The service «Speech Duration Predictor» allows the user to know the approximate time of the online speech. An electronic text is delivered to the service entrance in Belarusian, English or Russian, the text can be entered manually or copied. At the output, the user receives the result in the form of an approximate speech duration in the HH:XX:SS format, as well as information on the number of words and symbols used in the text.
Basic terms and concepts
Allophone — realization of a phoneme, a variant due to the specific phonetic environment.
Text-to-speech synthesizer (CMT) [1] is a system capable of generating speech in text. It contains two blocks: a block of linguistic processing of text to the phoneme view with labels pressed, intonations (prosody) and rhythm, as well as a speech signal processing unit that converts previously artymany fans into a sound signal of speech [2].
Features of the service
Speech duration is calculated using a speech synthesizer in the text: the text entered is divided into allophones (the smallest sound units), then the lengths of sound of all allophones of the input text are summarized.
Practical value
Service will be useful for users who need to make a report. Usually at such events, there is a regulation, in which the speaker has to answer. The service will help the user to see in advance how much time it will take to pronounce the entered amount of text so as not to shift the time limit for the speech. The service will also help in creating acoustic resources for the development and improvement of speech synthesizer in the text, it will help to predict the duration of the audio recording of the read text for the acoustic base.
User Interface Description
The graphical interface of the service includes the following parts, presented in Figure 1.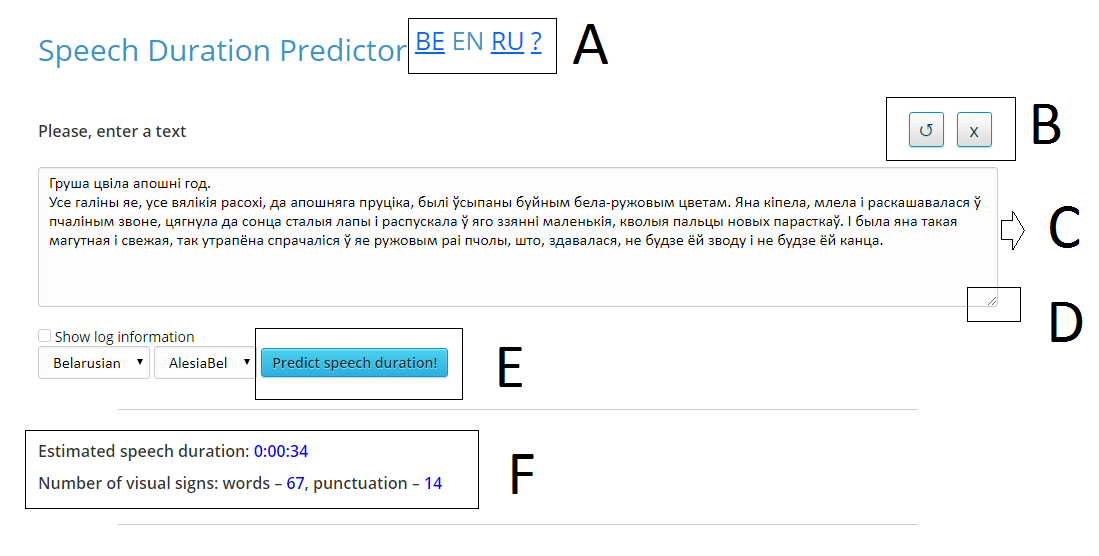
Figure 1. User interface of the service «Speech Duration Predictor»
Area A includes the following buttons:
- «EN», «RU» and «RU» — localization selection buttons;
- «?» — open the service help (this page).
Area B includes the following buttons:
- The arrow button is used to return the original example to the input field;
- A button with a cross clears the input field.
Area C — text input field.
Area D — a corner with which you can change the size of the input field.
Area E — the button «Predict speech duration», with which you can get the result.
Area F — information that is the result of the service.
Customer scripts for working with the service
- Enter the text in Belarusian, English or Russian in the input field.
- Click on «Predict speech duration!» to get the result (Figure 1).
The result is the duration of the synthesized input text in the format HH:XX:SS, as well as the number of visual signs: words and punctuation.
Access to the service via the API
To access the service «SpeechDurationPredictor» via the API, you should send an AJAX-request (type: POST) to the address https://corpus.by/SpeechDurationPredictor/api.php. With an input array data the following parameters are passed:
- inputText — arbitrary input text in Belarusian, Russian or English.
- language — language of the input text. Belarusian (параметр be), Russian (параметр ru) and English (параметр en) are available.
- voice — speech synthesizer voice, based on which prediction takes place:
- for Belarusian and English following voices are available: AlesiaBel, AlesiaBel (dictation mode), BorisBel, BorisBel (dictation mode), BorisBelHigh;
- for Russian following voices are available: AlesiaRus, AlesiaRus (dictation mode), BorisRus, BorisRus (dictation mode), BorisRusHigh.
- log — marker for additional information.
Example of AJAX-request:
$.ajax({
type: “POST”,
url: “https://corpus.by/SpeechDurationPredictor/api.php”,
data:{
“inputText”: “Груша цвіла апошні год.”,
“language”: “be”,
“voice”: “AlesiaBel”,
“log”: 1
},
success: function(msg){ },
error: function() { }
});
The server returns a JSON-array with the following parameters:
- inputText — input text.
- result — estimated speech duration.
- wordsCnt — number of words in the input text.
- delimitersCnt — amount of punctuation.
- unknownPhones — allophones list, not in the database.
In case, if there was a demand for additional information, the resulting array will have two more elements:
- allophonicText — input text in allophonic form.
- allophonicDuration — allophones list with their duration in milliseconds.
For example, the following reply will be formed on the above listed AJAX-request:
[
{
“inputText”: “Груша цвіла апошні год.”,
“result”: “0:00:03”,
“allophonicText”: “GH004,R022,U022,SH002,A323,/,C’002,V’002,I241,L002,A012,/,A221,P001,O012,SH002,N’004,I242,/,GH001,O032,T000,/,#P4,”,
“allophonicDuration”: “GH004 – 66
R022 – 54
U022 – 110
SH002 – 110
A323 – 43
C’002 – 53
V’002 – 57
I241 – 64
L002 – 74
A012 – 133
A221 – 62
P001 – 126
O012 – 123
SH002 – 110
N’004 – 61
I242 – 62
GH001 – 103
O032 – 123
T000 – 109
#P4 – 1176”,
“allophonicDuration”: “”,
“wordsCnt”: 4,
“delimitersCnt”: 1
“unknownPhones”: “”
}
]
Links to sources
Service page — https://corpus.by/SpeechDurationPredictor/?lang=en
Text-to-Speech Synthesizer — https://corpus.by/TextToSpeechSynthesizer/?lang=en
External links
- Сінтэзатар маўлення па тэксце // Платформа для апрацоўкі тэкставай і гукавой інфармацыі розных тэматычных даменаў [Электронны рэсурс]. — 2017. Рэжым доступу : http://corpus.by/TextToSpeechSynthesizer/?lang=be. — Дата доступу : 30.03.2017.
- Алгарытмы лінгвістычнай апрацоўкі тэкстаў для сінтэзу маўлення на беларускай і рускай мовах : дысертацыя на атрыманне навуковай ступені кандыдата тэхнічных навук : спецыяльнасць 05.13.01 Сістэмны аналіз, кіраванне і апрацоўка інфармацыі / Гецэвіч Юрый Станіслававіч ; навуковы кіраўнік Лабанаў Б. М. ; Аб’яднаны інстытут праблем інфарматыкі Нацыянальнай акадэміі навук Беларусі. — Мінск, 2012. — 184, [6] л. : іл., табл., схемы. — Ч. тэксту рус. — Бібліягр.: л. 153-164.