The Lemmatizer service is designed to determine the initial forms of words. It receives an arbitrary text in Belarusian or Russian. The result of the service is a list of words of the input text with their initial forms, as well as a list of words whose initial form could not be determined. The general view in which the result will be presented can be customized according to the needs of the user.
Basic terms and concepts
Lemma (in linguistics) – the nominal (vocabulary, basic, canonical) form of a word. Lemmas are used in dictionaries as headwords, after which other forms of the lexeme can be listed. In the Russian and the Belarusian languages the following morphological forms are considered normal:
- for nouns – nominative case, singular;
- for adjectives – nominative case, singular, masculine;
- for verbs, participles, adverbial participles – a verb in an infinitive of imperfect form.
Lemmatization is the process of reducing a word form to its initial form (lemma).
The full search method is a way of finding a problem solution by exhausting all possible options. The service «Lemmatizer» uses one of the types of brute force search – dictionary enumeration.
Practical value
The lemmatization method is used in search algorithms during web document schematization and indexation. Despite the high technological level of modern search engines, such processing is not always accurate, since the search robot often takes into account only one of the possible lemmas of the word form given in the document text. Therefore, the further development of lemmatization methods, to which our service is designed to contribute, is a prioritized technological task.
Also, at the moment we have not found any full-fledged Belarusian search engines on the Internet (even the search engine of the popular portal tut.by uses Yandex algorithms). The development of the national information industry, a special case of which can be the creation of domestic search engines (which will use lemmatizer in any case), is part of the Informatization Development Strategy in the Republic of Belarus.
The use of lemmatization significantly improves the quality of the sites and documents analysis. If in the commercial sphere (for example, to facilitate the finding of goods and services on the Internet, as well as to promote them), high-quality lemmatization will be one of the «ordinary» advantages for processing documents of medical, legal, and various technological domains, this obstacle is critically important. The lemmatization systems for Russian texts are developed quite well today, while for the Belarusian language the situation looks different. Many works of Belarusian scientists are available to readers in the Belarusian language. Correct lemmatization of both the main texts and supporting data (article titles, information about authors, bibliographies) can be successfully applied in the libraries’ activity.
Special cases of lemmatization use can be criminalistic linguistic examination, analysis of texts for plagiarism, analysis of the writer texts language, analysis of electronic educational texts and electronic texts generated by students in adaptive learning systems.
Service features
In computer linguistics, lemmatization is often defined as a method of morphological analysis, under which all flectional elements that do not correspond to the initial form of the word should be discarded from the lexeme. To obtain auxiliary data, particularly, to determine the standard structure of the initial word form of a certain part of speech, the lemmatization system can use a dictionary search.
At the moment, the dictionary search method is the only solution that the service uses. The complete list of dictionaries that are used is given below:
- sbm1987 – «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / падрэд. М.В. Бірылы. – Мінск, 1987».
- noun2013 – nouns according to the edition «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013».
- adjective2013 – adjectives according to the edition«Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск :Беларус. навука, 2013».
- numeral2013 – numerals according to the edition«Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск :Беларус. навука, 2013».
- pronoun2013 – pronouns according to the edition «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск :Беларус. навука, 2013».
- verb2013 – verbs according to the edition«Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск :Беларус. навука, 2013».
- adverb2013 – adverbs according to the edition «Граматычныслоўнікпрыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск :Беларус. навука, 2013».
- zalizniak – «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. – Москва : Русский язык, 1980. – 880 c.».
The indicated Russian and Belarusian editions are authoritative enough to be used in the lemmatization process. This fact gives a certain advantage: for example, forms like «піла» will be recognized by the service as forms of different parts of speech («піла» as a noun and «піла» as a verb). Many homographs («це́лую – целый» and «целу́ю – целовать»), word forms formed by zero suffixation («удар») also will be recognized.
Nevertheless, the degree of the dictionaries completeness and the specifics of information distribution in their electronic copies give rise to some inaccuracies in text processing. A detailed analysis of the service work has been revealed the following problems:
- Proper names are not lemmatized.
- Many loan words («рэлаксацыя», «такенізацыя», «шугарынг») are not lemmatized, especially in cases when such loans are equipped with prefixes or suffixes. Nevertheless, some borrowings (for example, «ідэнтыфікацыя», «дэпрывацыя») can be lemmatized if they do not have such morphemes.
- Most of the words with suppletive stems are not lemmatized. This applies to some adjectives of degrees of comparison («добры – лепшы», «хороший – лучший»), some nouns («чалавек – людзі»), verbs («класціся – легчы»). The pronouns («мы – нас», «я – мяне») in most cases (although not in all) will be lemmatized.
- Many words that have two or more roots («чорна-зялёны»), as well as lexemes with appositions («чалавек-амфібія»), usually are not lemmatized, although some of these words can be lemmatized.
- Words with diminutive and magnificently dismissive suffixes («сильненький», «городишко») also will not be lemmatized in many cases. This is especially true for the Russian language. For the Belarusian language, a part of such word forms («цёпленькі», «гарадочак») will be processed as if they were independent lexemes.
- In many cases, the names of young creatures («качаня», «жарабя») will cause difficulties.
- Many adverbs with the prefix «па» (Russian «по») and the suffix «у» will be marked by the service as unknown («па-афганску»), although, in principle, such words do not need to be lemmatized, since they are unchangeable.
- For the Russian language, participles and adverbial participles are reduced not to a verb, but to their «initial word form» («сделавши – сделав», «убоявшихся – убоявшийся»). For the Belarusian language, in a similar situation, the result of processing depends on the dictionaries chosen by the user.
- For the Belarussian language, synthetic forms of degrees of comparison («мацнейшы», «найпрыгажэйшы») in general case will be reduced not to the initial form of the adjective, but the nominative case of the singular masculine form, as if the forms of degrees of comparison were independent adjectives. For the Russian language, synthetic forms of degrees of comparison («сильнейший», «наимощнейший») will not be lemmatized.
- All word forms created analytically («самы прыгожы», «зрабіў бы») are considered by the service as a set of separate words and will be processed accordingly.
Many of the above problems are solved by introducing a morphological analysis after the dictionary analysis. Therefore, the development and implementation of morphological analysis rules is a prioritized task for service development.
Service operation algorithm
Basic algorithm
Algorithm input data:
- User text input, UText;
- User input of known lemmas, UserWords;
- User selection of output format, Format;
- The value of the option responsible for displaying dictionaries in which the word form was found, ShowDictionaryNames;
- A character or combination of characters that is used as a delimiter, Delimiter;
- User selection of dictionaries that are involved in processing, Dictionaries.
The beginning of the algorithm
Step 1. Split Text into the paragraphs array ParagraphsArr by line feed character.
Step 2. For each Paragraph in ParagraphstArr, perform steps 2.1. – 2.2.
Step 2.1. Remove initial and last spaces from Paragraph.
Step 2.2 If Paragraph ≠ ∅, process Paragraph via the paragraph processing function. The result is written to the associative token arrayTokensArray. Another processing result is the KnownWords associative array.
Step 3. If Token Array ≠ ∅, perform steps 3.1. – 3.3.
Step 3.1 Formation of an associative array of unique words UniqueWords. For each Token in TokenArray, check whether the value by the Type key is equal to Word and the value by the WritingSystem key is equal to Cyrillic. If the condition for a specific Token is correct, create a Word variable and initialize it with a Token entity element for the Normalized key, from which all the «+» and «=» characters (acute and grave accent characters) are removed. Next, check the following conditions:
- If a lexeme in KnownWords is similar to a Token entity element for the Normalized key. If so, add in UniqueWords for Word by the Known key an associative array, in which the Accent key corresponds to the Token entity element by the Normalized key, and the Initial key corresponds to the same element found in KnownWords, then proceed to process the next Token or, if the last Token is reached, go to step 3.2.
- If a lexeme in KnownWords is similar to Word. If so, add in UniqueWords for Word by the Known key an associative array, in which Word matches the Accent key and the Initial key matches the same element found in KnownWords, then proceed to process the next Token or, if the last Token is reached, go to step 3.2.
If none of these conditions is completed, add an empty array to UniqueWords for Word.
Step 3.2. Determine the initial form of all words in the source text (where possible) via the initial forms determining function.
Step 3.3. Form the result of the service work via the result formation function.
Step 4. Present the result of the service work to the user.
The end of the algorithm.
Paragraph processing function
Algorithm input data:
- A paragraph obtained by the splitting of UText, Paragraph;
- A set of characters that can make up a word, Letters. This set consists of the main Cyrillic and Latin characters;
- A set of the Russian alphabet characters, LettersRus;
- Set of the Belarusian alphabet characters, LettersBel;
- Set of Latin characters (characters of the English alphabet), LettersLat;
- Set of all possible characters of the apostrophe, ApostrophesArr;
- Set of the acute accent characters, AcuteAccentsArr;
- Set of the grave accent characters, GraveAccent;
- Set of linking symbols, Linking;
- User-defined delimiter value, UserDelimiter;
- An empty array for recording tokens, TokensArray.
The beginning of the algorithm.
Step 1. Create the MainChars variable and record all Letters characters into it. Create the AdditionalChars variable and record into it all the AcuteAccentsArr, ApostrophesArr, GraveAccent, Linking characters, as well as the characters «=», «+», «-».
Step 2. Create the WordsArr array and record into it all Paragraph elements that match the pattern [<Character ofMainChars> + <0 or more characters of MainChars and AdditionalChars> + <0 or more characters of MainChars>] (other Paragraph elements are discarded and do not participate in further processing). Each resulting element of the WordsArr array will be an array in whose cells the word and delimiter UserDelimiter are recorded separately.
Step 3. For each WordArr in WordsArr, perform steps 3.1. – 3.3.
Step 3.1. Create a Word variable and record the value of the WordArr cell corresponding to the word into it. Create a Delimiter variable and record the value of the WordArr cell corresponding to the delimiter into it.
Step 3.2. Word Normalization. If Word ≠ ∅, check if any character from the LettersLat set appears at least once in Word. If it does, check also if Word contains any character from the LettersRus and LettersBel sets. If yes, then record in TokensArray an associative array in which the Word value corresponds to the Initial key, the Normalized key corresponds the Word value processed by the token normalization function*, the Type key corresponds the string «word», the WritingSystem key corresponds the string«mixed». If not, then record a similar array to TokensArray, but in which the WritingSystem key corresponds to the value «Latin». If the characters from LettersLat never occur in Word, record a similar array to TokensArray, but in which the WritingSystem key corresponds to the value «Cyrillic».
* The token normalization function sequentially performs the following actions:
- Bringing the token to lower case;
- Replacing all characters from the ApostrophesArr set with the character «’»;
- Replacing all characters from the GraveAccentset with the character«=»;
- Replacing all characters from the AcuteAccentsArr set with the character «+».
Step 3.3. Delimiter Normalization. Check conditions Delimiter ≠ ∅ and Delimiter ≠ «space». If both conditions are carried out, check whether at least part of the Delimiter matches the pattern [<1 non-space character or more> OR <1 space character or more>]. If this condition is also fulfilled, record all matches with the template to the Matches array, create a Cnt variable and record the number of elements of the Matches array into it, then for I = 0; I <Cnt; I++ perform steps 3.3.1. – 3.3.2.
Step 3.3.1. If Matches[I] ≠ ∅, increment I and check the condition Matches[I] ≠ ∅ again.
Step 3.3.2. If I = 0 or I = Cnt– 1, and for performing any of these conditions Word ≠ ∅, split Matches[I] into an array of Chars characters and for each Char in Chars record in TokensArrayan associative array in which the Initial key corresponds to Char, the Normalized key corresponds to the Char value processed by the token normalization function, the Type key corresponds the string value «p». If both of the first conditions are not met, record in TokensArrayan associative array in which the Initial key corresponds to Matches[I], the Normalized key corresponds to the Matches [I] value processed by the token normalization function, and the Type key corresponds to the string value «p».
Step 4. Record in TokensArrayan associative array in which the Initial key corresponds to the string value «\n», the Normalized key corresponds to the string value «newline», and the Type key corresponds to the string value «p».
The end of the algorithm.
Initial forms determining function
Algorithm input data:
- An array of unique words is formed in the main algorithm, UniqueWords;
- A variable for counting the number of database queries, QueryCnt. Initially equals to 0.
- A variable that determines the limit of database queries, QueryLimit. Equals to 100.
- A variable for counting processed unique words, UniqueWordsCnt. Initially equals to 0.
- The UniqueWordsTotal variable is equal to the number of unique words in UniqueWords.
- An empty array QueryWordsArr for a subsequent recording of words that will be used to query databases of dictionaries.
- A collection of user-selected dictionaries, Dictionaries.
The beginning of the algorithm.
Each step of this algorithm is performed for each UniqueWord in UniqueWords.
Step 1. If QueryCnt ⩽ QueryLimit and UniqueWordsCnt ≠ UniqueWordsTotal, replace in the current UniqueWord all the initial characters «Ў» and «ў» with the characters «У» and «у» respectively, remove all the characters «=» and «+» from UniqueWord, write the string «word=’/UniqueWord/’» in QueryWordsArr (necessary for the subsequent generation of the correct query to the database), and then increment QueryCnt and UniqueWordsCnt.
Step 2. If QueryCnt>QueryLimit or UniqueWordsCnt = UniqueWordsTotal, perform the next steps of the algorithm, otherwise go to the next UniqueWord and start the algorithm again.
Step 3. Create a QueryWords variable and record the values of all QueryWordsArr elements separated by the combination <«space» + or + «space»>into it.
Step 4. If QueryWords ≠ ∅, for each Dictionary in Dictionaries perform steps 4.1. – 4.2.
Step 4.1 Generate a Query string of the form «SELECT * FROM s1 WHERE s2», where s1 = Dictionary, s2 = QueryWords.
Step 4.2. If the program managed to find anything in the current Dictionary by Query, then until the query results can be written line-by-line into the Row variable created for this (that is, until the results are exhausted), perform steps 4.2.1. – 4.2.4., and then release the system resources from the results gained via Query.
Step 4.2.1. Bring the value of the Row[Word] element to lowercase. Create an Initial variable and initialize it with a value of «невядомаеСлова».
Step 4.2.2. If Row[LexemeId] ≠ ∅, form a Query2 query string of the form «SELECT * FROM s WHERE lexemeId = d LIMIT 1», where s = Dictionary, d = Row[LexemeId]. If it is possible to find something in the current Dictionary by this query, then until the query results can be written line-by-line into the Row2 variable created for this, reinitialize Initial with the value Row2[Word] reduced to lower case. As soon as the final reinitialization has been completed, release the system resources occupied by results gained via Query2.
Step 4.2.3. If Row[Initial] ≠ ∅, form a Query3 query string of the form «SELECT * FROM s WHERE initial = d LIMIT 1», where s = Dictionary, d = Row[Initial]. If it is possible to find something in the current Dictionary by this query, then until the query results can be written line-by-line into the Row3 variable created for this, reinitialize Initial with the value Row3[Word] reduced to lower case. Once the final reinitialization has been completed, release the system resources occupied by the results gained via Query3.
Step 4.2.4. Record in UniqueWords for the Row[Word] element, which corresponds to the current Dictionary, an associative array in which the Accent key corresponds to the Row[Accent] value, and the Initial key corresponds to the value of the variable with the same name. Moreover, if Row[Word] begins with the character «у», and in the source text the corresponding word began with «ў», replace the initial characters «у» with «ў» in Row[Word] and Row[Accent].
Step 5. Clear the QueryWordsArr and reset the QueryCnt to perform the next iteration.
The end of the algorithm.
Result formation function
Algorithm input data:
- Associative arrays TokensArray and UniqueWords with the results of previous processing;
- An empty array UnknownWordsArr for a subsequent recording of unknown words and data about them;
- An empty UnknownWords variable for a subsequent recording of unknown words in string form;
- Empty variable Result;
- A set of punctuation marks Punctuation;
- A variable containing the user delimiter, LocalDelimiter;
- The user value of the option responsible for displaying the titles of dictionaries, DictionaryNamesFlag;
- Variables GeneralDelimiter and MediumDelimiter, necessary for the formation of the final result according to the user requirements.
| The values of the variables GeneralDelimiter and MediumDelimiter depending on the option chosen by the user | ||
| Option | GeneralDelimiter | MediumDelimiter |
| «Show result in source format» | «space» | ∅ |
| «Show the whole result in one row» | «space» | ∅ |
| «Show the result in rows» | \n* | ∅ |
| «Show the result in column» | \n\n | \n |
*\n – line feed character
The beginning of the algorithm.
Each step of this algorithm is performed for each Token in TokensArray.
Step 1. If Token [Type] = «word» (i.e. the token is a word), perform steps 1.1. – 1.3.
Step 1.1. If Token[WritingSystem] = «cyrillic», perform steps 1.1.1. – 1.1.2.
Step 1.1.1. If the symbol «+» or «=» is present in Token[Normalized] (i.e. there is an accent character in the word), perform steps 1.1.1.1. – 1.1.1.3.
Step 1.1.1.1. Create a Word variable and write the Token[Normalized] value with the accented characters removed from it.
Step 1.1.1.2. If UniqueWords[Word] ≠ ∅ (i.e. if a word was found in user-defined dictionaries) perform steps 1.1.1.2.1. – 1.1.1.2.2.
Step 1.1.1.2.1. If DictionaryNamesFlag = true, create an associative array LocalResultsArrand for each pair «key = DictionaryName, value = DictionaryResults» in UniqueWords[Word] and check the following conditions for each UniqueWordResultsArr in DictionaryResults:
- Token[Normalized] is equal to UniqueWordResultsArr[Accent];
- Token[Normalized] with the removed characters «=» and «+» is equal to UniqueWordResultsArr[Accent];
- Token[Normalized] with «=» characters replaced by «+» characters is equal to UniqueWordResultsArr[Accent];
- Token[Normalized] with removed characters «=» is equal to UniqueWordResultsArr[Accent];
If at least one of the conditions is fulfilled, add a line of the form <UniqueWordResultsArr[Accent] + LocalDelimiter + UniqueWordResultsArr[Initial] + LocalDelimiter + DictionaryName> to LocalResultsArr, then remove duplicate values from LocalResultsArr and add to Resulta string of the form <Token [Initial] + MediumDelimiter + LocalDelimiter + [the values of the LocalResultsArr array separated by the combination «MediumDelimiter + LocalDelimiter» and connected in a string]>.
Step 1.1.1.2.2. If DictionaryNamesFlag = false, create an associative array LocalResultsArr, then for each DictionaryResults in UniqueWords[Word] and for each UniqueWordResultsArr in DictionaryResults check conditions similar to conditions described in step 1.1.1.2.1., and if at least one of the conditions is carried out, a set the value of LocalResultArr[UniqueWordResultsArr[Accent]][UniqueWordResultsArr[Initial]] is equal to 1. After that, add a string of the form <Token[Itinial] + MediumDelimiter> to Result and for each pair «key = Accent, value = Initials» in LocalResultsArrr add to Result a string of the form <LocalDelimiter + Accent + LocalDelimiter + [a set of the Initials array keys separated by LocalDelimiter and connected into a string] + MediumDelimiter>.
Step 1.1.1.3. If UniqueWords[Word] = ∅ (i.e. the word was not found in the dictionaries connected by the user), add to Result a string of the form <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «НевядомаеСлова»>, add to UnknownWordsa string of the form <Token[Initial] + [line feed character]>, make the value of the UnknownWordsArr array element corresponding to Token[Initial] equal to 1.
Step 1.1.2. If the «+» or «=» characters are not present in Token[Normalized] (i.e. there is no accent character in the word), create a Word variable equal to Token[Normalized] and perform steps similar to steps 1.1.1.2. – 1.1.1.3. – with the difference that in steps similar to 1.1.1.2.1. and 1.1.1.2.2., instead of the four described conditions, the only condition UniqueWordResultsArr[Accent] ≠ ∅ is checked.
Step 1.2. If Token[WritingSystem] = «latin», add to Result a string of the form <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «ЗамежнаеНевядомае»>.
Step 1.3. If Token[WritingSystem] = «mixed», add to Result a string of the form <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «ЗмешанаеНапісанне»>.
Step 2. If Token[Type] = «p» (i.e. the token is a delimiter), perform steps 2.1. – 2.5.
Step 2.1. If Token[Normalized] = «^», add to Result a string of the form <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized]>.
Step 2.2. If Token[Normalized] ∈ Punctuation (i.e. the delimiter is a punctuation mark), add to Result a string of the form <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «ЗнакПрыпынку»>.
Step 2.3. If Token[Normalized] = «newline», add to Result a string of the form <MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «ПераводРадка»>. If the user has selected the option «Show result in source format», add a line feed character to Result.
Step 2.4. If Token[Normalized] with the removed initial and last indent characters is equal to anything except ∅, add to Result a string of the form <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «НевядомаяКатэгорыя»>.
Step 2.5. If none of the conditions in steps 2.1. – 2.4. is completed, proceed to process the next Token.
Step 3. Add a string of the form <Result + LocalDelimiter + MediumDelimiter> with removed initial and last spaces to the final result of the function’s operation, and then add GeneralDelimiter. Proceed to process the next Token or, if the last Token has already been processed, finish the algorithm.
The end of the algorithm.
User interface description
The interface of the service is shown in Figure 1.
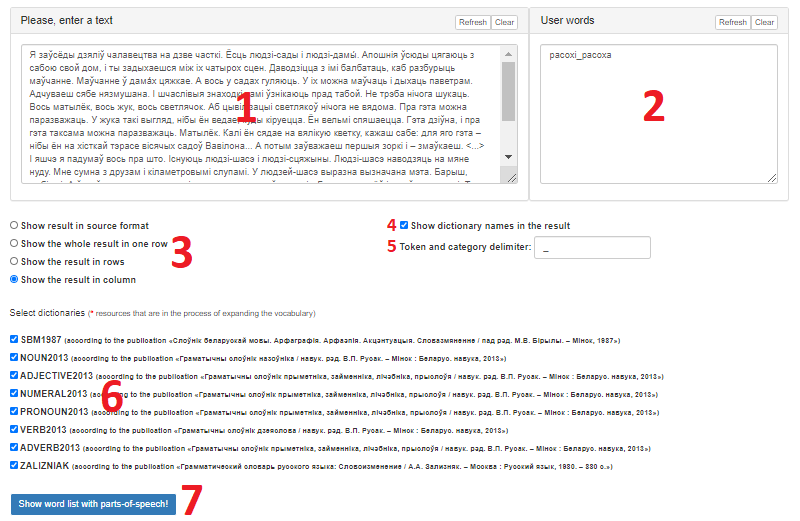
Figure 1 – Graphical interface of the service «Lemmatizer»
The interface has the following areas:
- The input field for text processing. Equipped with the buttons «Refresh» (return default data) and «Clear» (delete all data);
- A field for entering known words. It is applied to add words, the initial form of which is known to the user (and possibly unknown to the service) in the format [<word form> + <delimiter> + <initial word form>]. The field is equipped with the «Refresh» and «Clear» buttons;
- An area for selecting the format of the service results. It contains the following options: «Show result in source format», «Show the whole result in one row», «Show the result in rows», «Show the result in column»;
- The option responsible for displaying the titles of the dictionaries where each lemma was found;
- A field for specifying delimiter;
- The area of selection the dictionaries to be involved in processing;
- The button «Show word list with parts-of-speech!» which starts processing and allows getting the result.
After pressing the button «Show word list with parts-of-speech!» two fields containing the processing results will appear at the bottom of the screen:
- The «Words with parts-of-speech» field, which displays the word forms, their lemmas and the dictionaries were the lemmas were found (if the user has activated the corresponding option) in the format selected by the user;
- The «Unknown words» field that contains words that the service failed to process.
User scenarios for working with the service
Scenario 1. Processing with output in the original format.
- Enter the text for processing in the text input field.
- Enter the character or combination of characters that will be used as the delimiter in the delimiter specifying field.
- Enter known lemmas in the format [<word form> + <delimiter> + <initial word form>].
- In the area for selecting the format of the service results, select the option «Show result in source format».
- Determine the need to display the titles of the dictionaries where lemmas were found via the appropriate option.
- Select the dictionaries that will be involved in the processing in the dictionary selection area.
- Press the button «Show word list with parts-of-speech!».
- Obtain the processing result (word forms and their lemmas, and a list of words unknown to the service) in the fields that appear at the bottom of the screen.
The possible result of the service work according to this scenario is presented in Figure 2.
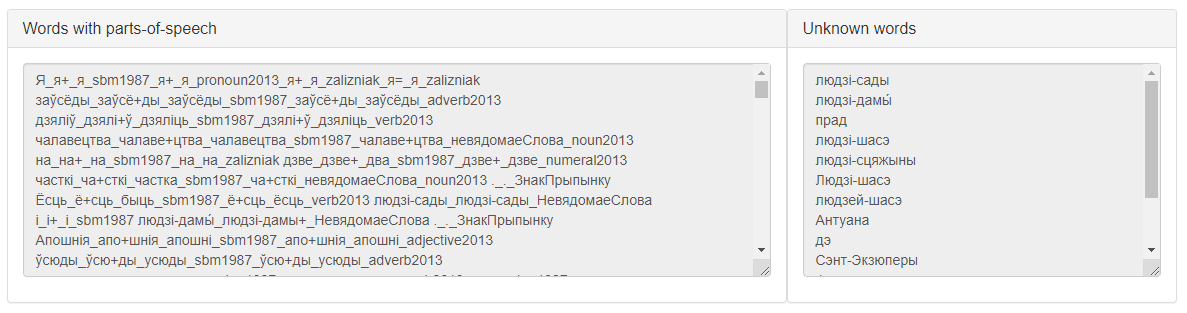
Figure 2 – The result of the service «Lemmatizer» work according to scenario 1
Scenario 2. Representation of processed results in a row, rows or column
- Enter the text for processing in the text input field.
- Enter the character or combination of characters that will be used as the delimiter in the delimiter specifying field.
- Enter known lemmas in the format [<word form> + <delimiter> + <initial word form>].
- Select one of the following options depending on the specific need in the area for selecting the format of the service results: «Show the whole result in one row», «Show the result in rows», «Show the result in column».
- Determine the need to display the titles of the dictionaries where lemmas were found via the appropriate option.
- Select the dictionaries that will be involved in the processing in the dictionary selection area.
- Press the button «Show word list with parts-of-speech!».
- Obtain the processing result (word forms and their lemmas, and a list of words unknown to the service) in the fields that appear at the bottom of the screen.
A possible result of the service work according to this scenario is presented in Figure 3.
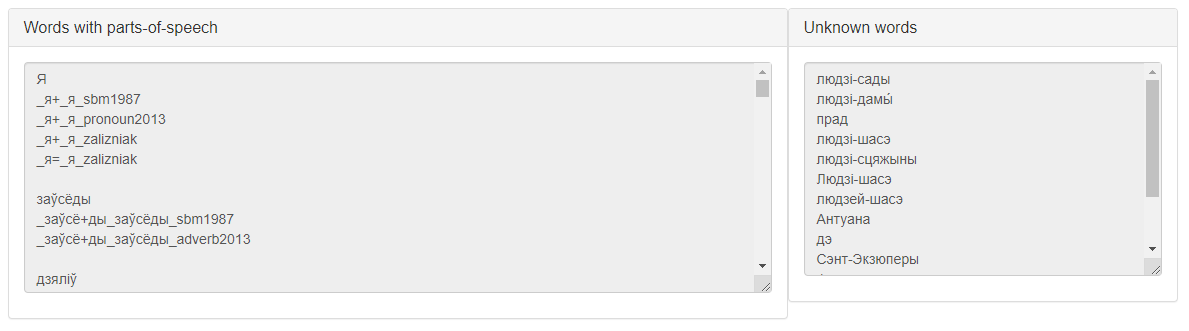
Figure 3 – The result of the service «Lemmatizer» according to scenario 2
Access to the service via the API
To access the «Lemmatizer» via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/Lemmatizer/api.php. The following parameters are passed through the data array:
- text – an arbitrary input text in Belarusian or Russian.
- knownList – a list of words with user-defined initial forms.
- localDelimiter – summary information delimiter which is a character that will separate the word, its initial form and the name of the dictionary in the final list.
- dictionaryNames – a marker for indicating the dictionaries from which information was taken.
- horizontalFormat – a marker for displaying all the summary information in one line; if it is not marked, then the information for each word will be placed in separate lines.
- Markers for dictionaries using:
-
- sbm1987 – «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / падрэд. М.В. Бірылы. – Мінск, 1987».
- noun2013 – nouns according to the edition «Граматычныслоўнікназоўніка / навук. рэд. В.П. Русак. – Мінск :Беларус. навука, 2013».
- adjective2013 – adjectives according to the edition «Граматычныслоўнікпрыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013».
- numeral2013 – numerals according to the edition «Граматычныслоўнікпрыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013».
- pronoun2013 – pronouns according to the edition «Граматычныслоўнікпрыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013».
- verb2013 – verbs according to the edition «Граматычныслоўнікдзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013».
- adverb2013 – adverbs according to the edition «Граматычныслоўнікпрыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск :Беларус. навука, 2013».
- zalizniak – «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. – Москва : Русский язык, 1980. – 880 c.».
Example ofAJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/Lemmatizer/api.php”,
data:{
“text”: “Груша цвіла апошні год. Усе галіны яе, усе вялікія расохі, да апошняга пруціка, былі ўсыпаны буйным бела-ружовым цветам.”,
“knownList“: “расохі_расоха”,
“localDelimiter”: “|”,
“dictionaryNames”: 1,
“horizontalFormat”: 0,
“sbm1987”: 1
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with input text (parameter text), a final list of words with information about their initial forms (parameter result) and a list of words unknown to the service (parameter unknownWords). For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “Груша цвіла апошні год. Усе галіны яе, усе вялікія расохі, да апошняга пруціка, быліўсыпаны буйным бела-ружовым цветам.”,
“result”: “гру+ша|груша|sbm1987
цвіла+|цвісці|sbm1987
апо+шні|апошні|sbm1987|апо+шні|апошні|sbm1987
го+д|год|sbm1987|го+д|год|sbm1987
.|ЗнакПрыпынку
усе+|увесь|sbm1987|усе+|увесь|sbm1987
галі+ны|галіна|sbm1987|галі+ны|галіна|sbm1987|галі+ны|галіна|sbm1987|галіны+|галіна|sbm1987|галі+ны|галіна|sbm1987|галі+ны|галіна|sbm1987
яе+|ён|sbm1987|яе+|ён|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987
,|ЗнакПрыпынку
усе+|увесь|sbm1987|усе+|увесь|sbm1987
вялі+кія|вялікі|sbm1987|вялі+кія|вялікі|sbm1987
расохі|расоха|known
,|ЗнакПрыпынку
да+|да|sbm1987|да+|да|sbm1987
апо+шняга|апошні|sbm1987|апо+шняга|апошні|sbm1987|апо+шняга|апошні|sbm1987
пруціка|НевядомаеСлова
,|ЗнакПрыпынку
бы+лі|быль|sbm1987|бы+лі|быль|sbm1987|бы+лі|быль|sbm1987|бы+лі|быль|sbm1987|бы+лі|быль|sbm1987|былі+|быць|sbm1987
ўсы+паны|усыпаны|sbm1987|ўсы+паны|усыпаны|sbm1987|ўсы+паны|усыпаны|sbm1987|ўсы+паны|усыпаны|sbm1987
буйны+м|буйны|sbm1987|буйны+м|буйны|sbm1987|буйны+м|буйны|sbm1987|буйны+м|буйны|sbm1987|буйны+м|буйны|sbm1987
бе=ла-ружо+вым|бела-ружовы|sbm1987|бе=ла-ружо+вым|бела-ружовы|sbm1987|бе=ла-ружо+вым|бела-ружовы|sbm1987|бе=ла-ружо+вым|бела-ружовы|sbm1987|бе=ла-ружо+вым|бела-ружовы|sbm1987
цве+там|цвет|sbm1987|цве+там|цвет|sbm1987
.|ЗнакПрыпынку”,
“unknownWords”: “пруціка”
}
]
Source references
Service page – https://corpus.by/Lemmatizer/