The service «Specialized phonetic dictionary» is designed to display the transcription of word lists of specialized topics. At the moment, the dictionary contains words for the Russian language, these words were used in the everyday and conversational thematic domain. On the service page there is a list of letters in alphabetical order, from which words with a prescribed phonetic analysis begin. The user can select any letter and words starting with the selected letter and see the transcriptions of its paradigm, and a detailed phonetic analysis of each word form.
A word form can have one or more transcriptions, not all of which are the official norm, but are used in conversational speech and should be taken into account, for example, when studying the peculiarities of speech or when creating a speech recognition system.
Information about the word form is enclosed in the following order: word form with pressing {part of speech, gender, case, number / n of transcription variants}.
Basic terms and concepts
Paradigm — the totality of all word forms of the word. For example, дрэва, дрэва, дрэву, дрэва, дрэвам, дрэве, дрэвы, дрэваў, дрэвам, дрэвы, дрэвамі, дрэвах.
The wordform or the form of a word — detects various grammatical meanings of a word while preserving its lexical meaning.
Transcription in linguistics is a written transfer by one or another set of written characters (phonetic alphabet) of elements of sound speech (phonemes, allophones, sounds). In linguistic theory and practice, transcription has various uses.
Phonetics is a section of linguistics that studies the sounds of speech and the sound structure of a language, in particular, syllables, sound combinations, patterns of connection of sounds in a speech chain.
Phonetic analysis of a word — a detailed analysis of a word from the point of view of its correct pronunciation: determining the number of letters, sounds, word stress, highlighting vowels and consonants, their classification.
Service features
The dictionary base of the service currently contains 13713 word forms, each of which has its own phonetic analysis.
Practical value
Phonetic analysis of words and word forms will help the user in the work and study of the language presented, namely the phonetic component of the word and its pronunciation options. Also, this base can be used to help in writing reports on topics related to language, speech and its origin.
When finalizing the service and updating the archive with new word forms, it will be able to provide the user with the ability to search for the desired word and parse it.
Interface Description
The graphical interface of the service includes the following sections, presented in Figure 1-3.

Figure 1. The main page of the service «Specialized Phonetic Dictionary»
A — language selection buttons.
B — link to examples of words.
С — a table of letters in alphabetical order, each of which leads to a list of words starting with the specified letter.
D — indicates the number of word forms in the dictionary.
E — a list of words for viewing paradigms and phonetic analysis (Figure 2).

Figure 2. A list of words for viewing paradigms and phonetic analysis
Each word is represented as shown in Figure 3.
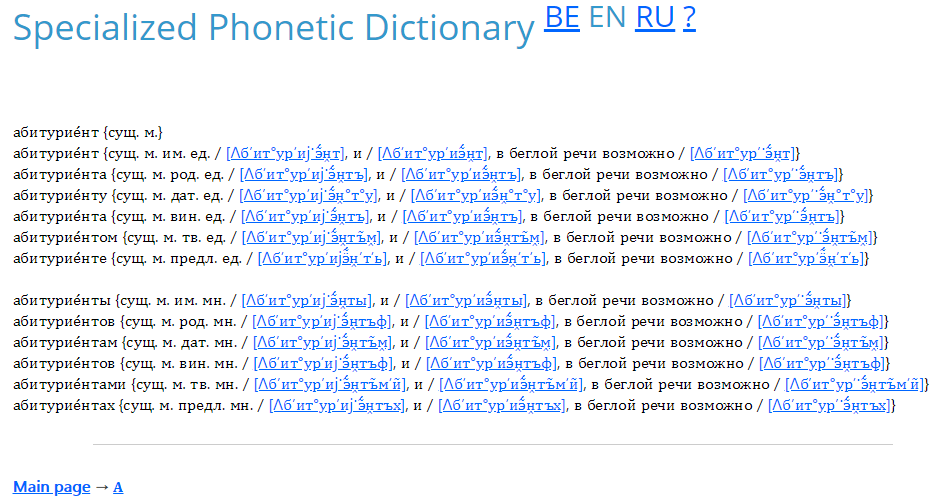
Figure 3. Parsing words in the service «Specialized phonetic dictionary»
User script for working with the service
- See examples of vocabulary words.
- Press the letter with which the word begins, the analysis of which you want to learn.
- Select a word from the list of words and view its analysis (in particular, the paradigm and transcriptions).
- Click on the transcription to see the phonetic analysis of the word.
Access to the service via the API
To access the service «Specialized Phonetic Dictionary» via the API, you should send an AJAX-request (type: POST) to the address https://corpus.by/SpecializedPhoneticDictionary/api.php. With an input array data the following parameters are passed:
- localization — localization language; takes the values “en”, “be”, “ru”.
- op — operation name; takes the values:
- getFirstLetters — selecting this operation allows you to get an html-page fragment, which is a menu for selecting available letters (subsections of the dictionary).
- getLexemes — selecting this operation allows you to get an html-page fragment, which is a menu for selecting a lexeme on the selected letter.
- getParadigm — selecting this operation allows you to get an html-page fragment, which is a menu for selecting a wordform on the selected lexeme.
- getPhoneticParsing — selecting this operation allows you to get an html-page fragment, which is a phonemic analysis of the selected wordform.
- ex — marker for wordlist showing on the main page of the service; only required if op = “getFirstLetters”; takes the values “show”, “hide”.
- letter — subsection of the dictionary, which includes words that begin with a certain letter; for instance, “Я”.
- lexeme — lexeme, which wordforms will be given along with transcriptions; for instance, “янва́рский”.
- wordform — wordform; for instance, “янва́рскими”.
- transcription — transcription; for instance, “[ṷ,и̃э,н,в,а́,р̭,с,к’,и̃,м’,и̃]”.
Example of AJAX-request:
$.ajax({
type: “GET”,
url: “https://corpus.by/SpecializedPhoneticDictionary/api.php”,
data: {
“localization”: “en”,
“op”: “getPhoneticParsing”,
“letter”: “Я”,
“lexeme”: “янва́рский”,
“wordform”: “янва́рскими”,
“transcription”: “[ṷ,и̃э,н,в,а́,р̭,с,к’,и̃,м’,и̃]”
},
success: function(msg){ },
error: function() { }
});
The server returns a JSON-array with the following parameters:
- result — resulting html-page fragment.
For example, the following reply will be formed on the above listed AJAX-request:
[
{
“result”: “янва́рскими [ṷи̃<sup>э</sup>нва́р̭ск’и̃м’и̃]<br><br>
<table><tbody><tr><td>[ṷ] – согласный, среднеязычный средненёбный, аппроксимант, сонорный, палатальный<br>
</td></tr><tr><td>[и̃<sup>э</sup>] – гласный, безударный, переднего ряда, верхне-среднего подъёма, нелабиализованный, назализованный<br>
</td></tr><tr><td>[н] – согласный, переднеязычный дорсальный зубной, смычно-проходный носовой, сонорный, твердый<br>
</td></tr><tr><td>[в] – согласный, губно-зубной, щелевой, шумный звонкий, твердый<br>
</td></tr><tr><td>[а́] – гласный, ударный, среднего ряда, нижнего подъёма, нелабиализованный<br>
</td></tr><tr><td>[р̭] – согласный, переднеязычный, какуминальный, передненёбный, дрожащий, десонантизованный, твердый<br>
</td></tr><tr><td>[с] – согласный, переднеязычный, дорсальный, зубной, щелевой, шумный, глухой, твердый<br>
</td></tr><tr><td>[к’] – согласный, заднеязычный средненёбный, взрывной, шумный глухой, мягкий<br>
</td></tr><tr><td>[и̃] – гласный, безударный, переднего ряда, верхнего подъёма, нелабиализованный, назализованный<br>
</td></tr><tr><td>[м’] – согласный, губно-губной, смычно-проходный носовой, сонорный, мягкий<br>
</td></tr><tr><td>[и̃] – гласный, безударный, переднего ряда, верхнего подъёма, нелабиализованный, назализованный<br>
</td></tr></tbody></table><div class=”divider”></div><a href=”https://corpus.by/SpecializedPhoneticDictionaryViaApi/index.php?lang=en”>Main page</a> → <a href=”https://corpus.by/SpecializedPhoneticDictionaryViaApi/index.php?lang=en&op=getLexemes&letter=%D0%AF”>Я</a> → <a href=”https://corpus.by/SpecializedPhoneticDictionaryViaApi/index.php?lang=en&op=getParadigm&letter=%D0%AF&lexeme=%D1%8F%D0%BD%D0%B2%D0%B0%CC%81%D1%80%D1%81%D0%BA%D0%B8%D0%B9″>янва́рский</a>”
}
]
References to sources
Service page: https://corpus.by/SpecializedPhoneticDictionary/?lang=en