Internet service “Text-to-speech synthesis” (TSS) is a high-quality tool for text processing. The system is based on free and the most widespread on the Internet scripting PHP programming language and serves to voice Belarusian or Russian texts inputted by a user. Text-to-speech Synthesizer processes a text automatically and forms an audio file that a user can listen to, download and save to a computer.
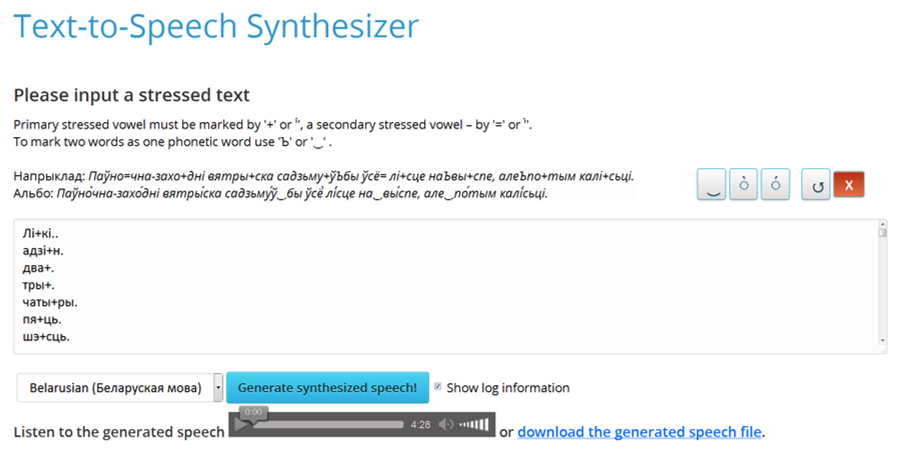
Figure 1 – An Interface of the text-to-speech synthesizer
To get a synthesized speech a user needs to select language, insert or print a text in the input field and click “Generate synthesized speech!” (Figure 1).
For better quality of processed text, one can use the following marks:
plus / + / or aqute / ы́ / – to arrange main stress (for example, “звыча+йны“);
equal to / = / or gravis / ё̀ / – to arrange secondary stress (for example, “тэ=леперада+ча“);
circumflex / ^ / – is used between two words to combine them into complex phonetic word (for example, “на^стале+”, “сказа+ў^бы”).
In order to download or save a generated file a user needs to click the appropriate links Listen to generated speech and download generated speech file.
While processing an electronic text to speech synthesis, the system generates additional intermediate results. Among them there are a normalized text, phonemic text, allophonic text, etc. In order to see intermediate results of the text-to-speech synthesizer it is necessary to put a tick next to the checkbox “Show log information”.
Among other additional intermediate results the service provides an information on each text character – its name. Like any computer-linguistic system, the synthesizer claims to use all characters that are appropriate to the settings of the system. For example, the use of a character, which does not correspond to a particular alphabetic system (Cyrillic, Latin alphabet, etc.), results in incorrect text-to-speech synthesis. In such cases it is necessary to find mismatched character and replace it with the correct one (Figure 2).
The text-to-speech synthesizer also depicts data of all the words found in a text, parts of speech, tags (contracted notations of morphological word characteristics), a list of words with stresses, placed by a user, a list of words that are absent in the system database (see Figure 2).
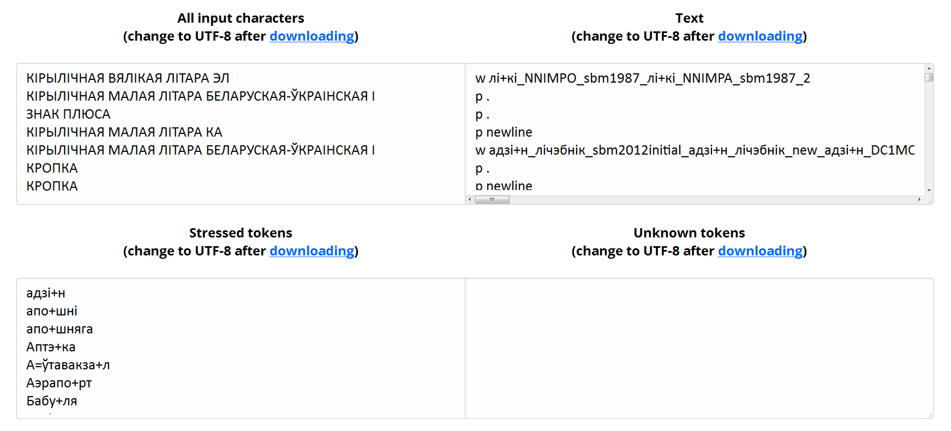
Figure 2 – Intermediate results of TSS: information on characters, normalized text with morphological tags, stressed tokens, unknown tokens

Figure 3 – Intermediate results of TSS: a list of homographs, intonation markers, a list of phonemic and allophonic words
Trying to determine the position of a word stress, speech synthesizer checks each word of an input text on a variation of its reading in accordance to the information provided in dictionaries, there is a search for words with the same spelling and different stresses. Information about the words that have ambiguous stress position are displayed in the window Homographs. Also, a user receives information about intonation markers (Information markers), a list of phonemic (Phonemes) and allophonic (Allophones, Allophones information) words (Figure 3).
An additional feature of the synthesizer is transcription generator which outputs text in 4 formats: Cyrillic, international (IPA), Simplified IPA transcription and X-SAMPA (Figure 4). More information about each of the formats can be found in the given service page “Transcription Generator“, where links to electronic resource that were used are presented.
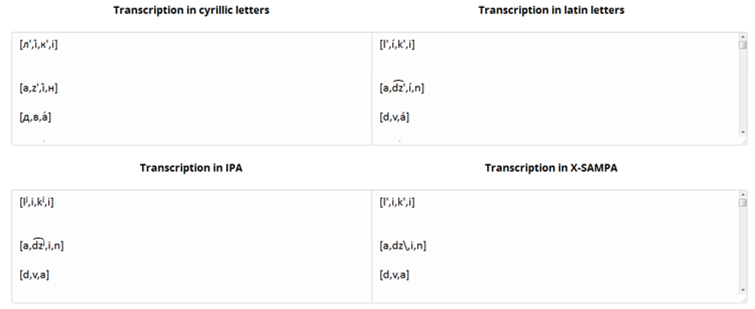
Figure 4 – Intermediate results of TSS: four transcription formats
In addition, a user has a posibility to download files with the intermediate results of TSS, by clicking appropriate links (Downloading).
Access to the service via the API
To access the service «Text-to-Speech Synthesizer» via the API, you should send an AJAX-request (type: POST) to the address https://corpus.by/TextToSpeechSynthesizer/api.php. With an input array data the following parameters are passed:
- text — arbitrary input text in Belarusian, Russian or English.
- language — language of the input text. Belarusian (параметр be), Russian (параметр ru) and English (параметр en) are available.
- voice — speech synthesizer voice:
- for Belarusian and English following voices are available: AlesiaBel, AlesiaBel (dictation mode), BorisBel, BorisBel (dictation mode), BorisBelHigh;
- for Russian following voices are available: AlesiaRus, AlesiaRus (dictation mode), BorisRus, BorisRus (dictation mode), BorisRusHigh.
Example of AJAX-request:
$.ajax({
type: “POST”,
url: “https://corpus.by/TextToSpeechSynthesizer/api.php“,
data:{
“text”: “Груша цвіла апошні год.”,
“language”: “be”,
“voice”: “BorisBel”
},
success: function(msg){ },
error: function() { }
});
The server returns a JSON-array with the following parameters:
- status — processing status.
- text — input text.
- Tokenization results:
- charactersText — result;
- charactersUrl — URL, where the result is saved.
- Text processor results:
- tokensText — result;
- tokensUrl — URL, where the result is saved.
- List of tokens with accents specified by the user:
- stressedText — list;
- stressedUrl — URL, where the list is saved.
- List of words that are not in the synthesizer database:
- unknownText — list;
- unknownUrl — URL, where the list is saved.
- List of homographs found in the input text:
- homographsText — list;
- homographsUrl — URL, where the list is saved.
- Intonational processor results:
- prosodicText — result;
- prosodicUrl — URL, where the result is saved.
- Phonetic processor subtotal — phonemic text:
- phonemicText — result;
- phonemicUrl — URL, where the result is saved.
- Phonetic processor subtotal — allophonic text:
- allophonicText — result;
- allophonicUrl — URL, where the result is saved.
- List of allophones with characteristics:
- allophoneCharacteristicsText — list;
- allophoneCharacteristicsUrl — URL, where the list is saved.
- talkingHeadCharacteristics — allophones characteristics, required for the service «Talking Head Synthesizer».
- transcriptionCyr — transcription in cyrillic format.
- transcriptionLat — transcription in a simplified format of the international phonetic alphabet.
- transcriptionIPA — transcription in IPA format (International Phonetic Alphabet).
- transcriptionXSAMPA — transcription in X-SAMPA format.
- audio — link to the generated audio file.
For example, the following reply will be formed on the above listed AJAX-request:
[
{
“status”: “success”,
“text”: “Груша цвіла апошні год.”,
“charactersText”: “Груша_груша_word_cyrillic
цвіла_цвіла_word_cyrillic
апошні_апошні_word_cyrillic
год_год_word_cyrillic
._._other
_newline_other”,
“charactersUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_characters.html”,
“tokensText”: “w гру+ша_НевядомаяКатэгорыя_sbm2012initial_гру+ша_NNIFO_sbm1987_гру+ша_NFN1_noun2013_3
w цвіла+_VIIPF_sbm1987_цвіла+_дзеяслоў_verb2013_цвіла+_?_words_processed_3
w апо+шні_НевядомаяКатэгорыя_sbm2012initial_апо+шні_JJMO_sbm1987_апо+шні_JJMA_sbm1987_апо+шні_прыметнік_adjective2013_апо+шні_прыметнік_adjective2013_5
w го+д_НевядомаяКатэгорыя_sbm2012initial_го+д_NNIMO_sbm1987_го+д_NNIMA_sbm1987_го+д_NMN1_noun2013_го+д_NMA1_noun2013_5
p .
p newline”,
“tokensUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_tokens.html”,
“stressedText”: “”,
“stressedUrl”: “https://corpus.by/TextToSpeechSynthesizer/null”,
“unknownText”: “”,
“unknownUrl”: “https://corpus.by/TextToSpeechSynthesizer/null”,
“homographsText”: “”,
“homographsUrl”: “https://corpus.by/TextToSpeechSynthesizer/null”,
“prosodicText”: “ГРУ+ША
ЦВІЛА+
АПО+ШНІ
ГО+Д
(p4)
(p4)”,
“prosodicUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_intonationalText.txt”,
“phonemicText”: “GH,R,U,+,SH,A,/,C’,V’,I,L,A,+,/,A,P,O,+,SH,N’,I,/,GH,O,+,T,/,#P4”,
“phonemicUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_phonemicText.txt”,
“allophonicText”: “GH004,R022,U022,SH002,A323,/,C’002,V’002,I241,L002,A012,/,A221,P001,O012,SH002,N’004,I242,/,GH001,O032,T000,/,#P4,”,
“allophonicUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_allophonicText.txt”,
“allophoneCharacteristicsText”: “GH(65ms;8000hz)
R(43ms;8000hz)
U0(140ms;8000hz)
SH(106ms;8000hz)
A3(50ms;8000hz)
#C3(53ms;8000hz)
C'(80ms;8000hz)
V'(61ms;8000hz)
I2(70ms;8000hz)
L(78ms;8000hz)
A0(141ms;8000hz)
#C3(53ms;8000hz)
A2(70ms;8000hz)
P(106ms;8000hz)
O0(120ms;8000hz)
SH(106ms;8000hz)
N'(54ms;8000hz)
I2(70ms;8000hz)
#C3(53ms;8000hz)
GH(79ms;8000hz)
O0(140ms;8000hz)
T(145ms;8000hz)
#C3(53ms;8000hz)
#P4(1176ms;8000hz)”,
“allophoneCharacteristicsUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_allophoneCharacteristics.txt”,
“transcriptionCyr”: “[γру́ша] [ц’в’іла́] [апо́шн’і] [γо́т]”,
“transcriptionLat”: “[ɣrúʂa] [t͡s’v’ilá] [apóʂn’i] [ɣót]”,
“transcriptionIPA”: “[ɣruʂa] [ʦʲvʲila] [apɔʂnʲi] [ɣɔt]”,
“transcriptionXSAMPA”: “[Grus`a] [ʦ’v’ila] [apOs`n’i] [GOt]”,
“audio”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-38-19_80-94-171-2_975_be_ssrlab.wav”
}
]
Links to sources
Service Page: http://corpus.by/TextToSpeechSynthesizer/?lang=en
Cross references
- Алгарытмы лінгвістычнай апрацоўкі тэкстаў для сінтэзу маўлення на беларускай і рускай мовах : дысертацыя на атрыманне навуковай ступені кандыдата тэхнічных навук : спецыяльнасць 05.13.01 Сістэмны аналіз, кіраванне і апрацоўка інфармацыі / Гецэвіч Юрый Станіслававіч ; навуковы кіраўнік Лабанаў Б. М. ; Аб’яднаны інстытут праблем інфарматыкі Нацыянальнай акадэміі навук Беларусі. — Мінск, 2012. — 184, [6] л. : іл., табл., схемы. — Ч. тэксту рус. — Бібліягр.: л. 153-164.
- Гецэвіч, Ю.С. Мабільная праграма як сродак для навучання беларускай мове / Ю.С. Гецэвіч, М.У. Марчык, Н.Д. Казлоўская, М.В. Шыбко, Д.А. Дзенісюк, Э.У. Русецкая // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы I Респ. науч.-практ. конф. с междунар. участием, Минск, 23–24 февр. 2017 г. / БГУ, факультет социокультурных коммуникаций ; редкол. : О.Г. Прохоренко (отв. ред.) [и др.]. — Минск : Изд. центр БГУ, 2017. — C. 102-103.
- Захарьев, В.А. Мультиголосовой синтез речи по тексту для построения естественно-языковых интерфейсов интеллектуальных систем / В.А. Захарьев, А.А. Петровский // Открытые семантические технологии проектирования интеллектуальных систем = Open Semantic Technologies for Intelligent Systems : материалы междунар. науч.-техн. конф. Вып. 1 (Минск, 16-18 февраля 2017 г.). / редкол. : В.В. Голенков (отв. ред.) [и др.]. — Минск : БГУИР, 2017. — C. 167-170.
- Лысы С.І. Генерацыя нацыянальнай транскрыпцыі тэкстаў на беларускай мове / С.І. Лысы, Ю.С. Гецэвіч // Інфарматыка. — 2017. — №54. — C. 84-92.
- Захарьев, В.А. Подход к устранению речевых неоднозначностей на основе семантико-акустического анализа / В.А. Захарьев, И.С. Азарьев, К.В. Русецкий // Открытые семантические технологии проектирования интеллектуальных систем = Open Semantic Technologies for Intelligent Systems : материалы междунар. науч.-техн. конф. Вып. 2 (Минск, 15-17 февраля 2018 г.). / БГУИР ; редкол.: В.В. Голенков [и др.]. — Минск : БГУИР, 2018. — C. 211-222.
- Дзенісюк, Д. А. Праграмаванне калькулятара з убудаванымі галасавымі функцыямі / Д. А. Дзенісюк, М. У. Марчык, А. В. Крывальцэвіч, Н. Д. Казлоўская // Веб-программирование и интернет-технологии WebConf2018: тез. докл. 4-й Междунар. науч.-практ. конф., Минск, 14–18 мая 2018 г. / Белорус. гос. ун-т ; редкол.: И. М. Галкин (отв.ред.) [и др.]. — Минск : БГУ, 2018. — C. 21.
- Захарьев, В.А. Семантический анализ речевых сообщений на основе формализованного контекста / В.А. Захарьев, Т.В. Ляхор, А.В. Губаревич, И.С. Азаров // Открытые семантические технологии проектирования интеллектуальных систем : сборник научных трудов. Выпуск 3. / БГУИР ; редкол.: В.В. Голенков [и др.]. – Минск : БГУИР, 2019. – C. 103-112.
- Гецэвіч, Ю.С. Праектаванне натуральна-моўных інтэрфейсаў для даведкавых сістэм / Ю.С. Гецэвіч, У.А. Жытко, С.А. Гецэвіч, Л.І. Кайгародава, К.А. Нікалаенка // Інфарматыка. – 2019. – Т. 16, № 3. – С. 37-47.
- Лобанов, Б.М. Ретроспективный обзор исследований и разработок лаборатории распознавания и синтеза речи / Б.М. Лобанов // Автоматическое распознавание и синтез речи: сб. науч. тр. – Минск: ИТК НАН Беларуси, 2000. – С. 6-24.
- Lobanov, B.M. Allophonic text-to-speech synthesizer: general structure and description / B.M. Lobanov // Автоматическое распознавание и синтез речи: сб. науч. тр. – Минск: ИТК НАН Беларуси, 2000. – С. 43-53.
- Гецэвіч, Ю.С. Праектаванне інтэрнэт-сервісаў для працэсараў сінтэзатара маўлення па тэксце з магчымасцю прадстаўлення бясплатных электронных паслуг насельніцтву / Ю.С. Гецэвіч, С.І. Лысы // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2014) : доклады XIII Международной конференции (Минск, 20 ноября 2014 г.). – Минск : ОИПИ НАН Беларуси, 2014. — C. 265-269.
- Захарьев, В.А. Алгоритм текстонезависимого обучения для систем мультиголосового синтеза речи / В.А. Захарьев, А.А. Петровский // Информационные технологии и системы (ИТС-2016) / БГУИР ; редкол. : Л.Ю. Шилина [и др.]. — Минск : БГУИР, 2016. — C. 90-91.
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Гецэвіч, Ю.С. Распрацоўка сістэм уводу і вываду гукавой інфармацыі ў інтэрнэце / Ю.С. Гецэвіч, В.Л. Аляхно, Я.С. Зяноўка, С.І. Лысы // Информационные технологии и системы (ИТС-2016) / БГУИР ; редкол. : Л.Ю. Шилин [и др.]. — Минск : БГУИР, 2016. — C. 102-103.
- Качан, Я.С. Збор мноства маўленчых фраз для тэставання сістэм сінтэзу і распазнавання маўлення па семантычных класах “плошча”, “аб’ём” / Я.С. Качан, А.В. Крывальцэвіч, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 258-262.
- Качан, Я. С. Праблемы апрацоўкі колькасных выразаў з адзінкамі вымярэння на прыкладзе дыстанцыі, даўжыні, хуткасці і памеру для англійскай і беларускай моў / Я. С. Качан, П. А. Маракуліна, А. В. Крывальцэвіч // Актуальные вопросы германской филологии и лингводидактики : материалы XX Междунар. науч.-практ. конф. / Брест. гос. ун-т имени А.С. Пушкина ; редкол. : Е. Г. Сальникова [и др.]. — Брест : Альтернатива, 2016. — C. 257-261.
- Гецэвіч, Ю.С. Аналіз памылак выходных даных інтэрнэт-сінтэзатара беларускага і рускага маўлення па тэксце / Ю.С. Гецэвіч, І.В. Рэянтовіч, С.І. Лысы // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 221-225.
- Гецэвіч, Ю.С. Выкарыстанне сістэм машыннага перакладу і сістэмы сінтэзу маўлення для забеспячэння даступнасці заканадаўчых тэкстаў для людзей з інваліднасцю па зроку / Ю.С. Гецэвіч, В.В. Варановіч, А.У. Бабкоў // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2019) : доклады XVIII Международной конференции, Минск, 21 ноября 2019 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. – Минск : ОИПИ НАН Беларуси, 2019. – C. 190-193.
- Гецевич, Ю.С. Система синтеза белорусской речи по тексту / Ю.С. Гецевич, Б.М. Лобанов // Речевые технологии. – 2010. – № 1. – С. 91-100.
- Гецэвіч, Ю.С. Распрацоўка сінтэзатара беларускага і рускага маўленняў па тэксце для мабільных і інтэрнэт-платформаў / Ю.С. Гецэвіч, Д.А. Пакладок, Д.В. Брэк // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2012) : доклады XI Международной конференции (Минск, 15 ноября 2012 г.). – Минск : ОИПИ НАН Беларуси, 2012. – С. 254–259.
- Гецэвіч, Ю.С. Выкарыстанне сістэм машыннага перакладу і сістэмы сінтэзу маўлення для забеспячэння даступнасці заканадаўчых тэкстаў для людзей з інваліднасцю па зроку / Ю.С. Гецэвіч, В.В. Варановіч, А.У. Бабкоў // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2019) : доклады XVIII Международной конференции, Минск, 21 ноября 2019 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. – Минск : ОИПИ НАН Беларуси, 2019. – C. 190-193.