the condition is true, end the algorithm with the result «false».
Step 2.1. Removing initial and last spaces from Text, determining the encoding of the text.
Step 2.2. If the length of the Text is more than MaxLength, remove from Text all the characters following the character with the MaxLength number. Otherwise, if the length of the Text is less than MinLength, end the algorithm with the result «false».
Step 2.3. Convert all Text characters to UTF-8 encoding characters and cast them to lowercase.
Step 3.1. If UseRulesOnly = true, apply the function of language identification according to the rules to Text, record the result of the function work to the Res variable, issue the value of the Res variable to the user and finish the algorithm. Otherwise, go to the next step.
Step 3.2. Apply the function of statistical language identification to Text, record the result of the function work to the variable Res.
Step 3.3. If UseRules = true, complete the following steps of the algorithm. Otherwise, issue the value of the variable Res to the user and finish the algorithm.
Step 3.4. Apply the function of language identification according to the rules to Text, record the result of the function work to the ResRules variable.
Step 3.5 If UseRulesPriory = true, issue the value of the ResRules variable to the user and finish the algorithm. Otherwise, issue the value of the variable Res to the user and finish the algorithm.
The end of the algorithm.
Function of language identification according to the rules
Algorithm input data:
- User text input processed in steps 2.1. – 2.3. of the basic algorithm, Text;
- Two-dimensional matrix of rules for each language, LangRules. Each row of the matrix contains a character or a combination of characters that are characteristic for a particular language;
- Toggle switch variable, responsible for the need for text to comply with all the rules in case of text language identification according to the rules, MatchAllRules. Equals true.
The beginning of the algorithm.
Step 1. Checking the conditions Text = ∅ and LangRules = ∅. If at least one of the conditions is completed, finish the algorithm with the result «false».
Step 2. For each row of the LangRules matrix, perform steps 2.1. – 2.2.
Step 2.1. Create a Freq variable for calculating the fulfilled rules (that is, cases where the desired characters or combinations of characters are found in the string) and initialize it with the value 0.
Step 2.2. For each rule Rule in each row of the LangRules matrix, perform steps 2.2.1. – 2.2.3.
Step 2.2.1. Create a Term variable and record in it the number of occurrences of a character or combination of characters that matches Rule in the Text.
Step 2.2.2. If Term > 1, increment Freq.
Step 2.2.3. If MatchAllRules = true, check if the Freq value is equal to the number of Rules for a given row of the LangRules matrix. If equal, return the name of the current row of the LangRules matrix (i.e. the name of the language) and finish the algorithm. Otherwise, check the condition Freq > 0. If the condition is true, return the name of the current row of the LangRules matrix and finish the algorithm.
Step 3. If the result did not return in step 2, finish the algorithm with the result «false».
The end of the algorithm.
The function of statistical text language identification
Algorithm input data:
- User text input processed in steps 2.1. – 2.3. of basic algorithm, Text;
- Two-dimensional matrix, each row of which contains all the characters of the alphabet of a particular language, Langs;
- Two-dimensional matrix for recording the results of the function work for each individual language, LangRes;
- Threshold of sensitivity, DetectRange. Equals 75;
- Toggle variable UseStrLenPerLang. If true, the total number of alphabet characters found in Text will be given priority over the ratio of the number of characters encountered to the total number of characters of the language alphabet, if false, then vice versa. Equals true;
- Toggle switch variable ReturnAllResults, responsible for returning the result of the analysis of all languages instead of returning the best result. Equals false.
The beginning of the algorithm.
Step 1. If Text = ∅, finish the algorithm with the result «false».
Step 2. For each Lang row of the Langs matrix, perform steps 2.1. – 2.3.
Step 2.1. Record the value 0 to the LangRes row corresponding to Lang. Create a Freq variable for the subsequent record of the number of language characters encountered in the Text one or more times and initialize it with the value 0. Create a FullLangSymbols variable for the subsequent record of the total number of occurrences of the language characters in the Text and initialize it with the value 0. Create a CurLang array and record into it all the characters of the alphabet of the current language (corresponding to Lang).
Step 2.2. For each LangItem character of the CurLang array, perform steps 2.2.1. – 2.2.2.
Step 2.2.1. Create a Temp variable and record to it the total number of occurrences of the LangItem character in Text.
Step 2.2.2. If Temp > 1, increment Freq and increase the FullLangSymbols value by Temp value.
Step 2.3. If UseStrLenPerLang = true, record the value of FullLangSymbols to the row of the LangRes matrix corresponding to the current language, otherwise record to the row of the LangRes matrix corresponding to the current language the value calculated by the formula (and rounded up):
[value] = (100 / [number of characters of the CurLang alphabet]) * Freq.
Step 3. Sort the LangRes matrix in order of descending the values recorded in step 2.3.
Step 4. If ReturnAllResults = true, return the entire LangRes matrix and finish the algorithm. Otherwise, check the condition [value of the top LangRes element] ⩾ DetectRange. If the condition is true, return the name of the language corresponding to the top row of the LangRes matrix and finish the algorithm; otherwise, return «null» and finish the algorithm.
The end of the algorithm.
User interface description
The appearance of the service interface is shown in Figure 1.
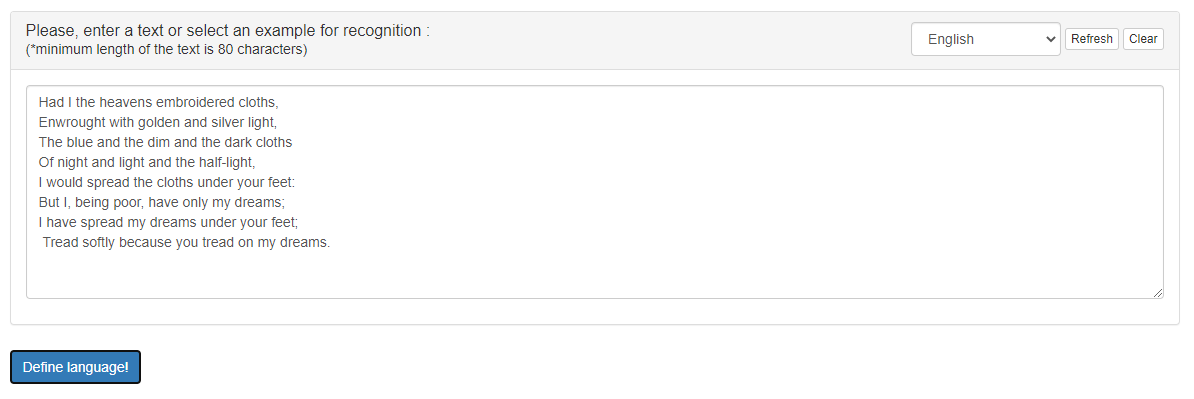
Figure 1 – Graphical interface of the service «Language Identifier»
The interface has the following areas:
- Drop-down menu for selecting test text in one of the languages;
- Input field for text for recognition. The field is equipped with the «Refresh» button (filling in according to the selected item of the drop-down menu) and «Clear» button (delete all data);
- The button «Define language!», which starts processing and allows to obtain the result.
After clicking on the button «Define language!» the field for issuing processing results appears at the bottom of the screen.
User scenarios of work with the service
Scenario 1. Identifying of the test text language
- Select a test text using the drop-down menu. In case of undesirable changes in the content of the text field, click the «Refresh» button.
- Press the button «Define language!».
- Get the result (the name of the identified language) in the field for issuing results.
Scenario 2. Identifying of the user text language
- Press the «Clear» button to clear the input field or clear the input field manually.
- Enter text in the input field.
- Press the button «Define language!».
- Get the result (the name of the identified language) in the field for issuing results.
The possible result of the service work according to the proposed scenarios is presented in Figure 2.

Figure 2 – The result of the service «Language Identifier» work
Access to the service via the API
To access the service «Language Identifier» via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/LanguageIdentifier/api.php. The following parameters are passed through the data array:
- text – any input text with length of 80 characters or more.
Example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/LanguageIdentifier/api.php”,
data:{
“text”: “Had I the heavens’ embroidered cloths,
Enwrought with golden and silver light,
The blue and the dim and the dark cloths
Of night and light and the half-light,
I would spread the cloths under your feet:
But I, being poor, have only my dreams;
I have spread my dreams under your feet;
Tread softly because you tread on my dreams.”
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with input text (text parameter) and a code of identified language (result parameter). For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “Had I the heavens’ embroidered cloths,
Enwrought with golden and silver light,
The blue and the dim and the dark cloths
Of night and light and the half-light,
I would spread the cloths under your feet:
But I, being poor, have only my dreams;
I have spread my dreams under your feet;
Tread softly because you tread on my dreams.”,
“result”: “en”
}
]
Source references
Service page – https://corpus.by/LanguageIdentifier/