Service “Transcription Generator” is designed for graphic recording of the sound of words (Figure 1). The functionality of the service is not limited to processing of individual words, but also allows you to process large amounts of text. At the entrance to the service page, the user can see an example of the input text on which transcription can be obtained. If you press the “Clear! / Ачысціць!” button, the window for entering text will be cleared for you to enter your text.
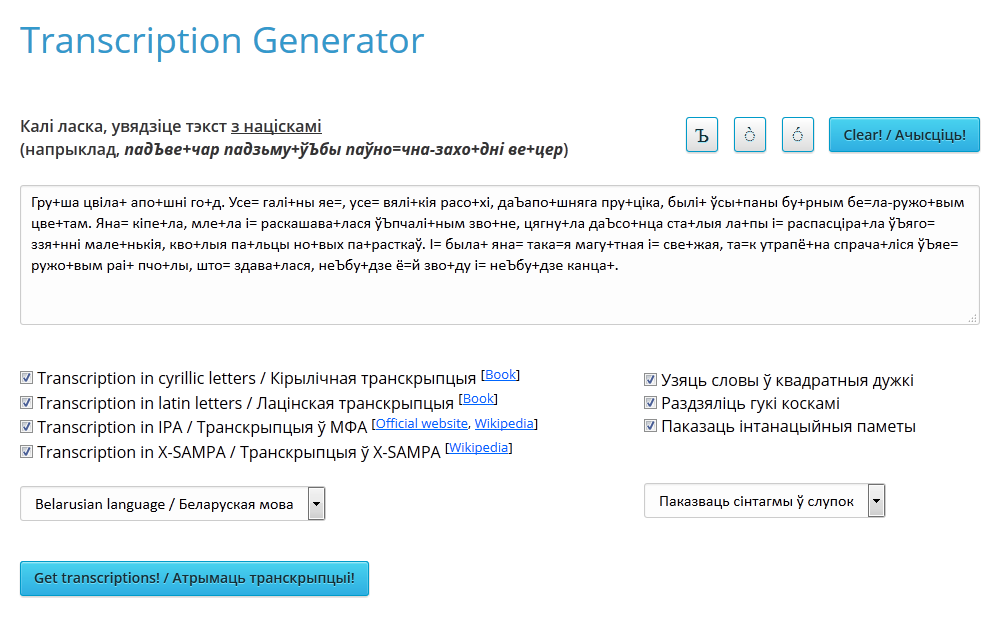 Figure 1 – External service interface “Transcription Generator”
Figure 1 – External service interface “Transcription Generator”
Service allows users to transcribe a text into 4 types of transcription: Cyrillic, simplified Latin, IPA and X-SAMPA. The information about all types can be found by using the instructions on page service links to the official website of the transcription, page on Wikipedia, or the book that was used while developing a specific type of transcription. Another functional feature of the service is the ability to customize the resulting data. Having noted relevant paragraphs in the settings, the user can get the final transcription in square brackets or without them, in the transcription of each word the phonemes can be displayed together or separated by commas. If you activate the option “Паказаць інтанацыйныя паметы” ‘Show intonation marks’, the final text will be broken into fragments of intonation – Syntagmas – specific tags (for example, a vertical bar ‘|’ in the case of a comma and a double vertical bar ‘||’ at the end of a sentence or paragraph). Also, for better perception of the resulting data the user can choose in a drop-down menu “Паказваць сінтагмы ў слупок” ‘In a column Syntagma Show’ or “Паказваць сінтагмы ў радок” ‘Show Syntagma in a Row’. After entering the required text and service settings for transcription have to click on “Get transcriptions! / Атрымаць транскрыпцыі!”. Examples of the service with different settings are shown in Figures 2 and 3.
 Figure 2 – The result of text transcription that is shown on the service by default. Syntagmas are given in the column, the words are in square brackets, phonemes are separated by commas, intonation is also marked.
Figure 2 – The result of text transcription that is shown on the service by default. Syntagmas are given in the column, the words are in square brackets, phonemes are separated by commas, intonation is also marked.
 Figure 3 – The result of text transcription that is shown on the service by default. Syntagmas are given in line, the words are not marked in square brackets, phonemes are not separated by commas, intonation is marked.
Figure 3 – The result of text transcription that is shown on the service by default. Syntagmas are given in line, the words are not marked in square brackets, phonemes are not separated by commas, intonation is marked.
Access to the service via the API
To access the service «Transcription Generator» via the API, you should send an AJAX-request (type: POST) to the address https://corpus.by/TranscriptionGenerator/api.php. With an input array data the following parameters are passed:
- text — arbitrary input text in Belarusian.
- inputType — type of the input text. Normal (parameter normal) and allophonic (parameter allophonic) text formats are available.
- language — language of the input text. Belarusian (parameter be), Russian (parameter ru) and English (parameter en) are available.
- tts — marker for transcription in text-to-speech synthesizer format.
- cyr — marker for transcription in cyrillic format.
- lat — marker for transcription in a simplified format of the international phonetic alphabet.
- ipa — marker for transcription in IPA format (International Phonetic Alphabet).
- xsampa — marker for transcription in X-SAMPA format.
- cmu — marker for transcription in CMU format.
- syntagmaDivider — divider to allocate syntagmas in resulting transcriptions. Newlines (parameter newline) and spaces (parameter space) are available.
- bracketsNecessity — marker for taking transcriptions in brackets.
- commasNecessity — marker for dividing phonemes by commas.
- intonationNecessity — marker for intonation notation usage.
Example of AJAX-request:
$.ajax({
type: “POST”,
url: “https://corpus.by/TranscriptionGenerator/api.php”,
data:{
“text”: “Арфаэпія.”,
“inputType”: “normal”,
“language”: “be”,
“tts“: 1,
“cyr”: 1,
“lat”: 1,
“ipa”: 1,
“xsampa”: 1,
“cmu”: 1,
“syntagmaDivider”: “space”,
“bracketsNecessity”: 1,
“commasNecessity”: 1,
“intonationNecessity”: 1
},
success: function(msg){ },
error: function() { }
});
The server returns a JSON-array with the following parameters:
- text — input text.
- tts — resulting transcription in text-to-speech synthesizer format.
- cyr — resulting transcription in cyrillic format.
- lat — resulting transcription in a simplified format of the international phonetic alphabet.
- ipa — resulting transcription in IPA format (International Phonetic Alphabet).
- xsampa — resulting transcription in X-SAMPA format.
- cmu — resulting transcription in CMU format.
For example, the following reply will be formed on the above listed AJAX-request:
[
{
“text”: “Арфаэпія.”,
“tts“: “>,A302,R003,>,F002,A212,>,E023,>,P’002,I343,>,J’012,A340,/,>,#P4,”,
“cyr”: “[а,р,ф,а,э́,п’,і,й,а] ||”,
“lat”: “[a,r,f,a,é,p’,i,j,a] ||”,
“ipa”: “[a,r,f,a,ˈ,ɛ,pʲ,i,j,a] ||”,
“xsampa”: “[a,r,f,a,”,E,p’,i,j,a] ||”,
“cmu”: “[A3,R0,F0,A2,E0,PJ0,I3,JJ0,A3]||”
}
]
Service page: https://corpus.by/TranscriptionGenerator/?lang=en
Cross references
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Lysy, S. Addition of Phonetic Transcriptions to Belarusian Module of NooJ / S. Lysy, A. Hiuntar, Yu. Hetsevich // International Scientific Conference on the Automatic Processing of Natural-Language Electronic Texts “NooJ’2015” : Abstracts (11–13 June, 2015, Minsk, Belarus) / ed. B.M. Lobanov, Yu.S.Hetsevich. — Minsk : UIIP NASB, 2015. — P. 36-37.
- Гецэвіч, Ю.С. Праектаванне інтэрнэт-сервісаў для працэсараў сінтэзатара маўлення па тэксце з магчымасцю прадстаўлення бясплатных электронных паслуг насельніцтву / Ю.С. Гецэвіч, С.І. Лысы // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2014) : доклады XIII Международной конференции (Минск, 20 ноября 2014 г.). – Минск : ОИПИ НАН Беларуси, 2014. — C. 265-269.
- Русак, В.П. Першы даведнік па культуры беларускага вымаўлення / В.П. Русак, В.А. Мандзік, Ю.С. Гецэвіч, С.І. Лысы // Весці Нацыянальнай акадэміі навук Беларусі. Серыя гуманітарных навук. – 2019. – Т. 64, № 1. – С. 69-80.
- Зяноўка, Я.С. Распрацоўка лінгвістычных рэсурсаў для аўтаматычнай транскрыпцыі беларускамоўных тэкстаў на англійскай мове / Я.С. Зяноўка // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы I Респ. науч.-практ. конф. с междунар. участием, Минск, 23–24 февр. 2017 г. / БГУ, факультет социокультурных коммуникаций ; редкол. : О.Г. Прохоренко (отв. ред.) [и др.]. — Минск : Изд. центр БГУ, 2017. — C. 89-92.
- Лысы С.І. Генерацыя нацыянальнай транскрыпцыі тэкстаў на беларускай мове / С.І. Лысы, Ю.С. Гецэвіч // Інфарматыка. — 2017. — №54. — C. 84-92.