The “Web Page Content Saver” (figure 1) allows user to save the HTML code of any internet-page without any difficulties.
It is enough to input the link in the field “Please input an URL” and click the button “Get page”. After the processing two text documents (*txt) are formed: with HTML tags (figure 2) and without them (figure 3). To save the document with HTML tags one need to click the link “Download full html page”, and respectively to save the document without tags, one need to click “Download html page without tags”.
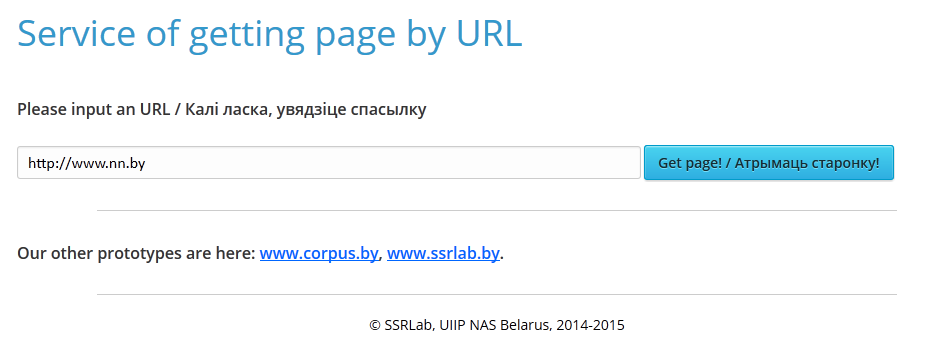 Figure 1 – The interface of the service of getting page by URL
Figure 1 – The interface of the service of getting page by URL
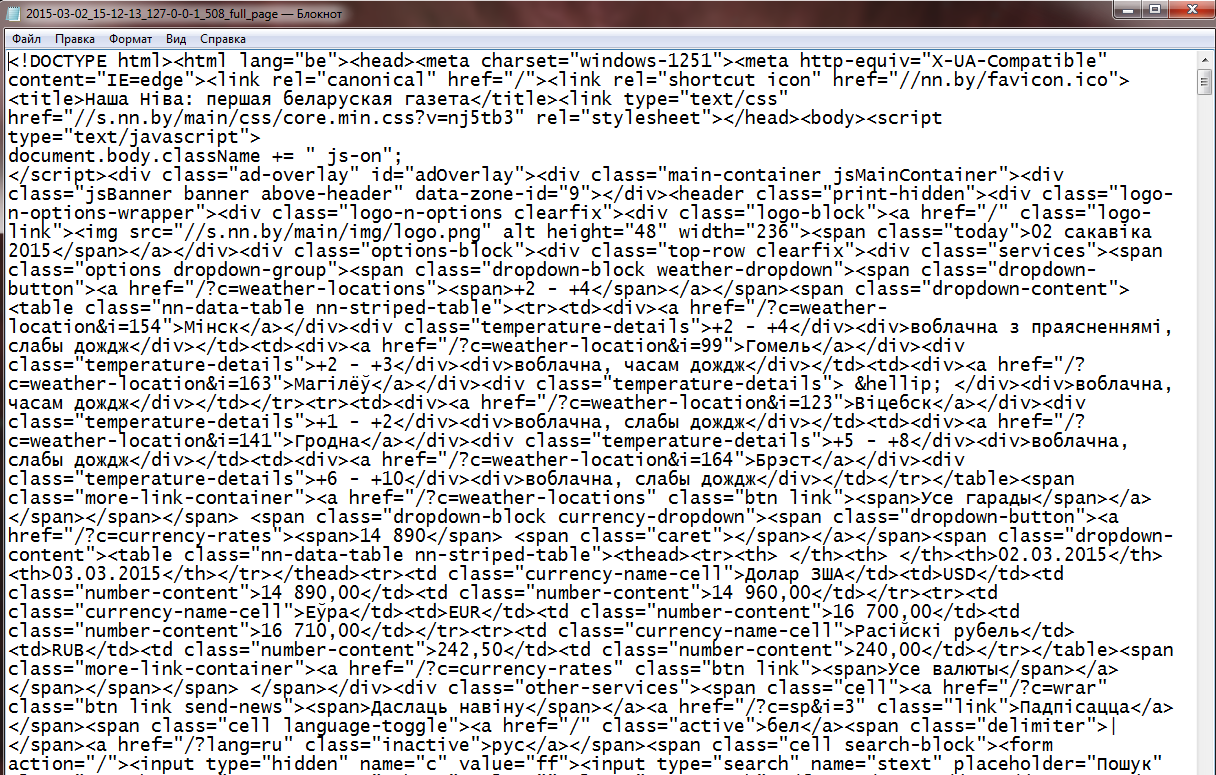 Figure 2 – Fragment of the document with HTML tags
Figure 2 – Fragment of the document with HTML tags
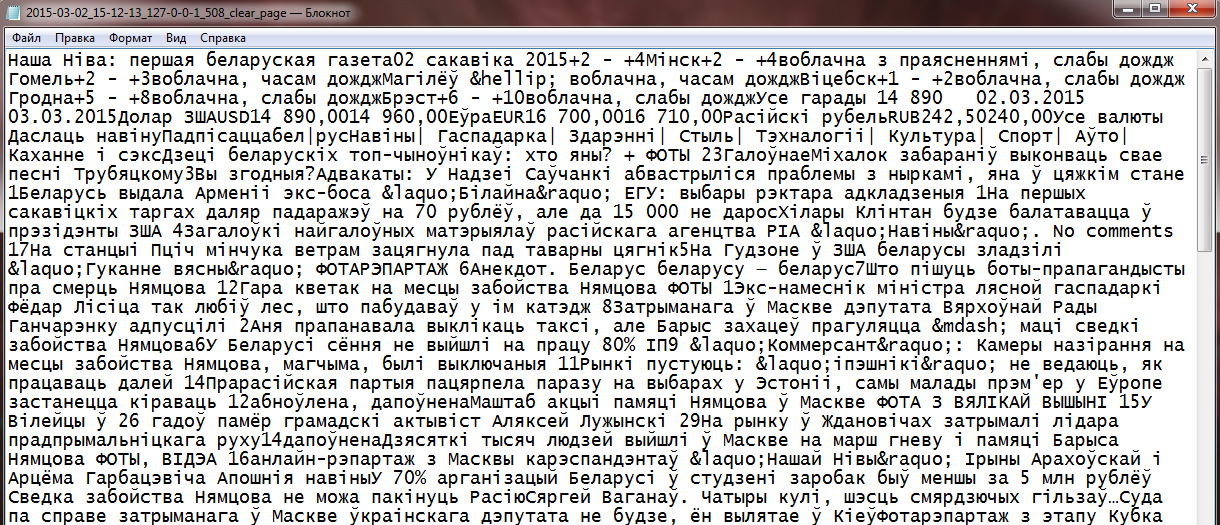 Figure 3 – Fragment of the document without tags
Figure 3 – Fragment of the document without tags
Access to the service via the API
To access the service «Web Page Content Saver» via the API, you should send an AJAX-request (type: POST) to the address https://corpus.by/WebPageContentSaver/api.php. With an input array data the following parameters are passed:
- url — web-page URL.
Example of AJAX-request:
$.ajax({
type: “POST”,
url: “https://corpus.by/WebPageContentSaver/api.php”,
data:{
“url”: “https://www.nn.by”
},
success: function(msg){ },
error: function() { }
});
The server returns a JSON-array with the following parameters:
- url — input web-page URL.
- full — URL of the resulting file with full HTML text.
- clear — URL of the resulting file with text without HTML markup.
For example, the following reply will be formed on the above listed AJAX-request:
[
{
“url”: “https://www.nn.by”,
“full”: “https://corpus.by/_cache/WebPageContentSaver/out/2018-05-17_13-56-14_80-94-162-88_939_full_page.txt”,“clear”: “https://corpus.by/_cache/WebPageContentSaver/out/2018-05-17_13-56-14_80-94-162-88_939_clear_page.txt”
}
]
Service page: https://corpus.by/WebPageContentSaver/?lang=en