Сэрвіс «Расшыфроўка УДК» дазваляе карыстальніку атрымаць расшыфроўку кодаў Універсальнай дзесятковай класіфікацыі. На ўваход сэрвісу падаецца код УДК, які патрэбна расшыфраваць. На выхадзе карыстальнік атрымлівае інфармацыю па ўведзеным кодзе:
- код класа;
- апісанне класа па-англійску;
- апісанне класа па-беларуску.
Асноўныя тэрміны і паняцці
УДК (Універса́льная дзесятко́вая класіфіка́цыя) – гэта мова індэксавання дакументаў, якая ўяўляе сабой сістэму класіфікацыі, што ахоплівае ўсе галіны чалавечых ведаў. УДК арганізавана як цэласная сістэма, у якой усе галіны ведаў звязаны паміж сабой, і прызначана для апісання і індэксавання зместу інфармацыйных рэсурсаў незалежна ад носьбіта, формы, фармату і мовы. УДК уяўляе сабой аналітыка-сінтэтычную і фасетную сістэму класіфікацыі з падрабязным слоўнікам і сінтаксісам, што забяспечвае моцную індэксацыю інфармацыі і значна спрашчае пошук інфармацыі пры вялікіх яе аб’ёмах.
Практычная каштоўнасць
На падставе базы дадзеных, да якой звяртаецца сэрвіс «Расшыфроўка УДК», створана беларускамоўнае выданне УДК 2016 года. Выданне змяшчае пераклад з ангельскай на беларускую мову дадзеных усіх класаў УДК, якія ўжываліся ў сусветнай практыцы індэксавання дакументаў на дату выхаду.
Сэрвіс будзе запатрабаваны для задавальнення патрэб бібліятэк, арганізацый, што гандлююць друкаванымі выданнямі, інфармацыйных цэнтраў, якія займаюцца сістэматызацыяй дакументаў, арганізацый дакументных фондаў і электронных сэрвісаў для пошуку інфармацыі.
Таксама выкарыстанне сэрвіса значна аблегчыць працу навукоўцаў, якія займаюцца падборам літаратуры па пэўнай тэматыцы для паглыбленага вывучэння тэмы і/або напісання ўласных прац. Папярэдняе вызначэнне кода УДК – патрабаванне, якое часта прад’яўляюць да аўтараў выданні са спісаў ВАК і выданні, уключаныя ў міжнародныя рэфератыўныя базы. Зварот да кодаў УДК дазваляе значна паскорыць працу па пошуку матэрыялу.
Асаблівасці сэрвіса
- У кірылічных электронных выданнях непасрэдна лічбаваму коду УДК часта папярэднічае надпіс «УДК» або «удк» (верагодна, у некаторых выпадках ён можа таксама размяшчацца пасля кода). Для павышэння зручнасці праца сэрвіса наладжана такім чынам, каб карыстальнік мог скапіраваць у поле ўводу ўвесь радок разам з прэфіксам або постфіксам, што складаецца з сімвалаў «У», «Д», «К» у верхнім ці ніжнім рэгістры і прабелаў. У гэтым выпадку код будзе распазнаны правільна.
- Па кожным запыце сэрвіс выдае адназначны адказ – інфармацыю па знойдзеным класе УДК або пусты вывад, калі клас УДК не знойдзены. Паводле логікі сваёй працы і логікі будовы табліц УДК, сэрвіс павінен выдаць толькі адзін вынік для кожнага выпадку. Тым не менш, калі сэрвісу чамусьці ўдасца знайсці некалькі адпаведнікаў, ён можа вывесці на экран да 10 пазіцый.
- Код УДК аналізуецца ў напрамку ад канца да пачатку. Калі па канкрэтным запыце не ўдалося знайсці нічога, сэрвіс паслядоўна адкідае адзін сімвал ад канца кода УДК і спрабуе знайсці нешта паводле атрыманай камбінацыі. Гэта азначае, што, напрыклад, пры запыце «4» не будзе знойдзена нічога (у табліцах УДК на сённяшні дзень не існуе класаў, код якіх пачынаецца з дадзенага сімвала), але па запыце «04» будзе знойдзены клас, які адпавядае коду «0».
Алгарытм працы сэрвіса
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі ўвод, UserUDC;
- Сімвалы прэфіксаў і постфіксаў для выдалення, TrimSymbols (сімвалы «У», «Д», «К» у верхнім і ніжнім рэгістры і прабел);
- Мноства знойдзеных уваходжанняў у табліцы базы дадзеных, Found;
- Мноства вынікаў, Result.
Пачатак алгарытму.
Крок 1.1. Прывядзенне карыстальніцкага ўводу UserUDC да выгляду, прыдатнага для праграмнай апрацоўкі, і запіс апрацаванага UserUDC у пераменную SearchData. Для гэтага ў UserUDC з пачатку і канца выдаляюцца ўсе сімвалы, якія належаць да TrimSymbols. Стварэнне пераменнай Rest для наступнага запісу ў яе сімвалаў SearchData.
Крок 1.2. Стварэнне пераменнай FoundCount для наступнага запісу колькасці знойдзеных элементаў, пераменнай Step1=0 для падліку колькасці здзейсненых запісаў у мноства Result пры першапачатковым дакладным супадзенні, пераменнай Step2=0 для падліку колькасці здзейсненых запісаў у мноства Result пры наступным дакладным супадзенні, а таксама пераменнай Length, у якую запісваецца колькасць сімвалаў SearchData.
Крок 2.1. Ажыццяўленне запыту да базы дадзеных: пошук у табліцы UDC усіх уваходжанняў, дзе SearchData дакладна супадае са значэннем поля Notation. Калі дадзеныя ўдалося знайсці, запісаць іх ў мноства Found, кожны элемент якога складаецца з палёў Notation (код УДК), English (дадзеныя з англійскай версіі УДК), Belarusian (дадзеныя з беларускай версіі УДК), і ажыццявіць крокі 2.1.1. – 2.1.2, калі не – перайсці да кроку 2.2.
Крок 2.1.1. Ажыццявіць запіс агульнай колькасці знойдзеных элементаў у пераменную FoundCount.
Крок 2.1.2. Запіс тройкі <Found.Notation[Step1], Found.English[Step1], Found.Belarusian[Step1]> у мноства Result. Калі Step1 < FoundCount, інкрэментаваць Step1 і здзейсніць крок 2.1.2 яшчэ раз, калі не – перайсці да кроку 3.
Крок 2.2. Калі Rest ≠ ∅, ачысціць Rest. Запісаць у Rest столькі сімвалаў SearchData (ад пачатку), колькі на дадзены момант складае значэнне пераменнай Length. Калі Length = 0, перайсці да кроку 3.
Крок 2.3. Ажыццяўленне запыту да базы дадзеных: пошук у табліцы UDC усіх уваходжанняў, дзе Rest дакладна супадае са значэннем поля Notation. Калі дадзеныя ўдалося знайсці, запісаць іх ў мноства Found, кожны элемент якога складаецца з палёў Notation, English, Belarusian, і ажыццявіць крокі 2.3.1. – 2.3.2, калі не – дэкрэментаваць Length і перайсці да кроку 2.2.
Крок 2.3.1. Ажыццявіць запіс агульнай колькасці знойдзеных элементаў у пераменную FoundCount.
Крок 2.3.2. Запіс тройкі <Found.Notation[Step2], Found.English[Step2], Found.Belarusian[Step2]> у мноства Result. Калі Step2 < FoundCount, інкрэментаваць Step2 і здзейсніць крок 2.3.2 яшчэ раз, калі не – перайсці да кроку 3.
Крок 3. Вывад на экран зместу мноства Result у адмысловым фармаце.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Карыстальніцкі інтэрфейс сэрвіса прадстаўлены на малюнку 1.
Малюнак 1 – Графічны інтэрфейс сэрвіса «Расшыфроўка УДК»
Інтэрфейс змяшчае наступныя вобласці:
- поле ўводу кода УДК;
- кнопка «Пошук!», якая запускае апрацоўку і дае магчымасць атрымаць вынікі ў полі іх вываду.
Пасля апрацоўкі кода сэрвісам у полі вываду вынікаў карыстальнік атрымлівае наступныя спісы інфармацыі:
- код класа;
- апісанне класа па-англійску;
- апісанне класа па-беларуску.
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Пошук па ўведзеным уручную кодзе.
- Увесці код.
- Націснуць кнопку «Пошук!».
- Атрымаць інфармацыю.
Сцэнар 2. Пошук па кодзе, скапіраваным з электроннай крыніцы.
- Скапіраваць код з электроннай крыніцы ў поле ўводу. Дапушчальна капіраванне кода з прэфіксам або постфіксам «УДК».
- Націснуць кнопку «Пошук!».
- Атрымаць інфармацыю.
Магчымы вынік працы сэрвіса прадстаўлены на малюнку 2.
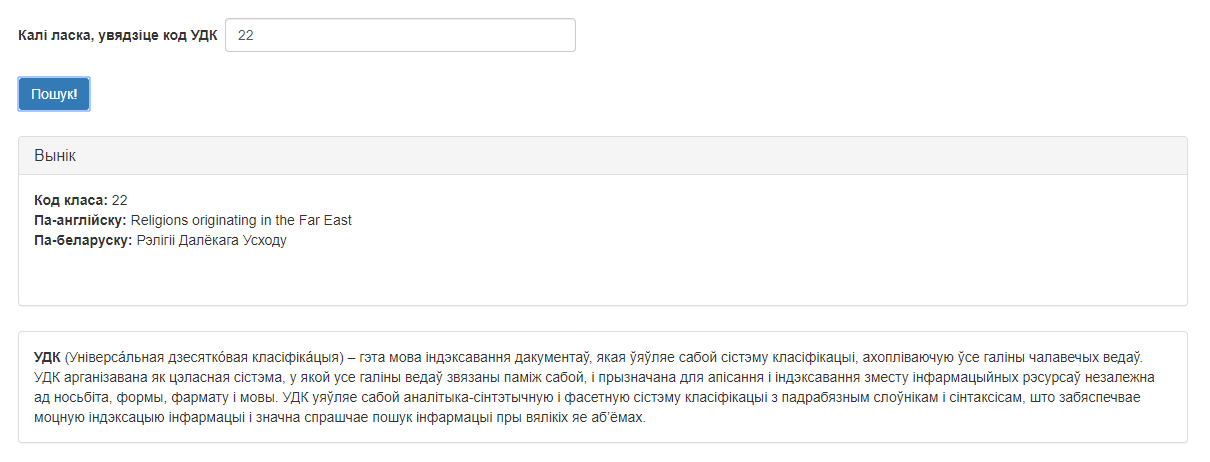
Малюнак 2 – Вынік працы сэрвіса «Расшыфроўка УДК»
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Расшыфроўка УДК» праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/UdcDecoder/api.php. Праз масіў data перадаюцца наступныя параметры:
- text – код УДК.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/UdcDecoder/api.php”,
data:{
“text”: “811.161.3”
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з наступнымі параметрамі:
- text – уваходны тэкст – код УДК;
- notation – выніковы код УДК;
- english – расшыфроўка па-англійску;
- belarusian – расшыфроўка па-беларуску;
- noresult – фармулёўка пры адсутнасці вынікаў.
Напрыклад, па прыведзеным вышэй AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “811.161.3”,
“notation”: “811.161.3”,
“english”: “Belarusian language”,
“belarusian”: “Беларуская мова”,
“noresult”: “”
}
]
Спасылкі на крыніцы
Старонка сэрвіса: https://corpus.by/UdcDecoder/?lang=be
Сайт Кансорцыума УДК: https://www.udcc.org/
Табліцы УДК на беларускай мове: https://www.udcsummary.info/php/index.php?lang=be&pr=Y
Перакрыжаваныя спасылкі
- Драгун, А. Я. Аўтаматызаваныя сродкі атрымання расшыфроўкі і спісаў кодаў беларускамоўнай Універсальнай дзесятковай класіфікацыі / А. Я. Драгун, Я. С. Зяноўка, М. С. Галаўчак, С. С. Маеўскі, Ю. С. Гецэвіч // Материалы VII Международного конгресса «Библиотека как феномен культуры» : Краеведение и страноведение в сохранении культурного разнообразия, Минск, 21–22 октября 2020 г. / Национальная библиотека Беларуси ; [сост.: Т. В. Кузьминич, А. А. Суша]. – Минск, 2020. – С. 300-306.
- Захарьев, В.А. Алгоритм текстонезависимого обучения для систем мультиголосового синтеза речи / В.А. Захарьев, А.А. Петровский // Информационные технологии и системы (ИТС-2016) / БГУИР ; редкол. : Л.Ю. Шилина [и др.]. — Минск : БГУИР, 2016. — C. 90-91.
- Гецэвіч, Ю.С. Беларускамоўнае выданне УДК: склад і асноўныя этапы падрыхтоўкі / Ю.С. Гецэвіч, А.М. Скопінава, Т.І. Окрут, Г.Р. Станіславенка // Інструментарый індэксатара і яго прымяненне ў бібліятэках Беларусі / Нацыянальная бібліятэка Беларусі ; пад рэд. Кузьмініч Т.В. — Мінск : БібліяКансультант, 2016. — C. 27-34.
- Станиславенко, А.Г. Этапы подготовки первого издания УДК на беларусском языке / А.Г. Станиславенко, С.И. Лысы, Ю.С. Гецевич // Информация в современном мире : доклады Международной конференции, Москва, 25-26 октября 2017 г. / ВИНИТИ РАН. — Москва : ВИНИТИ РАН, 2017. — C. 297-303.