Сэрвіс «Сінтэзатар маўлення па тэксце» прызначаны для агучвання ўведзенага карыстальнікам тэксту. На ўваход карыстальнік падае электронны тэкст на беларускай ці рускай мове, сінтэзатар маўлення аўтаматычна апрацоўвае тэкст і фарміруе гукавы файл з сінтэзаваным уваходным тэкстам, які можна праслухаць, спампаваць і захаваць на камп’ютар.
Асноўныя тэрміны і паняцці
Сінтэзатар маўлення па тэксце (СМТ) — гэта сістэма, здольная генераваць маўленне па тэксце. Змяшчае два блокі: блок лінгвістычнай апрацоўкі тэксту да фанемнага выгляду з пазнакамі націску, інтанацый (прасодыі) і рытму, а таксама блок апрацоўкі маўленчага сігналу, які пераўтварае раней атрыманы фанемны выгляд у гукавы сігнал маўлення [1].
Асаблівасці сервісу
Сэрвіс рэалізаваны на бясплатнай і найбольш распаўсюджанай у Інтэрнэце скрыптавай мове праграмавання PHP.
На цяперашні час сінтэзатар прапануе карыстальніку наступныя галасы:
| AlesiaBel | беларуская мова | жаночы голас |
| AlesiaBel (dictation mode) | жаночы голас | |
| BorisBel | мужчынскі голас | |
| BorisBel (dictation mode) | мужчынскі голас | |
| BorisBelHigh | мужчынскі голас | |
| AlesiaRus | руская мова | жаночы голас |
| AlesiaRus (dictation mode) | жаночы голас | |
| BorisRus | мужчынскі голас | |
| BorisRus (dictation mode) | мужчынскі голас | |
| BorisRusHigh | мужчынскі голас |
Заўвага: галасы з пазнакай dictation mode у назве адрозніваецца тым, што робяць больш рэзкія і доўгія перапынкі паміж словамі.
Для больш якаснай агучкі ёсць магчымасць уручную пры дапамозе спецыяльных пазнак «падказаць» сінтэзатару, дзе павінны быць націск:
- плюс /+/ або акут /ы́/ – для пазначэння асноўнага націску (напрыклад, “звыча+йны”);
- роўна /=/ або гравіс /ё̀/ – для пазначэння пабочнага націску (напрыклад, “тэ=леперада+ча”);
- цыркумфлекс /^/ – паміж двума словамі, каб аб’яднаць іх у складанае фанетычнае слова (напрыклад, “на^стале+”, “сказа+ў^бы”).
СМТ выкарыстоўваецца ў працы іншых сэрвісаў платформы www.corpus.by, а менавіта сэрвісаў «Сінтэзатар “Гаворачая галава”» (гукавая дарожка), «Прагназаванне працягласці прамовы» (працягласць прамовы — гэта фактычна час, за які дадзены сінтэзатар прамовіць уваходны тэкст).
Практычная каштоўнасць
Сэрвіс мае вялікія перспектывы прымянення і ўкаранення. Невялікая частка сфер, у якіх можа прымяняцца сінтэз маўлення:
- сістэмы абзвону і інфакіёскі;
- галасавыя і сігналізацыйныя сістэмы апавяшчэння;
- сістэмы чытання кніг;
- навучальныя сістэмы;
- гаворачыя камп’ютары для інвалідаў па зроку і слыху.
Апісанне інтэрфейсу карыстальніка
Графічны інтэрфейс сэрвісу ўключае наступныя часткі, прадстаўленыя на малюнку 1.
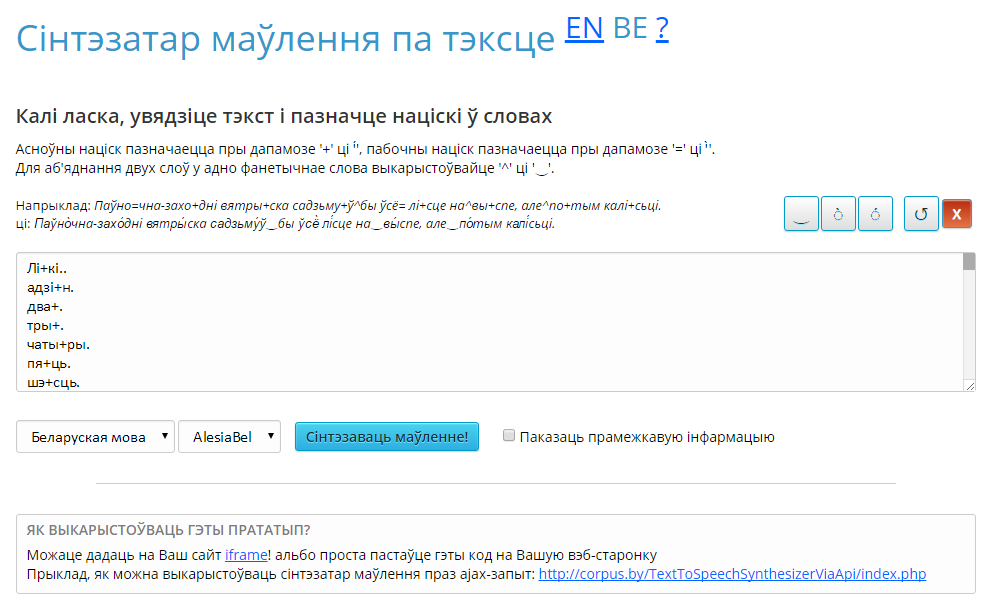
Малюнак 1. Знешні інтэрфейс сэрвісу «Сінтэзатар маўлення па тэксце»
Інтэрфейс мае наступныя вобласці:
- інфармацыя аб тым, як расстаўляць спецыяльныя сімвалы — націскі і пабочныя націскі ва ўваходных словах, а таксама прыклад пазначэння націскаў;
- кнопкі расстаноўкі спецыяльных сімвалаў, якія знаходзяцца над полем уводу справа;
- поле ўводу тэксту, які патрабуе сінтэзавання (па змаўчанні ўведзены тэкст прыкладу);
- вобласць выбару мовы ўваходнага тэксту (беларуская, руская);
- вобласць выбару голасу, якім мусіць быць выканана сінтэзаванае маўленне (AlesiaBel, Boris, BorisBel, BorisRus);
- кнопка «Сінтэзаваць маўленне!», якая дазваляе атрымаць вынікі;
- гачак «Паказаць прамежкавую інфармацыю», з дапамогай якога можна ўключыць ці адключыць вывад прамежкавай інфармацыі;
- інфармацыя аб тым, як убудаваць сінтэзатар на знешнія сайты.
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Атрыманне сінтэзаванага маўлення
Ніжэй апісаны самы хуткі спосаб атрымаць гукавы файл з сінтэзаваным маўленнем.
- У поле ўводу ўвесці (уставіць ці надрукаваць) тэкст, які патрабуе сінтэзавання (напрыклад, наступны тэкст: «Мой родны кут, як ты мне мілы!»).
- У вобласці выбару мовы абраць мову ўведзенага тэксту для таго, каб сінтэзатар прымяніў правілы менавіта для пазначанай мовы (па змаўчанні выбрана беларуская).
- У вобласці выбару голасу абраць голас, якім мусіць быць выканана сінтэзаванае маўленне (па змаўчанні выбрана AlesiaBel).
- Націснуць кнопку «Сінтэзаваць маўленне!» для атрымання вынікаў у полі «Праслухаць сінтэзаванае маўленне» (малюнак 2).
- Выніковы гукавы файл можна праслухаць, націснуўшы кнопку прайгравання.
- Таксама выніковы файл можна захаваць на камп’ютар, націснуўшы спасылку «спампаваць файл з сінтэзаваным маўленнем».
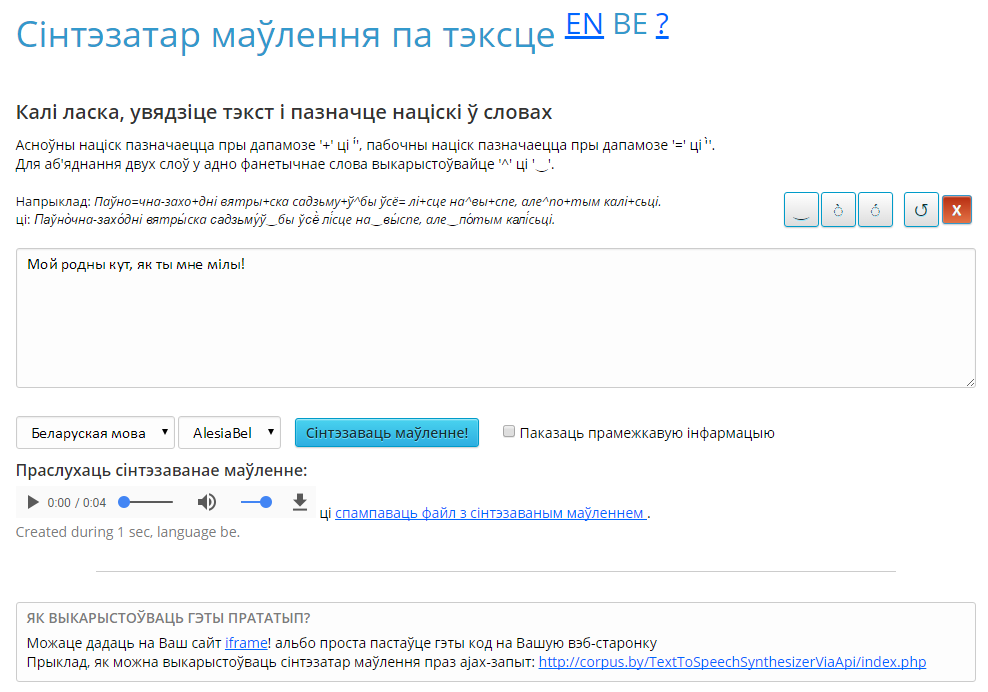
Малюнак 2. Вынікі сінтэзавання маўлення
Сцэнар 2. Атрыманне больш якаснага сінтэзаванага маўлення
Ніжэй апісаны спосаб атрымаць больш якаснае сінтэзаванае маўленне пры дапамозе расстаноўкі дадатковых сімвалаў, якія дадуць сінтэзатару «падказкі» для большай плаўнасці маўлення і больш дакладнай інтанацыі.
- У поле ўводу ўвесці (уставіць ці надрукаваць) тэкст, які патрабуе сінтэзавання (напрыклад, наступны тэкст: «Паўночна-заходні вятрыска садзьмуў бы ўсё лісце на выспе, але потым калісьці»).
- Для больш якаснай агучкі расставіць пазнакі — націскі і знакі аб’яднання ў адно фанетычнае слова, што можна зрабіць двума спосабамі (малюнак 3):
- Уручную, ставячы сімвал /+/ на пасля літары асноўнага націску, сімвал /=/ на пасля літары пабочнага націску і сімвал /^/ на месцы аб’яднання ў адно фанетычнае слова: Паўно=чна-захо+дні вятры+ска садзьму+ў^бы ўсё= лі+сце на^вы+спе, але^по+тым калі+сьці.
- З дапамогай кнопак сэрвісу, якія размешчаны над полем уводу справа. Для пастаноўкі сімвала курсор павінны стаяць пасля неабходнай літары: Паўно̀чна-захо́дні вятры́ска садзьму́ў‿бы ўсё̀ лі́сце на‿вы́спе, але‿по́тым калі́сьці.
- У вобласці выбару мовы абраць мову ўведзенага тэксту для таго, каб сінтэзатар прымяніў правілы менавіта для пазначанай мовы (па змаўчанні выбрана беларуская).
- У вобласці выбару голасу абраць голас, якім мусіць быць выканана сінтэзаванае маўленне (па змаўчанні выбрана AlesiaBel).
- Націснуць кнопку «Сінтэзаваць маўленне!» для атрымання вынікаў у полі «Праслухаць сінтэзаванае маўленне» (малюнак 3).
- Выніковы гукавы файл можна праслухаць, націснуўшы кнопку прайгравання.
- Таксама выніковы файл можна захаваць на камп’ютар, націснуўшы спасылку «спампаваць файл з сінтэзаваным маўленнем».

Малюнак 3. Вынікі больш якаснага сінтэзавання маўлення
Сцэнар 3. Атрыманне сінтэзаванага маўлення з прамежкавымі вынікамі
У ходзе пераўтварэння электроннага тэксту ў маўленне сінтэзатар генеруе мноства прамежкавых вынікаў. Сярод іх ёсць нармалізаваны тэкст, фанемны запіс тэксту, запіс тэксту ў алафонным выглядзе і іншае. Сцэнар застаецца тым жа, што і сцэнары 1 і 2, толькі дадаецца неабходнасць націснуць гачак «Паказаць прамежкавую інфармацыю».
- У поле ўводу ўвесці (уставіць ці надрукаваць) тэкст, які патрабуе сінтэзавання (тэкст стандартнага прыкладу).
- У вобласці выбару мовы абраць мову ўведзенага тэксту для таго, каб сінтэзатар прымяніў правілы менавіта для пазначанай мовы (па змаўчанні выбрана беларуская).
- У вобласці выбару голасу абраць голас, якім мусіць быць выканана сінтэзаванае маўленне (па змаўчанні выбрана AlesiaBel).
- Націснуць гачак «Паказаць прамежкавую інфармацыю» для таго, каб пабачыць прамежкавыя вынікі сінтэзатара маўлення.
- Націснуць кнопку «Сінтэзаваць маўленне!» для атрымання вынікаў у полі «Праслухаць сінтэзаванае маўленне» (малюнак 2).
- Выніковы гукавы файл можна праслухаць, націснуўшы кнопку прайгравання.
- Выніковы гукавы файл можна захаваць на камп’ютар, націснуўшы спасылку «спампаваць файл з сінтэзаваным маўленнем».
- Разгледзець атрыманыя прамежкавыя вынікі працы сінтэзатара.
- Прамежкавыя дадзеныя працы СМТ можна спампаваць, прайшоўшы па адпаведных спасылках «спампаваць».
У вокнах прамежкавых вынікаў працы СМТ выводзіцца разнастайная інфармацыя пра ўведзены тэкст, падрабязна пра якую распаведзена ніжэй.
1. Акно «Токены» адлюстроўвае групіраванне сімвалаў па прыкмеце прыналежнасці да аднаго з 5 відаў сімвалаў:
- alphabet — сімвалы мэтавага алфавіту (мовы, абранай для сінтэзавання);
- letters — любыя іншыя літары (не мэтавага алфавіту);
- digits — лічбы;
- whitespaces — прабельныя сімвалы (прабел, перавод радка, табуляцыя і інш.);
- character — іншыя сімвалы (малюнак 4).
2. У акне «Тэкст» выводзяцца дадзеныя аб усіх словах, знойдзеных сістэмай у тэксце: вызначаныя часціны мовы, тэгі, якія з’яўляюцца скарочаным абазначэннем марфалагічных прыкмет слова (малюнак 4).
3. Акно «Токены з націскамі» дае спіс слоў з прастаўленымі карыстальнікам націскамі (малюнак 4).
4. Акно «Невядомыя токены» дае спіс слоў, якія адсутнічаюць у базе дадзеных сістэмы (малюнак 4).
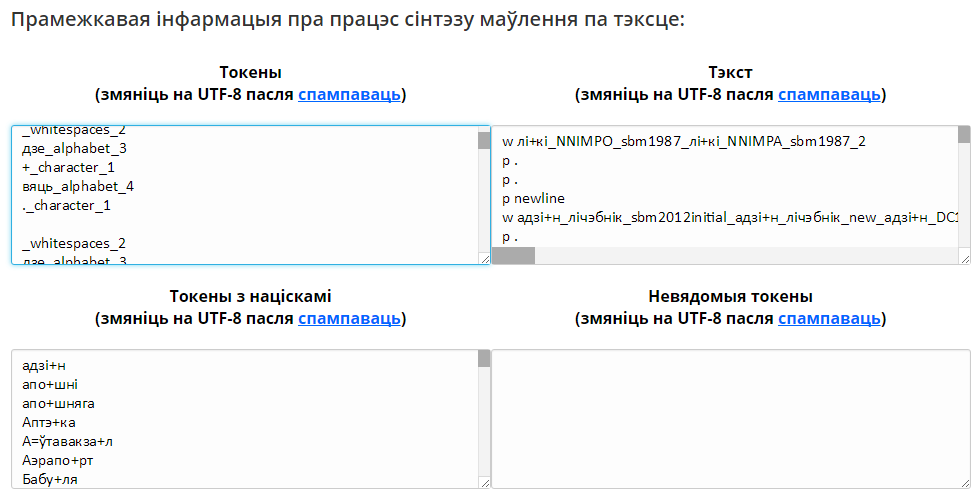
Малюнак 4. Прамежкавыя вынікі працы СМТ: вокны «Токены», «Тэкст», «Токены з націскамі», «Невядомыя токены»
5. Акно «Амографы» дае інфармацыя аб словах, якія маюць неадназначную пазіцыю націска. Спрабуючы вызначыць пазіцыю націска ў слове, сінтэзатар маўлення па тэксце правярае кожнае слова ўваходнага тэксту на наяўнасць некалькіх спосабаў іх прачытання паводле інфармацыі, прадстаўленай у слоўніках. Адбываецца пошук слоў з аднолькавым напісаннем і рознымі націскамі (малюнак 5).
6. У акне «Інтанацыйныя пазнакі» карыстальнік атрымлівае інфармацыю пра інтанацыйную разметку (малюнак 5).
7. У акне «Фанемны тэкст» карыстальнік атрымлівае спіс слоў у фанемным выглядзе (малюнак 5).
8. У акне «Алафонны тэкст» карыстальнік атрымлівае спіс слоў у алафонным выглядзе (малюнак 5).
9. У акне «Характарыстыкі алафонаў» можна пабачыць працягласці і частоты алафонаў (малюнак 5).
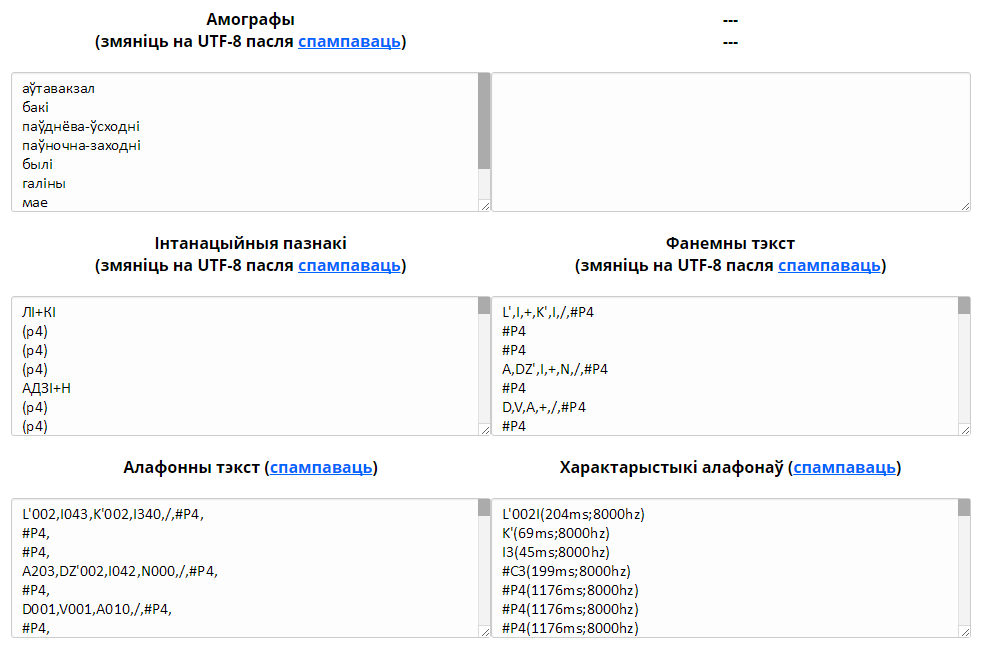
Малюнак 5. Прамежкавыя вынікі працы СМТ: вокны «Амографы», «Інтанацыйныя пазнакі», «Фанемны тэкст», «Алафонны тэкст», «Характарыстыкі алафонаў»
Дадатковай функцыяй сінтэзатара з’яўляецца генерацыя транскрыпцыі ўваходнага тэксту ў 4 фарматах: кірылічная, міжнародная (IPA), спрошчаная міжнародная і X-SAMPA (малюнак 4). Больш падрабязна пра кожны з фарматаў можна даведацца, скарыстаўшыся прыведзенымі на старонцы сэрвісу “Генератар транскрыпцый” спасылкамі на электронныя крыніцы, паводле якіх вялася распрацоўка.

Малюнак 6. Прамежкавыя вынікі працы СМТ: чатыры фарматы транскрыпцый
Доступ да сэрвіса праз API
Для доступу да сэрвіса “Сінтэзатар маўлення па тэксце” праз API, неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/TextToSpeechSynthesizer/api.php. Праз масіў data перадаюцца наступныя параметры:
- text — адвольны тэкст на беларускай або рускай мове.
- language — мова тэксту. Даступны беларуская (параметр be) і руская (параметр ru) мовы.
- voice — голас, якім будзе агучаны тэкст.
- для беларускай мовы даступны галасы AlesiaBel, AlesiaBel (dictation mode), BorisBel, BorisBel (dictation mode), BorisBelHigh;
- для рускай — AlesiaRus, AlesiaRus (dictation mode), BorisRus, BorisRus (dictation mode), BorisRusHigh.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/TextToSpeechSynthesizer/api.php“,
data:{
“text”: “Груша цвіла апошні год.”,
“language”: “be”,
“voice”: “BorisBel”
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з наступнымі параметрамі:
- status — статус апрацоўкі.
- text — уваходны тэкст.
- Вынікі такенізацыі:
- charactersText — вынік;
- charactersUrl — электронны адрас, дзе захаваны вынік.
- Вынікі працы тэкставага працэсара:
- tokensText — вынік;
- tokensUrl — электронны адрас, дзе захаваны вынік.
- Спіс токенаў з націскамі, пазначанымі карыстальнікам:
- stressedText — спіс;
- stressedUrl — электронны адрас, дзе захаваны спіс.
- Спіс слоў, адсутных у базе сінтэзатара:
- unknownText — спіс;
- unknownUrl — электронны адрас, дзе захаваны спіс.
- Спіс амографаў, знойдзеных ва ўваходным тэксце:
- homographsText — спіс;
- homographsUrl — электронны адрас, дзе захаваны спіс.
- Вынікі працы інтанацыйнага працэсара:
- prosodicText — вынік;
- prosodicUrl — электронны адрас, дзе захаваны вынік.
- Прамежкавы вынік працы фанетычнага працэсара — фанемны тэкст:
- phonemicText — вынік;
- phonemicUrl — электронны адрас, дзе захаваны вынік.
- Прамежкавы вынік працы фанетычнага працэсара — алафонны тэкст:
- allophonicText — вынік;
- allophonicUrl — электронны адрас, дзе захаваны вынік.
- Спіс алафонаў з характарыстыкамі:
- allophoneCharacteristicsText — спіс;
- allophoneCharacteristicsUrl — электронны адрас, дзе захаваны спіс.
- talkingHeadCharacteristics — характарыстыкі алафонаў, неабходныя для працы сэрвіса «Сінтэзатар “Гаворачая галава”».
- transcriptionCyr — транскрыпцыя ў кірылічным фармаце.
- transcriptionLat — транскрыпцыя ў фармаце спрошчанага міжнароднага фанетычнага алфавіту.
- transcriptionIPA — транскрыпцыя ў фармаце МФА (Міжнародны фанетычны алфавіт).
- transcriptionXSAMPA — транскрыпцыя ў фармаце X-SAMPA.
- audio — спасылка на згенераваны аўдыяфайл.
Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“status”: “success”,
“text”: “Груша цвіла апошні год.”,
“charactersText”: “Груша_груша_word_cyrillic
цвіла_цвіла_word_cyrillic
апошні_апошні_word_cyrillic
год_год_word_cyrillic
._._other
_newline_other”,
“charactersUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_characters.html”,
“tokensText”: “w гру+ша_НевядомаяКатэгорыя_sbm2012initial_гру+ша_NNIFO_sbm1987_гру+ша_NFN1_noun2013_3
w цвіла+_VIIPF_sbm1987_цвіла+_дзеяслоў_verb2013_цвіла+_?_words_processed_3
w апо+шні_НевядомаяКатэгорыя_sbm2012initial_апо+шні_JJMO_sbm1987_апо+шні_JJMA_sbm1987_апо+шні_прыметнік_adjective2013_апо+шні_прыметнік_adjective2013_5
w го+д_НевядомаяКатэгорыя_sbm2012initial_го+д_NNIMO_sbm1987_го+д_NNIMA_sbm1987_го+д_NMN1_noun2013_го+д_NMA1_noun2013_5
p .
p newline”,
“tokensUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_tokens.html”,
“stressedText”: “”,
“stressedUrl”: “https://corpus.by/TextToSpeechSynthesizer/null”,
“unknownText”: “”,
“unknownUrl”: “https://corpus.by/TextToSpeechSynthesizer/null”,
“homographsText”: “”,
“homographsUrl”: “https://corpus.by/TextToSpeechSynthesizer/null”,
“prosodicText”: “ГРУ+ША
ЦВІЛА+
АПО+ШНІ
ГО+Д
(p4)
(p4)”,
“prosodicUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_intonationalText.txt”,
“phonemicText”: “GH,R,U,+,SH,A,/,C’,V’,I,L,A,+,/,A,P,O,+,SH,N’,I,/,GH,O,+,T,/,#P4”,
“phonemicUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_phonemicText.txt”,
“allophonicText”: “GH004,R022,U022,SH002,A323,/,C’002,V’002,I241,L002,A012,/,A221,P001,O012,SH002,N’004,I242,/,GH001,O032,T000,/,#P4,”,
“allophonicUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_allophonicText.txt”,
“allophoneCharacteristicsText”: “GH(65ms;8000hz)
R(43ms;8000hz)
U0(140ms;8000hz)
SH(106ms;8000hz)
A3(50ms;8000hz)
#C3(53ms;8000hz)
C'(80ms;8000hz)
V'(61ms;8000hz)
I2(70ms;8000hz)
L(78ms;8000hz)
A0(141ms;8000hz)
#C3(53ms;8000hz)
A2(70ms;8000hz)
P(106ms;8000hz)
O0(120ms;8000hz)
SH(106ms;8000hz)
N'(54ms;8000hz)
I2(70ms;8000hz)
#C3(53ms;8000hz)
GH(79ms;8000hz)
O0(140ms;8000hz)
T(145ms;8000hz)
#C3(53ms;8000hz)
#P4(1176ms;8000hz)”,
“allophoneCharacteristicsUrl”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-50-16_80-94-171-2_298_be_allophoneCharacteristics.txt”,
“transcriptionCyr”: “[γру́ша] [ц’в’іла́] [апо́шн’і] [γо́т]”,
“transcriptionLat”: “[ɣrúʂa] [t͡s’v’ilá] [apóʂn’i] [ɣót]”,
“transcriptionIPA”: “[ɣruʂa] [ʦʲvʲila] [apɔʂnʲi] [ɣɔt]”,
“transcriptionXSAMPA”: “[Grus`a] [ʦ’v’ila] [apOs`n’i] [GOt]”,
“audio”: “https://corpus.by/_cache/TextToSpeechSynthesizer/out/2019-09-03_17-38-19_80-94-171-2_975_be_ssrlab.wav”
}
]
Спасылкі на крыніцы
Старонка сэрвісу: https://corpus.by/TextToSpeechSynthesizer/
Старонка сэрвісу «Сінтэзатар “Гаворачая галава”»: https://corpus.by/TalkingHeadSynthesizer/?lang=be
Старонка сэрвісу «Прагназаванне працягласці прамовы»: https://corpus.by/SpeechDurationPredictor/?lang=be
Перакрыжаваныя спасылкі
- Алгарытмы лінгвістычнай апрацоўкі тэкстаў для сінтэзу маўлення на беларускай і рускай мовах : дысертацыя на атрыманне навуковай ступені кандыдата тэхнічных навук : спецыяльнасць 05.13.01 Сістэмны аналіз, кіраванне і апрацоўка інфармацыі / Гецэвіч Юрый Станіслававіч ; навуковы кіраўнік Лабанаў Б. М. ; Аб’яднаны інстытут праблем інфарматыкі Нацыянальнай акадэміі навук Беларусі. — Мінск, 2012. — 184, [6] л. : іл., табл., схемы. — Ч. тэксту рус. — Бібліягр.: л. 153-164.
- Гецэвіч, Ю.С. Мабільная праграма як сродак для навучання беларускай мове / Ю.С. Гецэвіч, М.У. Марчык, Н.Д. Казлоўская, М.В. Шыбко, Д.А. Дзенісюк, Э.У. Русецкая // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы I Респ. науч.-практ. конф. с междунар. участием, Минск, 23–24 февр. 2017 г. / БГУ, факультет социокультурных коммуникаций ; редкол. : О.Г. Прохоренко (отв. ред.) [и др.]. — Минск : Изд. центр БГУ, 2017. — C. 102-103.
- Захарьев, В.А. Мультиголосовой синтез речи по тексту для построения естественно-языковых интерфейсов интеллектуальных систем / В.А. Захарьев, А.А. Петровский // Открытые семантические технологии проектирования интеллектуальных систем = Open Semantic Technologies for Intelligent Systems : материалы междунар. науч.-техн. конф. Вып. 1 (Минск, 16-18 февраля 2017 г.). / редкол. : В.В. Голенков (отв. ред.) [и др.]. — Минск : БГУИР, 2017. — C. 167-170.
- Лысы С.І. Генерацыя нацыянальнай транскрыпцыі тэкстаў на беларускай мове / С.І. Лысы, Ю.С. Гецэвіч // Інфарматыка. — 2017. — №54. — C. 84-92.
- Захарьев, В.А. Подход к устранению речевых неоднозначностей на основе семантико-акустического анализа / В.А. Захарьев, И.С. Азарьев, К.В. Русецкий // Открытые семантические технологии проектирования интеллектуальных систем = Open Semantic Technologies for Intelligent Systems : материалы междунар. науч.-техн. конф. Вып. 2 (Минск, 15-17 февраля 2018 г.). / БГУИР ; редкол.: В.В. Голенков [и др.]. — Минск : БГУИР, 2018. — C. 211-222.
- Дзенісюк, Д. А. Праграмаванне калькулятара з убудаванымі галасавымі функцыямі / Д. А. Дзенісюк, М. У. Марчык, А. В. Крывальцэвіч, Н. Д. Казлоўская // Веб-программирование и интернет-технологии WebConf2018: тез. докл. 4-й Междунар. науч.-практ. конф., Минск, 14–18 мая 2018 г. / Белорус. гос. ун-т ; редкол.: И. М. Галкин (отв.ред.) [и др.]. — Минск : БГУ, 2018. — C. 21.
- Захарьев, В.А. Семантический анализ речевых сообщений на основе формализованного контекста / В.А. Захарьев, Т.В. Ляхор, А.В. Губаревич, И.С. Азаров // Открытые семантические технологии проектирования интеллектуальных систем : сборник научных трудов. Выпуск 3. / БГУИР ; редкол.: В.В. Голенков [и др.]. – Минск : БГУИР, 2019. – C. 103-112.
- Гецэвіч, Ю.С. Праектаванне натуральна-моўных інтэрфейсаў для даведкавых сістэм / Ю.С. Гецэвіч, У.А. Жытко, С.А. Гецэвіч, Л.І. Кайгародава, К.А. Нікалаенка // Інфарматыка. – 2019. – Т. 16, № 3. – С. 37-47.
- Лобанов, Б.М. Ретроспективный обзор исследований и разработок лаборатории распознавания и синтеза речи / Б.М. Лобанов // Автоматическое распознавание и синтез речи: сб. науч. тр. – Минск: ИТК НАН Беларуси, 2000. – С. 6-24.
- Lobanov, B.M. Allophonic text-to-speech synthesizer: general structure and description / B.M. Lobanov // Автоматическое распознавание и синтез речи: сб. науч. тр. – Минск: ИТК НАН Беларуси, 2000. – С. 43-53.
- Гецэвіч, Ю.С. Праектаванне інтэрнэт-сервісаў для працэсараў сінтэзатара маўлення па тэксце з магчымасцю прадстаўлення бясплатных электронных паслуг насельніцтву / Ю.С. Гецэвіч, С.І. Лысы // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2014) : доклады XIII Международной конференции (Минск, 20 ноября 2014 г.). – Минск : ОИПИ НАН Беларуси, 2014. — C. 265-269.
- Захарьев, В.А. Алгоритм текстонезависимого обучения для систем мультиголосового синтеза речи / В.А. Захарьев, А.А. Петровский // Информационные технологии и системы (ИТС-2016) / БГУИР ; редкол. : Л.Ю. Шилина [и др.]. — Минск : БГУИР, 2016. — C. 90-91.
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Гецэвіч, Ю.С. Распрацоўка сістэм уводу і вываду гукавой інфармацыі ў інтэрнэце / Ю.С. Гецэвіч, В.Л. Аляхно, Я.С. Зяноўка, С.І. Лысы // Информационные технологии и системы (ИТС-2016) / БГУИР ; редкол. : Л.Ю. Шилин [и др.]. — Минск : БГУИР, 2016. — C. 102-103.
- Качан, Я.С. Збор мноства маўленчых фраз для тэставання сістэм сінтэзу і распазнавання маўлення па семантычных класах “плошча”, “аб’ём” / Я.С. Качан, А.В. Крывальцэвіч, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 258-262.
- Качан, Я. С. Праблемы апрацоўкі колькасных выразаў з адзінкамі вымярэння на прыкладзе дыстанцыі, даўжыні, хуткасці і памеру для англійскай і беларускай моў / Я. С. Качан, П. А. Маракуліна, А. В. Крывальцэвіч // Актуальные вопросы германской филологии и лингводидактики : материалы XX Междунар. науч.-практ. конф. / Брест. гос. ун-т имени А.С. Пушкина ; редкол. : Е. Г. Сальникова [и др.]. — Брест : Альтернатива, 2016. — C. 257-261.
- Гецэвіч, Ю.С. Аналіз памылак выходных даных інтэрнэт-сінтэзатара беларускага і рускага маўлення па тэксце / Ю.С. Гецэвіч, І.В. Рэянтовіч, С.І. Лысы // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 221-225.
- Гецэвіч, Ю.С. Выкарыстанне сістэм машыннага перакладу і сістэмы сінтэзу маўлення для забеспячэння даступнасці заканадаўчых тэкстаў для людзей з інваліднасцю па зроку / Ю.С. Гецэвіч, В.В. Варановіч, А.У. Бабкоў // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2019) : доклады XVIII Международной конференции, Минск, 21 ноября 2019 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. – Минск : ОИПИ НАН Беларуси, 2019. – C. 190-193.
- Гецевич, Ю.С. Система синтеза белорусской речи по тексту / Ю.С. Гецевич, Б.М. Лобанов // Речевые технологии. – 2010. – № 1. – С. 91-100.
- Гецэвіч, Ю.С. Распрацоўка сінтэзатара беларускага і рускага маўленняў па тэксце для мабільных і інтэрнэт-платформаў / Ю.С. Гецэвіч, Д.А. Пакладок, Д.В. Брэк // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2012) : доклады XI Международной конференции (Минск, 15 ноября 2012 г.). – Минск : ОИПИ НАН Беларуси, 2012. – С. 254–259.
- Гецэвіч, Ю.С. Выкарыстанне сістэм машыннага перакладу і сістэмы сінтэзу маўлення для забеспячэння даступнасці заканадаўчых тэкстаў для людзей з інваліднасцю па зроку / Ю.С. Гецэвіч, В.В. Варановіч, А.У. Бабкоў // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2019) : доклады XVIII Международной конференции, Минск, 21 ноября 2019 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. – Минск : ОИПИ НАН Беларуси, 2019. – C. 190-193.