Сэрвіс “Генератар транскрыпцый” распрацаваны для графічнага запісу гучання слоў (малюнак 1). Функцыянальнасць сэрвісу не абмяжоўваецца магчымасцю апрацоўкі паасобных слоў, але таксама дазваляе апрацоўваць вялікія аб’ёмы тэкстаў. Пры ўваходзе на старонку сэрвісу карыстальнік можа паглядзець прыклад уваходнага тэксту, па якім можна атрымаць транскрыпцыю. Калі націснуць кнопку “Clear! / Ачысціць!”, акно для ўваходнага тэксту ачысціцца і можна будзе ўвесці свой тэкст.
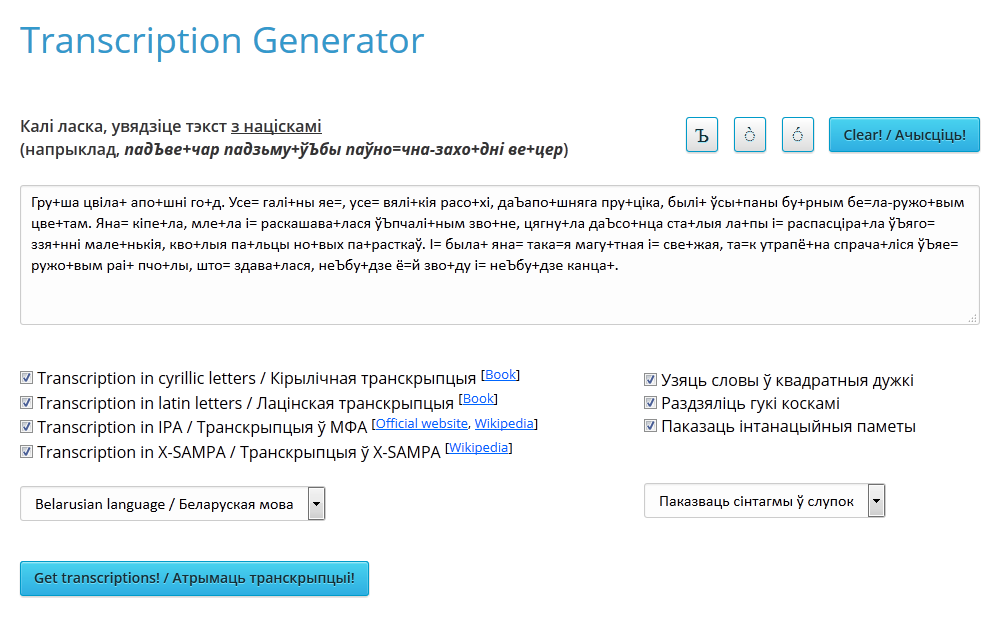 Малюнак 1. Знешні інтэрфейс сэрвісу “Генератар транскрыпцый”
Малюнак 1. Знешні інтэрфейс сэрвісу “Генератар транскрыпцый”
Сэрвіс дае магчымасць карыстальніку транскрыбіраваць тэкст у 4 тыпы транскрыпцый: кірылічную, спрошчаную лацінскую, IPA і X-SAMPA. Што з сябе ўяўляе кожная з прыведзеных транскрыпцый можна даведацца, скарыстаўшыся прыведзенымі на старонцы сэрвісу спасылкамі на афіцыйны сайт транскрыпцыі, старонку ў Wikipedia альбо кнігу, паводле якой распрацоўваўся пэўны тып транскрыпцый. Яшчэ адной функцыянальнай асаблівасцю сэрвісу з’яўляецца магчымасць наладкі выніковых даных. Адзначыўшы адпаведныя пункты ў наладках, карыстальнік можа атрымаць выніковыя транскрыпцыі ў квадратных дужках альбо без іх, у транскрыпцыі кожнага слова фанемы могуць быць выведзены разам альбо праз коскі. Калі актываваць пункт “Паказаць інтанацыйныя паметы”, выніковы тэкст будзе разбіты на інтанацыйныя фрагменты – сінтагмы – пэўнымі пазнакамі (напрыклад, вертыкальнай рысай ‘|’ у выпадку коскі і падвоеннай вертыкальнай рысай ‘||’ у канцы сказа ці абзаца). Таксама для больш зручнага ўспрыняцця выніковых даных ёсць выбар “Паказваць сінтагмы ў слупок” ці “Паказваць сінтагмы ў радок”. Пасля ўводу неабходнага тэксту і наладкі сэрвісу для атрымання транскрыпцыі патрэбна націснуць на кнопку “Get transcriptions! / Атрымаць транскрыпцыі!”. Прыклады працы сэрвісу з рознымі наладкамі прыведзены на малюнках 2 і 3.
 Малюнак 2. Вынік транскрыбіравання тэкста, які прыведзены на сэрвісе па змаўчанні. Сінтагмы прыведзены ў слупок, словы ўзяты ў квадратныя дужкі, фанемы раздзелены коскамі, прысутнічаюць інтанацыйныя паметы
Малюнак 2. Вынік транскрыбіравання тэкста, які прыведзены на сэрвісе па змаўчанні. Сінтагмы прыведзены ў слупок, словы ўзяты ў квадратныя дужкі, фанемы раздзелены коскамі, прысутнічаюць інтанацыйныя паметы
 Малюнак 3. Вынік транскрыбіравання тэкста, які прыведзены на сэрвісе па змаўчанні. Сінтагмы прыведзены ў радок, словы не выдзелены ў квадратныя дужкі, фанемы не раздзяляюцца коскамі, прысутнічаюць інтанацыйныя паметы
Малюнак 3. Вынік транскрыбіравання тэкста, які прыведзены на сэрвісе па змаўчанні. Сінтагмы прыведзены ў радок, словы не выдзелены ў квадратныя дужкі, фанемы не раздзяляюцца коскамі, прысутнічаюць інтанацыйныя паметы
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Генератар транскрыпцый» праз API, неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/TranscriptionGenerator/api.php. Праз масіў data перадаюцца наступныя параметры:
- text — адвольны тэкст на беларускай мове.
- inputType — тып уваходнага тэксту. Даступны наступныя тыпы: звычайны (параметр normal) і алафонны (параметр allophonic).
- language — мова ўваходнага тэксту. Даступны наступныя мовы: беларуская (параметр be), руская (параметр ru) і англійская (параметр en).
- tts — маркер для генерацыі транскрыпцыі ў фармаце сінтэзатара маўлення па тэксце.
- cyr — маркер для генерацыі транскрыпцыі ў кірылічным фармаце.
- lat — маркер для генерацыі транскрыпцыі ў фармаце спрошчанага Міжнароднага фанетычнага алфавіту.
- ipa — маркер для генерацыі транскрыпцыі ў фармаце IPA (International Phonetic Alphabet, Міжнародны фанетычны алфавіт).
- xsampa — маркер для генерацыі транскрыпцыі ў фармаце X-SAMPA.
- cmu — маркер для генерацыі транскрыпцыі ў фармаце CMU.
- syntagmaDivider — раздзяляльнік сінтагмаў у выніковых транскрыпцыях. Даступны наступныя раздзяляльнікі: перавод радка (параметр newline) і прабел (параметр space).
- bracketsNecessity — маркер неабходнасці браць транскрыпцыі ў квадратныя дужкі.
- commasNecessity — маркер неабходнасці раздзяляць фанемы коскамі.
- intonationNecessity — маркер неабходнасці выкарыстання інтанацыйных памет.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/TranscriptionGenerator/api.php”,
data:{
“text”: “Арфаэпія.”,
“inputType”: “normal”,
“language”: “be”,
“tts“: 1,
“cyr”: 1,
“lat”: 1,
“ipa”: 1,
“xsampa”: 1,
“cmu”: 1,
“syntagmaDivider”: “space”,
“bracketsNecessity”: 1,
“commasNecessity”: 1,
“intonationNecessity”: 1
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з наступнымі параметрамі:
- text — уваходны тэкст.
- tts — выніковая транскрыпцыя ў фармаце сінтэзатара маўлення па тэксце.
- cyr — выніковая транскрыпцыя ў кірылічным фармаце.
- lat — выніковая транскрыпцыя ў фармаце спрошчанага Міжнароднага фанетычнага алфавіту.
- ipa — выніковая транскрыпцыя ў фармаце IPA (International Phonetic Alphabet, Міжнародны фанетычны алфавіт).
- xsampa — выніковая транскрыпцыя ў фармаце X-SAMPA.
- cmu — выніковая транскрыпцыя ў фармаце CMU.
Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “Арфаэпія.”,
“tts“: “>,A302,R003,>,F002,A212,>,E023,>,P’002,I343,>,J’012,A340,/,>,#P4,”,
“cyr”: “[а,р,ф,а,э́,п’,і,й,а] ||”,
“lat”: “[a,r,f,a,é,p’,i,j,a] ||”,
“ipa”: “[a,r,f,a,ˈ,ɛ,pʲ,i,j,a] ||”,
“xsampa”: “[a,r,f,a,”,E,p’,i,j,a] ||”,
“cmu”: “[A3,R0,F0,A2,E0,PJ0,I3,JJ0,A3]||”
}
]
Старонка сэрвіса: https://corpus.by/TranscriptionGenerator/?lang=be
Перакрыжаваныя спасылкі
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Lysy, S. Addition of Phonetic Transcriptions to Belarusian Module of NooJ / S. Lysy, A. Hiuntar, Yu. Hetsevich // International Scientific Conference on the Automatic Processing of Natural-Language Electronic Texts “NooJ’2015” : Abstracts (11–13 June, 2015, Minsk, Belarus) / ed. B.M. Lobanov, Yu.S.Hetsevich. — Minsk : UIIP NASB, 2015. — P. 36-37.
- Гецэвіч, Ю.С. Праектаванне інтэрнэт-сервісаў для працэсараў сінтэзатара маўлення па тэксце з магчымасцю прадстаўлення бясплатных электронных паслуг насельніцтву / Ю.С. Гецэвіч, С.І. Лысы // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2014) : доклады XIII Международной конференции (Минск, 20 ноября 2014 г.). – Минск : ОИПИ НАН Беларуси, 2014. — C. 265-269.
- Русак, В.П. Першы даведнік па культуры беларускага вымаўлення / В.П. Русак, В.А. Мандзік, Ю.С. Гецэвіч, С.І. Лысы // Весці Нацыянальнай акадэміі навук Беларусі. Серыя гуманітарных навук. – 2019. – Т. 64, № 1. – С. 69-80.
- Зяноўка, Я.С. Распрацоўка лінгвістычных рэсурсаў для аўтаматычнай транскрыпцыі беларускамоўных тэкстаў на англійскай мове / Я.С. Зяноўка // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы I Респ. науч.-практ. конф. с междунар. участием, Минск, 23–24 февр. 2017 г. / БГУ, факультет социокультурных коммуникаций ; редкол. : О.Г. Прохоренко (отв. ред.) [и др.]. — Минск : Изд. центр БГУ, 2017. — C. 89-92.
- Лысы С.І. Генерацыя нацыянальнай транскрыпцыі тэкстаў на беларускай мове / С.І. Лысы, Ю.С. Гецэвіч // Інфарматыка. — 2017. — №54. — C. 84-92.