Сэрвіс «Вызначэнне галасавой актыўнасці» дае магчымасць карыстальніку атрымаць падрабязны аналіз спектраграмы аўдыязапісу на прадмет выдзялення ў ёй перыядаў галасавой актыўнасці і прамежкаў паміж імі. Прадугледжана магчымасць атрымання вынікаў (спісу перыядаў галасавой актыўнасці альбо паўз з указаннем часу з дакладнасцю да 10 мілісекунд) у выглядзе субтытраў альбо метак для праграмы Audacity. З дапамогай спецыяльнай кнопкі можна ўпакаваць вынікі апрацоўкі ў SRT-файл і спампаваць. Сэрвіс працуе толькі з аўдыязапісамі ў фармаце WAV. Алгарытм распазнавання галасавой актыўнасці, які выкарыстоўваецца сэрвісам, рэалізаваны на мове Python з актыўным прымяненнем магчымасцей бібліятэк NumPy і SciPy, якія распаўсюджваюцца свабодна. У сваім зыходным выглядзе алгарытм хуткі, дакладны, надзейны, непатрабавальны да сістэмных рэсурсаў, аднак разам з тым шумаўстойлівы (апошняя ўласцівасць практычна не залежыць ад характару шуму), што было прадэманстравана спецыяльнымі параўнальнымі даследаваннямі (гл. раздзел «Спасылкі на крыніцы»). Удасканаленнем алгарытму з боку лабараторыі распазнавання і сінтэзу маўлення з’яўляецца папярэдняе выдаленне шумаў.
Асноўныя тэрміны і паняцці
Распазнаванне галасавой актыўнасці (англ. VAD – Voice Activity Detection) – выяўленне галасавой актыўнасці ва ўваходным акустычным сігнале для аддзялення актыўнага маўлення ад фонавага шуму або цішыні.
Шум – сукупнасць неперыядычных гукаў рознай інтэнсіўнасці і частаты, бязладныя ваганні рознай фізічнай прыроды, якія адрозніваюцца складанасцю часавай і спектральнай структуры.
NumPy – бібліятэка з адкрытым зыходным кодам для мовы праграмавання Python. Магчымасці дадзенай бібліятэкі ўключаюць падтрымку шматмерных масіваў (уключаючы матрыцы), а таксама разнастайныя высакаўзроўневыя матэматычныя функцыі, прызначаныя для працы з такімі масівамі.
SciPy – бібліятэка для мовы праграмавання Python з адкрытым зыходным кодам, прызначаная для выканання навуковых і інжынерных разлікаў. Найбольш запатрабаванымі ў сэрвісе «Вызначэнне галасавой актыўнасці» магчымасцямі бібліятэкі з’яўляюцца функцыі, прызначаныя для апрацоўкі сігналаў.
WAV-фармат (Waveform Audio File Format, ад англ. waveform – «у форме хвалі») – фармат файла-кантэйнера для захавання запісу алічбаванага аўдыяпатоку, падвід RIFF (англ. Resource Interchange File Format). Гэты фармат традыцыйна асацыюецца з аперацыйнай сістэмай Windows (хаця таксама распаўсюджаны ў АС сямейства Linux) і часцей за ўсё выкарыстоўваецца для захавання першапачатковага выгляду аўдыяфайлаў высокай якасці.
SRT-файл – гэта тэкставы файл, які ўтрымлівае субтытры, якія выкарыстоўваюцца рознымі праграмамі ўзнаўлення аўдыя і відэа. Тэкставая інфармацыя, якая захоўваецца ў файле .srt, можа быць зменена любым тэкставым рэдактарам.
Практычная каштоўнасць
Распазнаванне галасавой актыўнасці (РГА) з’яўляецца крытычна важнай праблемай у многіх сістэмах аналізу аўдыяпатоку, уключаючы сістэмы кадзіравання маўлення, распазнавання маўлення, маўленчай аптымізацыі, аўдыяіндэксацыі. Добра распрацаваны алгарытм РГА значна паляпшае якасць такіх сістэм з пункту гледжання дакладнасці і хуткасці апрацоўкі (у т.л. апрацоўкі галасавых паведамленняў у шумным акружэнні).
РГА дазваляе эканоміць на перадачы дадзеных па канале сувязі, паколькі перарыў у маўленні не алічбоўваецца і не кадзіруецца і, такім чынам, «пустыя» пакеты з цішынёй не перадаюцца па сетцы. Гэта вельмі важна для пакетнай перадачы (якой з’яўляецца, напрыклад, перадача ў сетках TCP/IP), паколькі, апроч саміх дадзеных, кожны пратакол усіх узроўняў мадэлі OSI (транспартны, сеткавы і г.д.) дапісвае сваю ўласную службовую інфармацыю ў кожны пакет з дадзенымі, у выніку чаго памер пакета значна вырастае. Выключэнне «пустых» пакетаў з дробнымі шумамі – просты спосаб эканоміць трафік і, як наступства, павялічваць прапускную здольнасць канала. Па гэтай прычыне механізм РГА даволі часта прымяняецца, разам з рознымі кодэкамі эфектыўнага сціскання, у IP-тэлефаніі.
Прыватным выпадкам выкарыстання вынікаў апрацоўкі аўдыязапісаў, упакаваных сэрвісам у SRT-фармат, можа быць палягчэнне працы па стварэнні субтытраў да аўдыя- і відэафайлаў.
Немалаважна таксама тое, што большасць вядомых на сённяшні дзень алгарытмаў РГА паказваюць высокія вынікі пры працы з «чыстым» аўдыяпатокам, аднак у выпадку яго зашумленасці страчваюць сваю эфектыўнасць. Алгарытм, на якім заснавана работа сэрвіса, прадстаўлены ў рабоце М.Х. Моатара і М.М. Хомаянпура «A simple but efficient real–time voice activity detection algorithm» (17-ая Еўрапейская канферэнцыя па апрацоўцы сігналаў, 2009) і з’яўляецца крокам наперад у параўнанні з існуючымі рашэннямі. Актыўнае выкарыстанне сэрвіса дазволіць папулярызаваць дадзены алгарытм, а таксама сабраць фактычныя дадзеныя для яго далейшага паляпшэння (у прыватнасці, удакладнення ўваходных канстант).
Асаблівасці сэрвіса
Алгарытм, апісаны ў названай вышэй рабоце М.Х. Моатара і М.М. Хомаянпура, рэалізаваны ў сэрвісе з дапамогай сродкаў мовы Python, аднак не прадстаўлены толькі ў сваім «першапачатковым» выглядзе. Супрацоўнікам лабараторыі распазнавання і сінтэзу маўлення Калабукам Д.С. былі ўнесеныя дапаўненні ў алгарытм – у прыватнасці, дадазена папярэдняе выдаленне шумаў, а таксама ўкаранёныя некаторыя матэматычныя паляпшэнні для забеспячэння больш хуткай і дакладнай работы. У гэтых жа мэтах, а таксама ў мэтах практычнай праграмнай рэалізацыі мы дазволілі сабе адступіць ад значэнняў канстант, рэкамендаваных аўтарамі алгарытму, замяніўшы іх на ўласныя значэнні. Змененыя таксама мінімальныя працягласці адрэзкаў аўдыязапісу, якія ўспрымаюцца сэрвісам у якасці перыядаў галасавой актыўнасці (35 мілісекунд супраць 50 мілісекунд у арыгінальным алгарытме) і перыядаў цішыні (200 мілісекунд супраць 100 мілісекунд).
Алгарытм работы сэрвіса
Уваходныя дадзеныя алгарытму:
- Тэставы аўдыяфайл альбо аўдыяфайл, загружаны карыстальнікам або запісаны з дапамогай мікрафона, Audiofile;
- Канстанты:
- Даўжыня кадра, які аналізуецца, FRAME_LENGTH_MS. Роўная 10 мілісекундам;
- Мінімальная працягласць адрэзка аўдыяфайла, якая можа лічыцца сэрвісам адрэзкам галасавой актыўнасці, MIN_VOICE_DURATION. Роўная 35 мілісекундам;
- Мінімальная працягласць адрэзка аўдыяфайла, якая можа лічыцца сэрвісам адрэзкам паўзы, MIN_PAUSE_DURATION. Роўная 200 мілісекундам;
- Першаснае парогавае значэнне кароткатэраміновай энергіі, Energy_PrimThresh. Роўнае 0,015;
- Першаснае парогавае значэнне частотнага кампанента маўленчага спектру, які дамініруе, F_PrimTresh. Роўнае 7;
- Першаснае парогавае значэнне меры спектральнай нераўнамернасці (SFM – Spectral Flatness Measure), SF_PrimThresh. Роўнае 0,75;
- Значэнне парогавага ўзроўню шуму, NOISE_LEVEL. Роўнае 0,07;
- Карыстальніцкія опцыі:
- Фрагменты аўдыяпатоку, якія вызначаюцца сэрвісам, Fragments. Можа прымаць два значэнні – галасавая актыўнасць (activity) або паўзы (pauses);
- Фармат вываду вынікаў работы сэрвіса, Format. Можа прымаць два значэнні – субтытры (srt) або меткі (audacity).
Пачатак алгарытму.
Крок 1.1. Счытванне лічбавых дадзеных Audiofile з дапамогай метадаў бібліятэкі SciPy і запіс іх у шматмерны масіў з дапамогай метадаў бібліятэкі NumPy.
Крок 1.2. Разбіццё атрыманага масіву на кадры згодна са значэннем FRAME_LENGTH_MS. Перакрыванне кадраў не дапускаецца. Падлік агульнай колькасці кадраў (Num_Of_Frames).
Крок 2. Папярэдняя нармалізацыя масіву кадраў, выдаленне шумаў.
Крок 3. Паслядоўна для кожнага кадра (for i=0; i<Num_Of_Frames; i++):
Крок 3.1. Падлік кадравай энергіі (E(i)).
Крок 3.2. Прымяненне хуткага пераўтварэння Фур’е да кожнага маўленчага кадра.
Крок 3.2.1. Знаходжанне частотнага кампанента маўленчага спектру, які дамініруе (F(i)), паводле формулы F(i) = argkmax(S(k)), дзе S(k) – частата кадра, якая адпавядае максімальнаму спектральнаму значэнню.
Крок 3.2.2. Вылічэнне абстрактнага значэння меры спектральнай нераўнамернасці кадра, SFM(i), паводле формулы SFMdb = 10log10(Gm/Am), дзе Am і Gm – сярэдняе арыфметычнае і сярэдняе геаметрычнае значэнне маўленчага спектру.
Крок 3.3. Дапушчэнне, што некаторыя з першых 30 кадраў з’яўляюцца цішынёю. Вылічэнне мінімальнага значэння энергіі кадра (Min_E), мінімальнага значэння частотнага кампанента маўленчага спектру кадра (Min_F) і мінімальнага значэння меры спектральнай нераўнамернасці (Min_SF).
Крок 3.4. Устанаўленне наступных парогаў прыняцця рашэння для энергіі кадра (Thresh_E), частотнага кампанента маўленчага спектру кадра, які дамінуе (Thresh_F), меры спектральнай нераўнамернасці (Thresh_SF):
- Thresh_E = Energy_PrimThresh*log(Min_E);
- Thresh_F = F_PrimThresh;
- Thresh_SF = SF_Prim_Thresh.
Крок 3.5. Ініцыялізацыя пераменнай Counter = 0. Праверка наступных умоў:
- Калі (E(i) – Min_E) >= Thresh_E, то інкрэментаваць Counter;
- Калі (F(i) – Min_F) >= Thresh_F, то інкрэментаваць Counter;
- Калі (SFM(i) – Min_SF) >= Thresh_SF, то інкрэментаваць Counter.
Крок 3.6. Калі Counter > 1, адзначыць бягучы кадр як маўленне (true), інакш – адзначыць яго як цішыню (false).
Крок 3.7. Калі бягучы кадр адзначаны як цішыня, абнавіць мінімальнае значэнне энергіі кадра (Min_E) па наступнай формуле:
Min_E =
дзе SilenceCount – бягучая колькасць кадраў, адзначаных як цішыня.
Крок 3.8. Абнавіць значэнне Thresh_E згодна з формулай Thresh_E = Energy_PrimThresh*log(Min_E).
Крок 4. Ігнараваць паслядоўнасць кадраў цішыні, якая цягнецца менш, чым MIN_PAUSE_DURATION. Ігнараваць паслядоўнасць кадраў маўлення, якая цягнецца менш, чым MIN_VOICE_DURATION.
Крок 5.1. Калі карыстальнік запрасіў вызначэне паўз, інвертаваць паслядоўнасці маўлення, якое гучыць, і паўз (тэхнічна – замяніць true на false і наадварот).
Крок 5.2. Сфарміраваць карыстальніцкую выдачу згодна са значэннем Format.
Крок 6. Прадставіць карыстальніку вынікі апрацоўкі ў фармаце субтытраў SRT.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Інтэрфейс карыстальніка мае дзве вобласці: вобласць уводу дадзеных і вобласць выдачы вынікаў. Знешні выгляд інтэрфейсу прадстаўлены на малюнку 1.
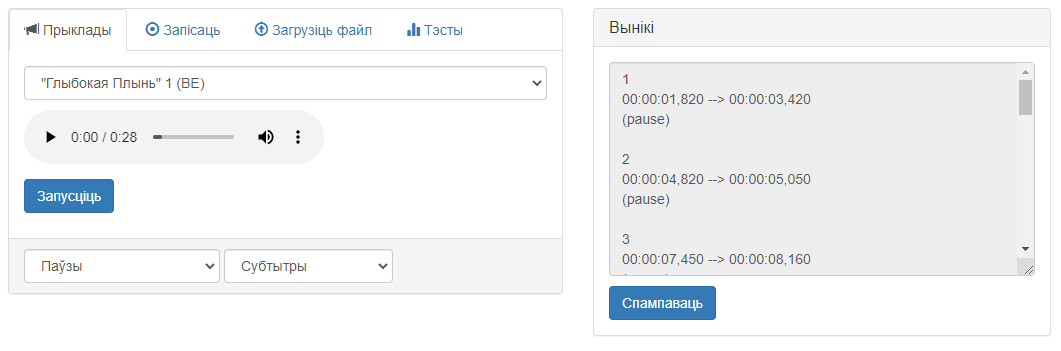
Малюнак 1 – Графічны інтэрфейс сэрвіса «Распазнаванне галасавой актыўнасці»: вобласць уводу дадзеных (злева) і вобласць выдачы вынікаў (справа)
Вобласць уводу дадзеных, у сваю чаргу, раздзелена на 4 іншыя вобласці: «Прыклады», «Запісаць», «Загрузіць файл», «Тэсты».
Вобласць «Прыклады»
Знешні выгляд вобласці «Прыклады» прадстаўлены на малюнку 2.
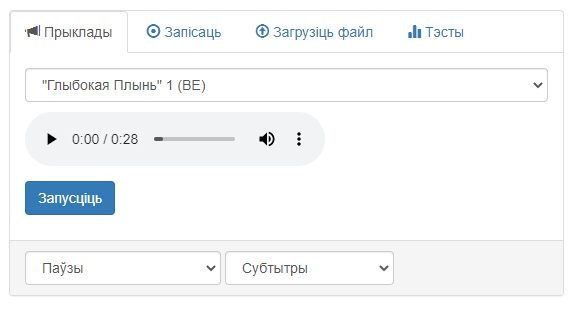
Малюнак 2 – Графічны інтэрфейс вобласці «Прыклады»
Інтэрфейс вобласці змяшчае наступныя элементы:
- Выпадальнае меню для выбару прыкладу (кожны прыклад даступны для спампоўвання);
- Аўдыяплэер для прайгравання выбранага файла;
- Кнопка «Запусціць», якая ініцыялізуе апрацоўку;
- Выпадальнае меню для выбару тыпу фрагментаў у выніковай выдачы (мае пункты «Паўзы» і «Галасавая актыўнасць»);
- Выпадальнае меню для выбару фармату выніковай выдачы (мае пункты «Субтытры» і «Меткі для Audacity»).
Вобласць «Запісаць»
Знешні выгляд вобласці «Запісаць» прадстаўлены на малюнку 3.
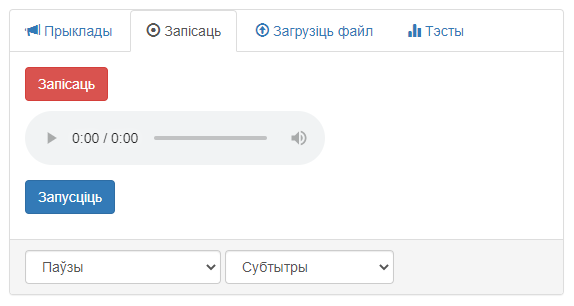
Малюнак 3 – Графічны інтэрфейс вобласці «Запісаць»
Інтэрфейс вобласці змяшчае наступныя элементы:
- Кнопка «Запісаць», якая запускае запіс аўдыяфайла з мікрафона камп’ютара (пасля націскання ператвараецца ў кнопку «Спыніць»);
- Плэер для прайгравання запісанага аўдыя;
- Кнопка «Запусціць», якая ініцыялізуе апрацоўку;
- Выпадальнае меню для выбару тыпу фрагментаў у выніковай выдачы (мае пункты «Паўзы» і «Галасавая актыўнасць»);
- Выпадальнае меню для выбару фармату выніковай выдачы (мае пункты «Субтытры» і «Меткі для Audacity»).
Вобласць «Загрузіць файл»
Знешні выгляд вобласці «Загрузіць файл» прадстаўлены на малюнку 4.
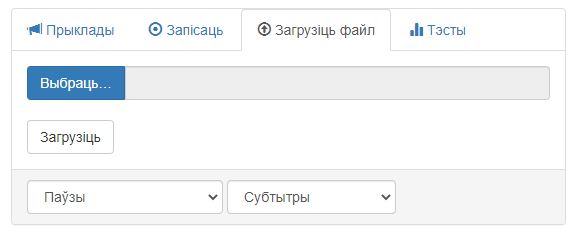
Малюнак 4 – Графічны інтэрфейс вобласці «Загрузіць файл»
Інтэрфейс вобласці змяшчае наступныя элементы:
- Кнопка «Выбраць…», якая ініцыялізуе адкрыццё акна для выбару файла на камп’ютары карыстальніка;
- Радок стану, які адлюстроўвае дадзеныя, якія датычацца загрузкі файла;
- Кнопка «Загрузіць» для загрузкі файла з камп’ютара і ініцыялізацыі апрацоўкі;
- Выпадальнае меню для выбару тыпу фрагментаў у выніковай выдачы (мае пункты «Паўзы» і «Галасавая актыўнасць»);
- Выпадальнае меню для выбару фармату выніковай выдачы (мае пункты «Субтытры» і «Меткі для Audacity»).
Вобласць «Тэсты»
Вобласць «Тэсты» прызначана для нагляднага прадстаўлення карыстальніку дадзеных пра якасць працы алгарытму. Знешні выгляд вобласці прадстаўлены на малюнку 5.

Малюнак 5 – Графічны інтэрфейс вобласці «Тэсты»
Інтэрфейс вобласці змяшчае лінейную дыяграму, якая адлюстроўвае значэнні F-мер для ілюстрацыі якасці аналізу:
- сінтэзаванага маўлення;
- студыйнага запісу;
- студыйнага запісу з белым шумам;
- фрагмента фільма.
(значэнні пералічаныя ў парадку іх адлюстравання зверху ўніз)
Каб атрымаць максімальна дакладныя дадзеныя, неабходна навесці курсор мышы на патрэбную лінію дыяграмы.
Вобласць выдачы вынікаў
Знешні выгляд вобласці выдачы вынікаў прадстаўлены на малюнку 6.
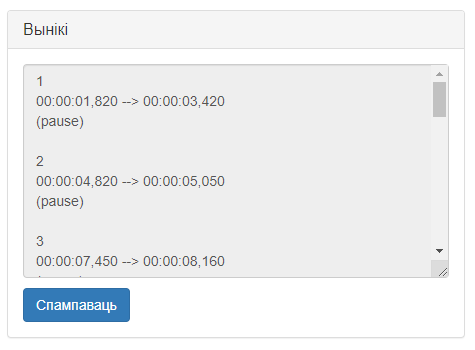
Малюнак 6 – Графічны інтэрфейс вобласці выдачы вынікаў
Інтэрфейс вобласці змяшчае наступныя элементы:
- Поле выдачы вынікаў, якое змяшчае вынікі папярэдняй апрацоўкі;
- Кнопка «Спампаваць», якая з’яўляецца пасля выканання хаця б адной апрацоўкі. Ініцыялізуе загрузку SRT-файла на камп’ютар карыстальніка.
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Аналіз прыкладаў.
- Перайсці на ўкладку «Прыклады».
- Выбраць патрэбны аўдыяфайл (прыклад) з дапамогай спецыяльнага меню.
- Пры неабходнасці – праслухаць аўдыяфайл з дапамогай плэера і/або спампаваць аўдыязапіс.
- Выбраць тып фрагментаў, дадзеныя пра якія будуць прадстаўленыя ў выніках апрацоўкі («Паўзы» або «Галасавая актыўнасць»).
- Выбраць фармат прадстаўлення вынікаў апрацоўкі («Субтытры» або «Меткі для Audacity»).
- Націснуць кнопку «Запусціць».
- Атрымаць вынікі апрацоўкі ў полі выдачы вынікаў.
- Пры неабходнасці – націснуць кнопку «Спампаваць» для спампоўвання SRT-файла з вынікамі апрацоўкі.
Сцэнар 2. Аналіз аўдыязапісу, створанага з дапамогай мікрафона карыстальніка.
- Перайсці на ўкладку «Запісаць».
- Націснуць кнопку «Запісаць» для ініцыялізацыі запісу, здзейсніць запіс, націснуць кнопку «Спыніць» для спынення запісу.
- Пры неабходнасці – праслухаць запісаны файл з дапамогай плэера.
- Выбраць тып фрагментаў, дадзеныя пра якія будуць прадстаўленыя ў выніках апрацоўкі («Паўзы» або «Галасавая актыўнасць»).
- Выбраць фармат прадстаўлення вынікаў апрацоўкі («Субтытры» або «Меткі для Audacity»).
- Націснуць кнопку «Запусціць».
- Атрымаць вынікі апрацоўкі ў полі выдачы вынікаў.
- Пры неабходнасці – націснуць кнопку «Спампаваць» для спампоўвання SRT-файла з вынікамі апрацоўкі.
Сцэнар 3. Аналіз карыстальніцкага аўдыяфайла.
- Перайсці на ўкладку «Загрузіць файл».
- Націснуць кнопку «Выбраць».
- У дыялогавым акне, якое адкрылася, выбраць аўдыяфайл у фармаце WAV на камп’ютары. Інфармацыя пра файл будзе прадстаўлена ў радку стану.
- Выбраць тып фрагментаў, дадзеныя пра якія будуць прадстаўленыя ў выніках апрацоўкі («Паўзы» або «Галасавая актыўнасць»).
- Выбраць фармат прадстаўлення вынікаў апрацоўкі («Субтытры» або «Меткі для Audacity»).
- Націснуць кнопку «Загрузіць» для загрузкі аўдыяфайла і ініцыялізацыі апрацоўкі.
- Атрымаць вынікі апрацоўкі ў полі выдачы вынікаў.
- Пры неабходнасці – націснуць кнопку «Спампаваць» для спампоўвання SRT-файла з вынікамі апрацоўкі.
Магчымы вынік працы сэрвіса згодна са сцэнарамі 1–3 прадстаўлены на малюнку 7.
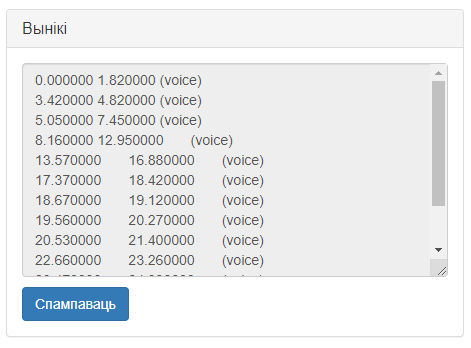
Малюнак 7 – Вынік працы сэрвіса «Вызначэнне галасавой актыўнасці»
Сцэнар 4. Атрыманне інфармацыі пра якасць працы сэрвіса.
- Перайсці на ўкладку «Тэсты».
- Ва ўкладцы, якая адкрылася, навесці курсор мышы на неабходную лінію дыяграмы і праглядзець вынікі тэставання.
Доступ да сэрвіса праз API
Для дадзенага сэрвіса доступ праз API не прадугледжаны.
Спасылкі на крыніцы
Старонка сэрвіса – https://corpus.by/VoiceActivityDetector/?lang=ru
Moattar, M.H. A simple but efficient real-time voice activity detection algorithm / M.H. Moattar, M.M. Homayounpour [Electronic resource] // 17th European Signal Processing Conference (EUSIPCO 2009), Glasgow, Scotland, August 24-28, 2009. – Mode of access: https://www.eurasip.org/Proceedings/Eusipco/Eusipco2009/contents/papers/1569192958.pdf. – Date of access: 01.06.2020.
Бібліятэка NumPy – https://numpy.org/.
Бібліятэка SciPy – https://www.scipy.org/.