The «UDC Decoder» service allows the user to receive the decoding of Universal Decimal Classification codes. The input of the service is the UDC code which must be decrypted. At the output, the user receives information on the entered code:
- class code;
- class description in English;
- class description in Belarusian.
Basic terms and concepts
UDC (Universal Decimal Classification) is a document indexing language, which is a classification system that covers all areas of human knowledge. UDC is organized as a holistic system in which all areas of knowledge are interconnected, and is designed to describe and index the content of information resources regardless of carrier, form, format and language. UDC is an analytical-synthetic and facet classification system with a detailed dictionary and syntax. This fact provides powerful indexing of information and greatly simplifies the search for information in case of its large volumes.
Practical value
Based on the database which «UDC Code Finder» service uses, a Belarusian-language edition of UDC 2016 was created. The publication contains a translation from English into Russian of the data of all UDC classes that were used in the world practice of indexing documents up to the release date.
The service will be high-demand to meet the needs of libraries, organizations that sell print media, information centers involved in the systematization of documents, organizations of document funds and electronic services for finding information.
Also, the use of the service will greatly facilitate the work of scientists engaged in the selection of literature on a specific topic for the deep study of this topic and/or writing their own works. A preliminary definition of the UDC code is a requirement often imposed on authors by journals from the lists of the Higher Attestation Commission and journals included in international abstract databases. Turning to the UDC codes allows to significantly speed up the search for material.
Service features
- In Cyrillic electronic publications, the «УДК» or «удк» inscription is often placed before the UDC digital code (probably, in some cases, it can also be placed after the code). To improve convenience, the service is configured in the way that the user can copy the entire line into the input field together with a prefix or postfix consisting of the characters «У», «Д», «К» in upper or lower case and spaces. In this case, the code will be recognized correctly.
- For each request, the service gives an unambiguous answer – information on the found UDC class or an empty output if the UDC class is not found. By the logic of its work and the logic of the structure of the UDC tables, the service should produce only one result for each case. Nevertheless, if for some reason the service manages to find several matches, it can display up to 10 positions.
- The UDC code is analyzed from the end to the beginning. If it is not possible to find anything on a specific request, the service sequentially discards one character from the end of the UDC code and tries to find something according to the received combination. This means that, for example, nothing will be found by request «4» (currently there are no classes in the UDC tables whose code begins with this character), but by request «04» the class corresponding to code «0» will be found.
Service operation algorithm
Algorithm input data:
- User input, UserUDC;
- Symbols of prefixes and postfixes for deletion, TrimSymbols (characters «У», «Д», «К» in upper and lower case and a space);
- A set of found entries in the database table, Found;
- A set of results, Result.
The beginning of the algorithm.
Step 1.1. Bringing user input UserUDC into a form suitable for processing, and recording treated UserUDC to the SearchData variable. To do this in UserUDC all characters belonging to TrimSymbols are deleted from the beginning and the end. Creating Rest variable for recording SearchData characters to it.
Step 1.2. Creating FoundCount variable for subsequent recording of the number of elements found, Step1=0 variable for counting the number of completed records in the Result set in case of the initial exact match, Step2=0 variable for counting the number of completed records in the Result set in case of the subsequent exact match, and also Length variable, in which the number of SearchData characters is recorded.
Step 2.1. Querying the database: search in the UDC table for all occurrences where SearchData exactly matches the value of the Notation field. If the data is found, record it into the Found set, each element of which consists of the fields Notation (UDC code), English (data from the English version of UDC), Belarusian (data from the Belarusian version of UDC), and perform steps 2.1.1. – 2.1.2. If not, go to step 2.2.
Step 2.1.1. Record the total number of items found in the FoundCount variable.
Step 2.1.2. Record of the triple <Found.Notation[Step1], Found.English[Step1], Found.Belarusian[Step1]> in the Result set. If Step1 < FoundCount, increment Step1 and perform step 2.1.2 again, if not, go to step 3.
Step 2.2. If Rest ≠ ∅, clear Rest. Record in Rest as many SearchData characters (from the beginning) as big the value of the Length variable is currently. If Length = 0, go to step 3.
Step 2.3. Querying the database: search in the UDC table for all occurrences where Rest matches exactly the value of the Notation field. If the data is found, record it to the Found set, each element of which consists of the Notation, English, Belarusian fields, and perform steps 2.3.1. – 2.3.2. If not, decrement Length and go to step 2.2.
Step 2.3.1. Record the total number of items found in the FoundCount variable.
Step 2.3.2. Record of the triple <Found.Notation[Step2], Found.English[Step2], Found.Belarusian[Step2]> in the Result set. If Step2 < FoundCount, increment Step2 and perform step 2.3.2 again, if not, go to step 3.
Step 3. Displaying the content of the Result set in a special format.
The end of the algorithm.
User interface description
The user interface of the service is shown in Figure 1.

Figure 1 – The graphical interface of the service «UDC Decoder»
The interface contains the following areas:
- UDC code entry field;
- the «Search result!» button, which starts processing and makes it possible to obtain results in the output field.
After processing the code by the service, the user receives the following lists of information in the output field:
- class code;
- class description in English;
- class description in Belarusian.
User scenarios of work with the service
Scenario 1. Search by manually entered code.
- Enter the code.
- Click the «Search result!» button.
- Get information.
Scenario 2. Search by code copied from an electronic source.
- Copy the code from the electronic source into the input field. It is possible to copy the code with the «УДК» prefix or postfix.
- Click the «Search result!» button.
- Get information.
A possible result of the service work is presented in Figure 2.
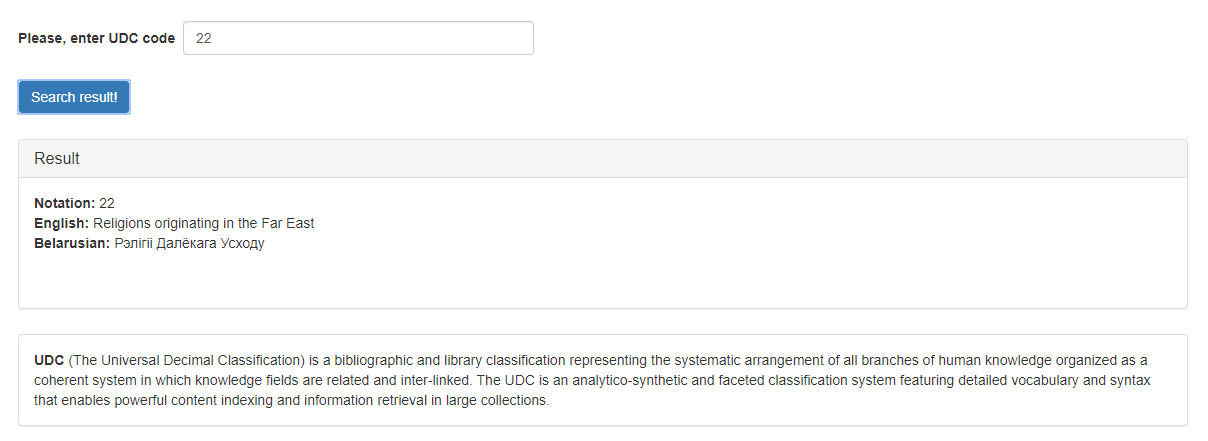
Figure 2 – The result of the service «UDC Decoder» work
Access to the service via the API
To access the «UDC Decoder» service via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/UdcDecoder/api.php. The following parameters are passed through the array:
- text – UDC code.
Example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/UdcDecoder/api.php”,
data:{
“text”: “811.161.3”
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with the following parameters:
- text – input text – UDC code;
- notation – the final code of UDC;
- english – decoding in English;
- belarusian – decoding in Belarusian;
- noresult – formulation in case of the absence of results.
For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “811.161.3”,
“notation”: “811.161.3”,
“english”: “Belarusian language”,
“belarusian”: “Беларуская мова”,
“noresult”: “”
}
]
Source references
Service page: https://corpus.by/UdcDecoder/?lang=be
UDC Consortium website: https://www.udcc.org/
UDC tables in Belarusian: https://www.udcsummary.info/php/index.php?lang=be&pr=Y
Cross references
- Драгун, А. Я. Аўтаматызаваныя сродкі атрымання расшыфроўкі і спісаў кодаў беларускамоўнай Універсальнай дзесятковай класіфікацыі / А. Я. Драгун, Я. С. Зяноўка, М. С. Галаўчак, С. С. Маеўскі, Ю. С. Гецэвіч // Материалы VII Международного конгресса «Библиотека как феномен культуры» : Краеведение и страноведение в сохранении культурного разнообразия, Минск, 21–22 октября 2020 г. / Национальная библиотека Беларуси ; [сост.: Т. В. Кузьминич, А. А. Суша]. – Минск, 2020. – С. 300-306.
- Захарьев, В.А. Алгоритм текстонезависимого обучения для систем мультиголосового синтеза речи / В.А. Захарьев, А.А. Петровский // Информационные технологии и системы (ИТС-2016) / БГУИР ; редкол. : Л.Ю. Шилина [и др.]. — Минск : БГУИР, 2016. — C. 90-91.
- Гецэвіч, Ю.С. Беларускамоўнае выданне УДК: склад і асноўныя этапы падрыхтоўкі / Ю.С. Гецэвіч, А.М. Скопінава, Т.І. Окрут, Г.Р. Станіславенка // Інструментарый індэксатара і яго прымяненне ў бібліятэках Беларусі / Нацыянальная бібліятэка Беларусі ; пад рэд. Кузьмініч Т.В. — Мінск : БібліяКансультант, 2016. — C. 27-34.
- Станиславенко, А.Г. Этапы подготовки первого издания УДК на беларусском языке / А.Г. Станиславенко, С.И. Лысы, Ю.С. Гецевич // Информация в современном мире : доклады Международной конференции, Москва, 25-26 октября 2017 г. / ВИНИТИ РАН. — Москва : ВИНИТИ РАН, 2017. — C. 297-303.