The «Voice Activity Detector» service allows user to receive a detailed analysis of the audio recording spectrogram to identify periods of voice activity and the intervals between them. It is possible to obtain results (a list of periods of voice activity or pauses with an indication of time with an accuracy of 10 milliseconds) in the form of subtitles or tags for the Audacity program. Using a special button, the user can pack the processing results into an SRT file and download it. The service works only with audio recordings in WAV format. The voice activity recognition algorithm used by the service is implemented in Python with the active use of the freely distributed libraries NumPy and SciPy capabilities. In its initial form, the algorithm is fast, accurate, reliable, and undemanding to system resources, but at the same time it is noise-resistant (the last property practically does not depend on the nature of the noise), what has been demonstrated by special comparative examinations (see the section «Source references»). An improvement of the algorithm made by the Speech Synthesis and Recognition Laboratory is the preliminary removal of noises.
Basic terms and concepts
Voice activity detection (VAD) – revealing of voice activity in the input acoustic signal to separate active speech from background noise or silence.
Noise – a combination of non-periodic sounds of various intensities and frequencies, random fluctuations of various physical nature, characterized by the complexity of the temporal and spectral structure.
NumPy – the open source library for the Python programming language. The capabilities of this library include support for multidimensional arrays (including matrices), as well as various high-level mathematical functions designed to work with such arrays.
SciPy – the open source library for the Python programming language, designed to perform scientific and engineering calculations. The most popular features of this library in the «Voice Activity Detector» service are the functions designed for signal processing.
WAV-format (Waveform Audio File Format) – a format of container file for storing recordings of digitized audio stream, a subset of RIFF (Resource Interchange File Format). This format is traditionally associated with the Windows operating system (although it is also common in the Linux OS family) and is most often used to preserve the original appearance of high-quality audio files.
SRT file – a text file containing subtitles that are used by various audio and video playback programs. The text information that is stored in the .srt file can be modified by any text editor.
Practical value
Voice activity detection (VAD) is a critical problem in many audio stream analysis systems, including speech coding, speech recognition, speech optimization, and audio indexing systems. A well-developed VAD algorithm significantly improves the quality of such systems in terms of accuracy and processing speed (including processing voice messages in noisy environments).
VAD allows to save resources during data transmission by the communication channel, because the interruption in speech is not digitized and not encoded, and thus «empty» packets with silence are not transmitted over the network. This is very important for packet transmission (which, for example, is transmission in TCP/IP networks), because, in addition to the data itself, each protocol of all levels of the OSI model (transport, network, etc.) appends its own service information to each packet with data; as a result of this, the packet size grows significantly. Skipping of «empty» packets with small noises is an easy way to save traffic and, as a result, increase the channel capacity. For this reason, the VAD mechanism is often used, along with various effective compression codecs, in IP-telephony.
A special case of using the results of audio recordings processing packaged by the service in the SRT format can be facilitating of the work of creating subtitles for audio and video files.
It is also important that most of the current VAD algorithms show good results when working with a «clean» audio stream, but in the case of noisiness, they lose their effectiveness. The algorithm on which the service is based is characterized by high noise resistance. This algorithm is presented by M.H. Moattar and M.M. Homayounpour in the work «A simple but efficient real-time voice activity detection algorithm» (17th European Signal Processing Conference, 2009) and it is a step forward in compare with existing solutions. Active use of the service will make it possible to popularize this algorithm, as well as collect factual data for its further improvement (in particular, refinement of input constants).
Service features
The algorithm described in the above work of M.H. Moattar and M.M. Homayounpour, implemented in the service using the tools of the Python language, but it is not presented only in its «pristine» form. An employee of the Laboratory for Speech Synthesis and Recognition Kalabuk D.S. made additions to the algorithm – in particular, preliminary noise removal was added, and some mathematical improvements were introduced to ensure faster and more accurate operation.
For the same purposes, as well as for practical software implementation, we allowed ourselves to deviate from the values of the constants recommended by the authors of the algorithm, replacing them with our own values. The minimum durations of audio segments perceived by the service as periods of voice activity (35 milliseconds versus 50 milliseconds in the original algorithm) and periods of silence (200 milliseconds versus 100 milliseconds) are also changed.
Service operation algorithm
Algorithm input data:
- Test audio file or audio file uploaded by the user or recorded using a microphone, Audiofile;
- Constants:
- The length of the analyzed frame, FRAME_LENGTH_MS. Equals to 10 milliseconds;
- The minimum duration of an audio file segment that can be considered by a service as a segment of voice activity, MIN_VOICE_DURATION. Equals to 35 milliseconds;
- The minimum duration of an audio file segment that can be considered by a service as a pause, MIN_PAUSE_DURATION. Equals to 200 milliseconds;
- The primary threshold for energy, Energy_PrimThresh. Equals to 0,015;
- The primary threshold of the dominant frequency component of the speech spectrum, F_PrimTresh. Equals to 7;
- The primary threshold of the Spectral Flatness Measure (SFM), SF_PrimThresh. Equals to 0,75;
- The noise threshold, NOISE_LEVEL. Equals to 0,07;
- User options:
- Fragments of the audio stream defined by the service, Fragments. It can take two options – voice activity (activity) or pauses (pauses);
- Format for the service output, Format. It can take two options – subtitles (srt) or labels (audacity).
The beginning of the algorithm.
Step 1.1. Reading digital data of Audiofile using SciPy library methods and recording it into a multidimensional array using NumPy library methods.
Step 1.2. Dividing the array into frames according to the value of FRAME_LENGTH_MS. No frame overlap is allowed. Counting the total number of frames (Num_Of_Frames).
Step 2. Preliminary normalization of the frames array, noise removal.
Step 3. Sequentially for each frame (for i = 0; i <Num_Of_Frames; i ++):
Step 3.1 Computing frame energy (E (i)).
Step 3.2 Apply Fast Fourier Transform to each speech frame.
Step 3.2.1. Finding the dominant frequency component of the speech spectrum (F (i)) by the formula F (i) = argkmax (S(k)), where S(k) is the frame frequency corresponding to the maximum spectral value.
Step 3.2.2. Calculation of the abstract value of the spectral flatness measure, SFM(i), according to the formula SFMdb = 10log10(Gm/Am), where Am and Gm are the arithmetic mean and geometric mean of the speech spectrum respectively.
Step 3.3. Supposing that some of the first 30 frames are silence. Calculation of the minimum value of the frame energy (Min_E), the minimum value of the dominant frequency component of the speech spectrum of the frame (Min_F) and the minimum value of the spectral flatness measure (Min_SF).
Step 3.4. Setting of the following decision thresholds for frame energy (Thresh_E), the dominant frequency component of the speech spectrum of the frame (Thresh_F), spectral flatness measure (Thresh_SF):
- Thresh_E = Energy_PrimThresh*log(Min_E);
- Thresh_F = F_PrimThresh;
- Thresh_SF = SF_Prim_Thresh.
Step 3.5. Initialization of the variable Counter = 0. Checking the following conditions:
- If (E(i) – Min_E) >= Thresh_E, then increment Counter;
- If (F(i) – Min_F) >= Thresh_F, then increment Counter;
- If (SFM(i) – Min_SF) >= Thresh_SF, then increment Counter.
Step 3.6. If Counter > 1, mark the current frame as speech (true), otherwise mark it as silence (false).
Step 3.7. If the current frame is marked as silence, update the minimum frame energy value (Min_E) using the following formula:
Min_E =
where SilenceCount is the current number of frames marked as silence.
Step 3.8 Update the Thresh_E value according to the formula Thresh_E = Energy_PrimThresh * log (Min_E).
Step 4. Ignore the sequence of silence frames lasting less than MIN_PAUSE_DURATION. Ignore speech frames lasting less than MIN_VOICE_DURATION.
Step 5.1. If the user requested pauses detection, invert the sequence of sounding speech and pauses (technically, replace true with false and vice versa).
Step 5.2. Generate user output according to the Format value.
Step 6. Present the user the processing results in the subtitle format SRT.
The end of the algorithm
User interface description
The user interface has two areas: the data input area and the output area. The appearance of the interface is shown in Figure 1.
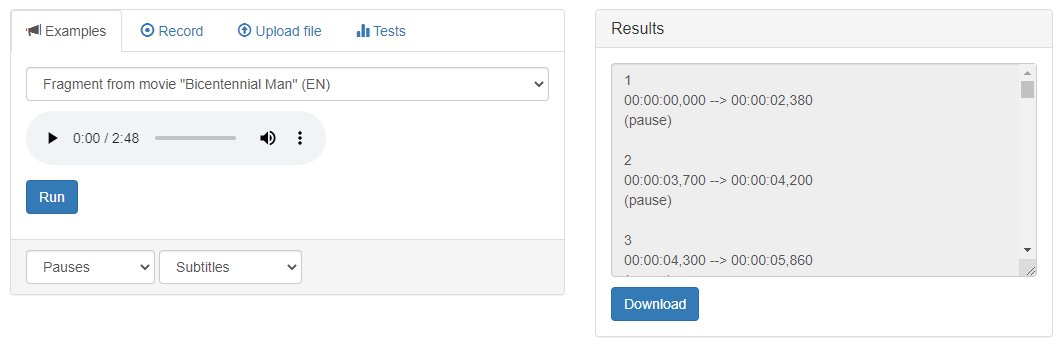
Figure 1 – The graphical interface of the service «Voice Activity Detector»: data input area (left) and output area (right)
The data input area is divided into 4 other areas: «Examples», «Record», «Upload file», «Tests».
Area «Examples»
The appearance of the «Examples» area is shown in Figure 2.
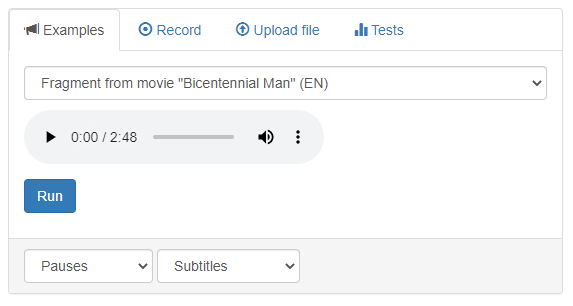
Figure 2 – Graphical interface of the «Examples» area
The area interface contains the following elements:
- Drop-down menu for selecting an example (each example is available for download);
- Audio player to play the selected file;
- The «Run» button that initializes processing;
- Drop-down menu for selecting the type of fragments in the final output (it has the items «Pauses» and «Voice activity»);
- Drop-down menu for selecting the format of the final output (it has the items «Subtitles» and «Audacity labels»).
Area «Record»
The appearance of the «Record» area is shown in Figure 3.
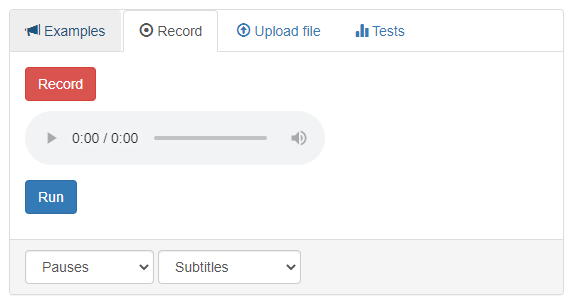
Figure 3 – Graphical interface of the «Record» area
The area interface contains the following elements:
- The «Record» button that starts recording the audio file via the computer microphone (after pressing it turns into the «Stop» button);
- Player for playing recorded audio;
- The «Run» button that initializes processing;
- Drop-down menu for selecting the type of fragments in the final output (it has the items «Pauses» and «Voice activity»);
- Drop-down menu for selecting the format of the final output (it has the items «Subtitles» and «Audacity labels»).
Area «Upload file»
The appearance of the «Upload file» area is shown in Figure 4.

Figure 4 – Graphical interface of the «Upload file» area
The area interface contains the following elements:
- The «Select …» button, which initializes the opening of a window for selecting a file on the user’s computer;
- Status bar displaying data regarding file uploading;
- The «Upload» button for uploading a file from a computer and initiating processing;
- Drop-down menu for selecting the type of fragments in the final output (it has the items «Pauses» and «Voice activity»);
- Drop-down menu for selecting the format of the final output (it has the items «Subtitles» and «Audacity labels»).
Area «Tests»
The «Tests» area is intended for visual presentation to the user of data about the quality of the algorithm. The appearance of the area is shown in Figure 5.
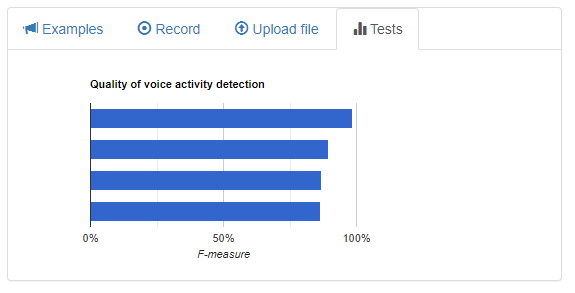
Figure 5 – Graphical interface of the «Tests» area
The area interface contains a line diagram that displays the values of F-measures to illustrate the quality of analysis of:
- synthesized speech;
- studio recording;
- studio recording with white noise;
- movie fragment.
(values are listed in the order they appear from top to bottom)
To get the most accurate data, it is necessary to move the mouse cursor on the desired line of the diagram.
Output area
The appearance of the output area is shown in Figure 6.

Figure 6 – Graphical interface of the output area
The area interface contains the following elements:
- The field for issuing results that contains the results of previous processing;
- The «Download» button that appears after completion of at least one processing. It initializes the download of the SRT file to the user’s computer.
User scenarios of work with the service
Scenario 1. Analysis of examples.
- Go to the «Examples» tab.
- Select the desired audio file (example) via the special menu.
- If necessary, listen to the audio file using the player and/or download the audio recording.
- Select the type of fragments, the data about which will be presented in the processing results («Pauses» or «Voice activity»).
- Select the format for the presentation of processing results («Subtitles» or «Audacity labels»).
- Click the «Run» button.
- Get the processing results in the output field.
- If necessary, click the «Download» button to download the SRT file with the processing results.
Scenario 2. Analysis of audio recordings created using a user’s microphone.
- Go to the «Record» tab.
- Press the «Record» button to initiate recording, make a record, press the «Stop» button to stop recording.
- If necessary, listen to the recorded file using the player.
- Select the type of fragments, the data of which will be presented in the processing results («Pauses» or «Voice Activity»).
- Select the format for the presentation of processing results («Subtitles» or «Audacity labels»).
- Click the «Run» button.
- Get the processing results in the output field.
- If necessary, click the «Download» button to download the SRT file with the processing results.
Scenario 3. Analysis of the user audio file.
- Go to the “Upload file” tab.
- Press the «Select…» button.
- In the dialog box that opens, select the audio file in the WAV format on the computer. Information about the file will be presented in the status bar.
- Select the type of fragments, the data of which will be presented in the processing results («Pauses» or «Voice Activity»).
- Select the format for the presentation of processing results («Subtitles» or «Audacity labels»).
- Click the «Upload» button to upload the audio file and initiate processing.
- Get the processing results in the output field.
- If necessary, click the «Download» button to download the SRT file with the processing results.
The possible result of the service work according to scenarios 1–3 is shown in Figure 7.
Figure 7 – The result of the service «Voice Activity Detector» work
Scenario 4. Obtaining information about the quality of the service work.
- Go to the «Tests» tab.
- In the tab that opens, move the mouse cursor over the necessary line of the diagram and see the test results.
Access to the service via the API
Access via the API is not provided for this service.
Source references
Service page – https://corpus.by/VoiceActivityDetector/?lang=ru
Moattar, M.H. A simple but efficient real-time voice activity detection algorithm / M.H. Moattar, M.M. Homayounpour [Electronic resource] // 17th European Signal Processing Conference (EUSIPCO 2009), Glasgow, Scotland, August 24-28, 2009. – Mode of access: https://www.eurasip.org/Proceedings/Eusipco/Eusipco2009/contents/papers/1569192958.pdf. – Date of access: 01.06.2020.
NumPy library – https://numpy.org/.
SciPy library – https://www.scipy.org/.