The service «Homograph Identifier» is disigned for recognition and highlighting of homographs in the text. The service receives electronic text, the user receives a list of homographs found in the text with their detailed data as the results of processing.
Basic terms and concepts
Homonymy – the coincidence of words or their forms with a complete difference in meaning. It is important to distinguish homonymy from polysemy (the presence of several meanings in one word).
Homonyms – different in meaning but identical in spelling and pronounciation language units (words, morphemes, etc.). For example, Bel. «тур» – an ancient wild bull, «тур» – a selection stage and «тур» – a trip to different places.
Homography – a property of two or more characters having the same graphic form, but with different meanings. Homography is graphic homonymy.
Homographs – words that have the same spelling and different pronunciation. For example, Rus. каза́чка and казачка́.
Practical value
The service will be useful for all the needs of finding homographs. Such needs may arise:
– In case of conducting a study of a certain text for the presence and functioning of homographs in it. Studies of this type may be useful for corpus linguistics.
– In case of preparing text for processing by a speech synthesizer in order to obtain sound text. Timely identification of homographs and the correct placement of accents will significantly improve the quality of the speech synthesizer work.
Text processing by this service is one of the steps in the methodology of large texts proofreading. In this methodology the service helps to identify homographs for the further placement of accents in those homography cases on which the meaning of the text depends.
Service features
Identification of homographs goes through several dictionaries that the service uses:
SBM1987 (according to the publication “Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987″)
SBM2012initial (initial forms according to the publication “Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. – Мінск : Беларус. навука, 2012″)
NOUN2013 (according to the publication “Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013″)
ADJECTIVE2013 (according to the publication “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013″)
NUMERAL2013 (according to the publication “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013″)
PRONOUN2013 (according to the publication “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013″)
VERB2013 (according to the publication “Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013″)
ADVERB2013 (according to the publication “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013″)
ZALIZNIAK (according to the publication “Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. – Москва : Русский язык, 1980. – 880 c.”)
CMU (according to “Carnegie Mellon University Pronouncing Dictionary”)
*UWP_BE (Belarusian words from the dictionary available by the link)
*UWP_RU (Russian words from the dictionary available by the link)
Dictionaries marked with * are in the process of expanding their vocabulary.
The user can select from the list those dictionaries that are necessary for him to analyze the text. For example, to search for homography in a text in Belarusian, it is advisable to select the dictionaries SBM1987, SBM2012initial and others, in Russian – only the ZALIZNIAK dictionary, in English – only the CMU dictionary.
Text processing by the service currently has the following features:
– Search is carried out for each dictionary selected by the user separately. It means that cases of interlanguage homography like Bel. «выго́да» (1. Everything that indulges the maximum needs, what is convenient to use; 2. Open space) – Rus. «вы́года» (Profit, income derived from something) or Bel. «свая́» (possessive pronoun) – Rus. «сва́я» (timber which is hammered into the ground to support the structure) will not be revealed. If interlanguage homography is present, but homographic variations can be found for a word within the same language, for example, as in the case of «го́дны» and «годны́» for the Russian language (one of the forms is also present in the Belarusian language) or «ра́са» and «раса́» for the Belarusian language (one of the forms is also present in the Russian language), the service will show only homography within the framework of one language.
– To carry out a correct search in dictionaries, words are preliminarily reduced to one register – upper or lower (depending on the dictionary). Also at the present moment dictionaries that can be connected do not contain proper names. It means that cases like Rus. «Ко́ли» (male name in the genitive case) and «коли́» (imperative mood of the 2nd person singular of the verb «колоть») or «Ма́ши» (female name in the genitive case) and «маши́» (imperative mood of the 2nd person singular of the verb «махать») will not be considered by the service as homographic.
– The letters of the Russian alphabet «е» and «ё» are considered by the service as different. It means that cases of homography like «же́ны» («жёны») and «жены́» will not be marked as homographic.
– According to the Oxford Dictionary, in English the word Homograph means «a word that is spelt like another word but has a different meaning from it, and may have a different pronunciation, for example bow / baʊ /, bow / bəʊ /». It means that English homographs are determined by the service according to other rules. For example, the word “awesome” will be a homograph, because it has different pronunciation variants of the initial vowel, as well as «record», because it has one spelling for words with different meanings (verb and noun), and the pronunciation of these words differs by accent.
Service operation algorithm
Algorithm input data:
- User text input, UText;
- A set of dictionaries connected by the user, Dictionaries;
- A set of Cyrillic characters in upper and lower case, LettersCyr;
- A set Latin characters in upper and lower case, LettersLat;
- A set of additional characters (apostrophes, accents, hyphen), AdditionalCharacters.
The beginning of the algorithm.
Step 1.1. Creating the set of main characters MainCharacters by merging the sets LettersCyr and LettersLat.
Step 1.2. Splitting UText into ParagrapsArr set by line feed character. Creation of an empty associative array UniqueWordsArr for subsequent recording of unique words found in ParagrapsArr.
Step 1.3. For each element Paragraph of the ParagrapsArr set, perform steps 1.3.1. – 1.3.4.
Step 1.3.1. Remove all initial and last indent characters from Paragraph.
Step 1.3.2. If Paragraph = ∅, go to the next Paragraph element and perform step 1.3.1.
Step 1.3.3. Creating the WordsArr array and filling it with elements made up from Paragraph content. An «element» is a special set of characters from the beginning of a line to a space, from space to space and from space to the end of a line (or a newline character) that matches the pattern <[1 character of MainCharacters] + [0 or more characters of MainCharacters and AdditionalCharacters]> or the pattern <[0 or more characters of MainCharacters]>. Creating a WordsCnt variable and recording the number of WordsArr elements into it.
Step 1.3.4. For I = 0; I < WordsCnt, I++ perform steps 1.3.4.1. – 1.3.4.2.
Step 1.3.4.1. Creating a Word = WordsArr[I] variable.
Step 1.3.4.2. If Word ≠ ∅, reduce all Word characters to lowercase and replace all the initial characters «ў» with «у» (necessary for the subsequent correct search in dictionaries). Try to record Word to the UniqueWordsArr associative array using the Word value as a key and assigning it a value of 1. If the word by the Word key is already present in UniqueWordsArr, increment the value corresponding to it.
Step 2.1 Creating an associative array UniqueHomographsArr for subsequent recording of unique homographs and related information.
Step 2.2 For each UniqueWord in UniqueWordsArr and each Dictionary in Dictionaries, perform steps 2.2.1. – 2.2.3.
Step 2.2.1. Create associative arrays AccentArr and ResultArr. If Dictionary = Homographs_Be (that is, at this step of the cycle the dictionary with this name is viewed), check if Dictionary contains an element identical to the current UniqueWord element. If contains, record the value of the element of the dictionary entry Category corresponding to the current UniqueWord to the AccentArr array, and the value of the corresponding elements of the dictionary entry AccentedWord, Category and LexemeId to the ResultArr array, then go to step 2.2.3. Otherwise, go to the next step.
Step 2.2.2. If Dictionary ≠ Homographs_Be, perform steps 2.2.2.1 – 2.2.2.3.
Step 2.2.2.1. Create a variable UniqueWordWithSlashes and record the value of the current UniqueWord surrounded by slash characters into it. If also UniqueWordWithSlashes consists only of characters belonging to the LettersLat set surrounded by slash characters, cast all UniqueWordWithSlashes characters to uppercase. Create a Query variable to store the query to the dictionary database and generate its value according to the template «SELECT * FROM% s WHERE word = ‘% s», where %s is the value of UniqueWordWithSlashes. This step is necessary for the correct search in dictionary databases.
Step 2.2.2.2. If any data in the current Dictionary using the query recorded in the Query variable is found, then until the standard database access function reaches the last row (Row) in the result table, perform steps 2.2.2.2.1. – 2.2.2.2.3.
Step 2.2.2.2.1. Create an AccentedWord variable. If an Accent dictionary entry element is specified in the current Row, record its lowercase value in AccentedWord; if there is no «+» symbol in AccentedWord, complete this step of the cycle, go to the next Row and perform step 2.2.2.2.1. again. If the Accent element is not specified, record the value of the Transcription element reduced to lowercase in AccentedWord.
Step 2.2.2.2.2. If both the LexemeId element and the Tag element are specified in the current Row, reinitialize Query with the value «SELECT * FROM tags WHERE tag = ‘% s’ LIMIT 1», where %s is the value of the Tag element, and try to find any data for this query . If the data is found, then for each row of the result table, record the value of the element of the dictionary entry Category (if any) to the created CategoryVar variable, and the value of the element of the dictionary entry LexemeId into the LexemeIdVar variable, and then free the system resources from the query results.
Step 2.2.2.2.3. Write the value CategoryVar to the array AccentArr, the values AccentedWord, CategoryVar and LexemeIdVar to the array ResultArr.
Step 2.2.2.3. Clear system resources from the results of queries to dictionary databases.
Step 2.2.3. If more than one element is present in AccentArr, perform steps 2.2.3.1. – 2.2.3.8.
Step 2.2.3.1. If UniqueHomographsArr does not have an element equal to the current UniqueWord, set such an element as an empty array. Create an AccentList variable and initialize it with an empty value.
Step 2.2.3.2. For each AccentedWord element in AccentArr (this element has its own CategoryArr array), perform the following actions in direct order:
- Add value of current AccentedWord to AccentList.
- If CategoryArr ≠ ∅, add to AccentList the string « <small>(», value of all unique elements of CategoryArr imploded into a siring via string «, », and the string «)</small>».
- Add the string «<br>\n» to
Step 2.2.3.3. Replace in AccentList all combinations [any character +«=»character] with the same character but equipped with a grave accent symbol and surrounded by HTML tags for makin it blue. Replace in AccentList all combinations [any character + «+» character] with the same character, but equipped with the acute accent character and surrounded by HTML tags to making it red.
***Steps 2.2.3.2. and 2.2.3.3. are necessary for the formation of the correct issuance***
Step 2.2.3.4. Remove duplicate values from ResultArr. Create associative arrays LexemeIdArr and CategoryArr.
Step 2.2.3.5. If the HomographArray element corresponding to the current UniqueWord, which in its turn corresponds to the current Dictionary, is not specified (hereinafter, this element will be named as X), then for each WordInfo element in ResultArr check whether the element of the dictionary entry Category and the element LexemeId are specified in it. If at least one of these elements is not specified, write the Accents value equal to AccentList and the Type value equal to «-» in X (that is, the type of homography is not defined).
Step 2.2.3.6. If X is not specified after the previous step, then for each WordInfo element in ResultArr, check whether the WordInfo element is specified in LexemeIdArr, which in its turn corresponds to the element of the dictionary entry LexemeId. If it is not specified, make it equal to one, otherwise write the Accents value equal to AccentList and the Type value equal to «one paradigm» in X (that is, homographs belong to the same declination or conjugation paradigm).
Step 2.2.3.7. If X is not specified after the previous step, then for each WordInfo element in ResultArr, check whether the WordInfo element is specified in CategoryArr, which in its turn corresponds to the element of the dictionary entry Category. If it is not specified, make it equal to one, otherwise write in X the value of Accents, equal to AccentList, and the value of Type, equal to «one part of speech» (that is, homographs belong to one part of speech).
Step 2.2.3.8. If after the previous step X is not specified, then write in X the value of Accents equal to AccentList and the value of Type equal to «different parts of speech» (that is, homographs belong to different parts of speech).
Step 3. Formation of contexts. For each element Paragraph of the ParagrapsArr set, perform steps 3.1. – 3.4.
Step 3.1. Remove all initial and last indent characters from Paragraph.
Step 3.2. If Paragraph = ∅, go to the next Paragraph element and perform step 3.1.
Step 3.3. Creating the WordsArr array and filling it with elements made up from Paragraph content. An «element» is a special set of characters from the beginning of a line to a space, from space to space and from space to the end of a line (or a newline character) that matches the pattern <[1 character of MainCharacters] + [0 or more characters of MainCharacters and AdditionalCharacters]> or the pattern <[0 or more characters of MainCharacters]>. Creating a WordsCnt variable and writing the number of WordsArr elements into it.
Step 3.4. For I = 0; I < WordsCnt, I++ perform steps 3.4.1. – 3.4.3.
Step 3.4.1. Creating a Word = WordsArr[I] variable.
Step 3.4.2. If Word ≠ ∅, reduce all Word characters to lowercase and replace all initial characters «ў» with «у».
Step 3.4.3. For a UniqueHomographsArr array element equal to the Word value, write in UniqueHomographsArr Y elements that are situated in WordsArr before the Word element, the Word element itself and Y elements that are situated in WordsArr after the Word element, 0 ⩽ Y ⩽ 3, Y ∈ N, where N is the set of natural numbers.
Step 4. Formation of the issue. For each homograph found, present accent variants, the type of homograph, the number of appearing of this homograph in the source text, contexts of use and the name of the dictionary in which the homograph was found.
The end of the algorithm.
User interface description
The user interface of the service is shown in Figure 1.
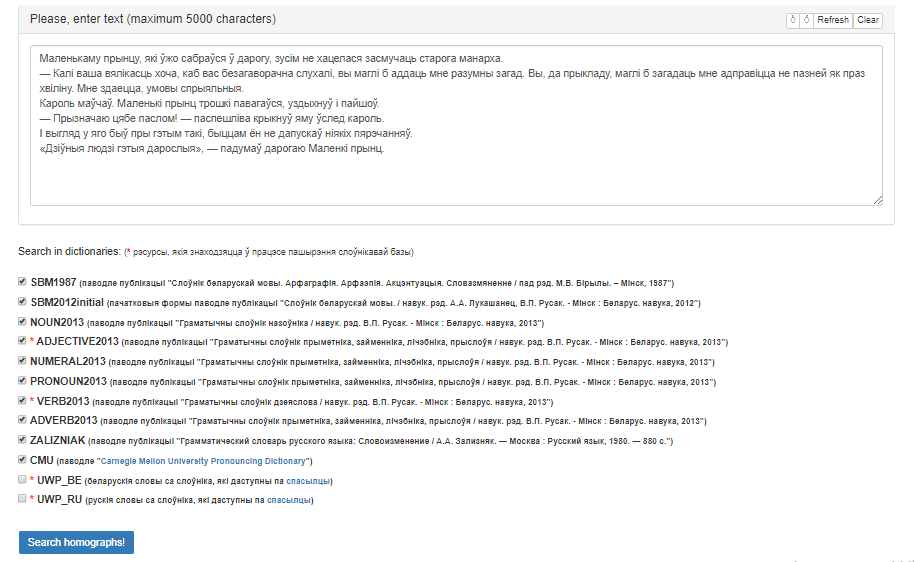
Figure 1 – Graphical interface of the service «Homograph Identifier»
The interface contains the following areas:
- input field for electronic text;
- field for choosing dictionaries;
- “Search homographs!” button which starts processing;
- field for outputting results that appears after processing and looks like a table.
The following data is displayed in the output field:
- homograph word;
- accent variants in homograph words;
- type of homograph (part-of-speech definition);
- number of entries in the text;
- contexts of entries;
- a dictionary (dictionaries) by which a search for homographs was made.
The service also offers the user to receive homographs in the form of a regular list. To get such a list, you must click on the appropriate link in the output field.
User scenarios of work with the service
Scenario 1: Search homographs with the default dictionaries
- Enter in the input field text that requires the identification of homographs.
- Press the button «Search homographs!» to run the search and to get results.
- View the list of found homographs in the output field and, if necessary, make changes to the source text (for example, put written accents on).
Scenario 1: Search homographs with the user-chosen dictionaries
- Enter in the input field text that requires the identification of homographs.
- Choose necessary dictionaries.
- Press the button «Search homographs!» to run the search and to get results.
- View the list of found homographs in the output field and, if necessary, make changes to the source text (for example, put written accents on).
A possible result of the service work is presented in Figure 2.
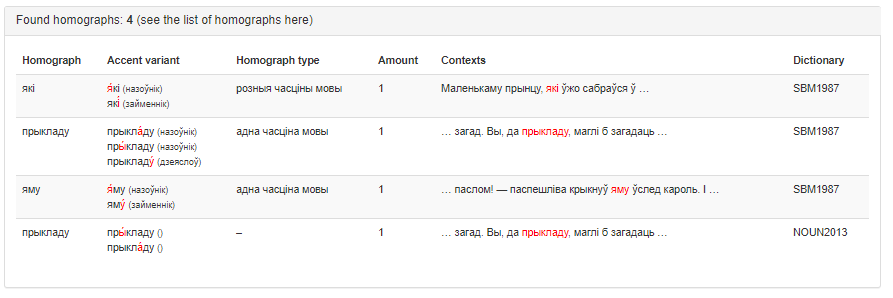
Figure 2 – Result of the «Homograph Identifier» service work
Access to the service via the API
To access the service «Homograph Identifier» via the API you need to send an AJAX request of the POST type to the address https://corpus.by/HomographIdentifier/api.php. The following parameters are passed through the data array:
- text – arbitrary input text.
- Markers of the use of dictionaries:
- sbm1987 – «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987»;
- sbm2012initial – «Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. – Мінск : Беларус. навука, 2012»;
- noun2013 – nouns according to the book «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adjective2013 – adjectives according to the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- numeral2013 – numerals according to the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- pronoun2013 – pronouns according to the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- verb2013 – verbs according to the book «Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adverb2013 – adverbs according to the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- zalizniak – «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. – Москва : Русский язык, 1980. – 880 c.»;
- cmu – «Carnegie Mellon University Pronouncing Dictionary»;
- uwp_be – Belarusian words collected by the system «Unknown Words Processing»;
- uwp_ru – Russian words collected by the system «Unknown Words Processing».
Example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/HomographIdentifier/api.php”,
data:{
“text”: “– Маё жыццё такое аднастайнае. Я палюю на курэй, людзі палююць на мяне. Усе куры падобны адна на адну, і ўсе людзі падобны адзін на аднаго. З гэтай прычыны мне і сумнавата. Але, калі ты прыручыш мяне, жыццё маё нібы сонцам азарыцца. Я навучуся распазнаваць твае крокі сярод тысячы іншых. Калі я чую людскія крокі, я ўцякаю і хаваюся. Твае ж паклічуць мяне з нары як музыка. І потым – паглядзі! Бачыш, там, удалечыні, жытняе поле? Я не ем хлеба. Жыта мне ні да чаго. Збажына нічога не напамінае мне. І гэта так сумна! А ў цябе залатыя валасы. І як цудоўна было б, калі б ты прыручыў мяне! Залатое жыта заўсёды было б мне напамінкам пра цябе… Я палюбіў бы песню ветру ў калоссі…”,
“sbm1987”: 1,
“sbm2012initial”: 1
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with input text (parameter text), a list of homographs found in the text (parameter result), an array with details of the result (parameter resultArr), the number of identified homographs (parameter resultCnt) and a link to the list of identified homographs (parameter resultUrl). For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “Груша цвіла апошні грод.”,
“result”: “куры
людскія
нары
музыка
музыка”,
“resultArr”: {
“SBM1987”: {
“куры”: {
“accents”: “ку́ры куры́”,
“type”: “адна часціна мовы”,
“count”: 1,
“contexts”: “… на мяне. Усе куры падобны адна на …”
},
“людскія”: {
“accents”: “лю́дскія людскі́я”,
“type”: “адна часціна мовы”,
“count”: 1,
“contexts”: “… Калі я чую людскія крокі, я ўцякаю …”
},
“нары”: {
“accents”: “нары́ на́ры”,
“type”: “адна часціна мовы”,
“count”: 1,
“contexts”: “… паклічуць мяне з нары як музыка. І …”
},
“музыка”: {
“accents”: “музы́ка му́зыка”,
“type”: “адна часціна мовы”,
“count”: 1,
“contexts”: “… з нары як музыка. І потым – паглядзі! …”
}
},
“SBM2012initial”: {
“музыка”: {
“accents”: “музы́ка му́зыка”,
“type”: “–”,
“count”: 1,
“contexts”: “… з нары як музыка. І потым – паглядзі! …”
}
}
},
“resultCnt”: “5”,
“resultUrl”: “https://corpus.by/<…>”,
}
]
Source references
Service page: https://corpus.by/HomographIdentifier/?lang=be
Cross references
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Окрут, Т.І. Вырашэнне праблемы амаграфіі з дапамогай NOOJ для больш чым 50 амографаў рускай мовы / Т.І. Окрут, Д.А. Пакладок, Ю.С. Гецэвіч, Б.М. Лабанаў // Контрастивные исследования и прикладная лингвистика : материалы Междунар. науч. конф., Минск, 29-30 окт. 2014 г. В 2 ч. Ч.2 / отв. ред.: А.В. Зубов, Т.П. Карпилович. – Минск : МГЛУ, 2015. — P. 79-83.
- Okrut, T. Context-Sensitive Homograph Disambiguation with NooJ in Belarusian and Russian Electronic Texts / T. Okrut, B. Lobanov, Y. Yakubovich // International Scientific Conference on the Automatic Processing of Natural-Language Electronic Texts “NooJ’2015″ / ed. B.M. Lobanov, Yu.S.Hetsevich. — Minsk : UIIP NASB, 2015. — P. 48.
- Станіславенка, Г.Р. Рэдагаванне электронных масіваў тэкстаў на беларускай мове з выкарыстаннем камп’ютарна-лінгвістычных сэрвісаў платформы www.corpus.by / Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 262-267.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.