Сэрвіс «Ідэнтыфікатар амографаў» прызначаны для распазнавання і вылучэння ў тэксце амографаў. На ўваход сэрвісу падаецца электронны тэкст, па выніках апрацоўкі карыстальнік атрымлівае спіс знойдзеных у тэксце амографаў з іх падрабязнымі дадзенымі.
Асноўныя тэрміны і паняцці
Аманімія – супадзенне слоў ці іх форм пры поўнай адрознасці ў значэнні. Ад аманіміі важна адрозніваць полісемію (наяўнасць некалькіх значэнняў у аднаго слова).
Амонімы – розныя па значэнні, але аднолькавыя па напісанні і гучанні адзінкі мовы (словы, марфемы і інш.). Напрыклад, тур – першабытны дзікі бык, тур – этап адбору і тур – паездка па розных мясцінах.
Амаграфія – уласцівасць двух ці некалькіх знакаў, што маюць адну графічную форму, але розныя значэнні. Амаграфія – гэта графічная аманімія.
Амографы – словы, якія маюць аднолькавае напісанне і рознае вымаўленне. Напрыклад, му́зыка і музы́ка.
Практычная каштоўнасць
Сэрвіс будзе карысным для ўсіх патрэб знаходжання амографаў. Такія патрэбы могуць узнікнуць:
- Пры правядзенні даследавання пэўнага тэксту на наяўнасць і функцыянаванне ў ім амографаў. Даследаванні дадзенага кшталту могуць быць карыснымі для корпуснай лінгвістыкі;
- Пры падрыхтоўцы тэксту да апрацоўкі сінтэзатарам маўлення з мэтай атрымаць гукавы тэкст. Своечасовае выяўленне амографаў і правільная расстаноўка націскаў дазволяць значна павысіць якасць працы маўленчага сінтэзатара.
Апрацоўка тэксту дадзеным сэрвісам – адзін з этапаў методыкі вычыткі тэксту вялікага памеру, дзе сэрвіс дапамагае выявіць амографы для далейшай расстаноўкі націскаў у тых выпадках амаграфіі, ад якіх залежыць сэнс тэксту.
Асаблівасці сэрвіса
Ідэнтыфікацыя амографаў ідзе па некалькіх слоўніках, да якіх звяртаецца сэрвіс:
SBM1987 (паводле публікацыі “Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987”)
SBM2012initial (пачатковыя формы паводле публікацыі “Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. – Мінск : Беларус. навука, 2012”)
NOUN2013 (паводле публікацыі “Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013”)
ADJECTIVE2013 (паводле публікацыі “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013”)
NUMERAL2013 (паводле публікацыі “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013”)
PRONOUN2013 (паводле публікацыі “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013”)
VERB2013 (паводле публікацыі “Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013”)
ADVERB2013 (паводле публікацыі “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013”)
ZALIZNIAK (паводле публікацыі “Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. – Москва : Русский язык, 1980. – 880 c.”)
CMU (паводле “Carnegie Mellon University Pronouncing Dictionary”)
*UWP_BE (беларускія словы са слоўніка, які даступны па спасылцы)
*UWP_RU (рускія словы са слоўніка, які даступны па спасылцы)
Слоўнікі, адзначыныя *, знаходзяцца ў працэсе пашырэння слоўнікавай базы.
Карыстальнік можа абраць з дадзенага спісу тыя слоўнікі, якія яму патрэбныя для аналізу тэксту. Напрыклад, для пошуку амаграфіі ў тэксце на беларускай мове мэтазгодна абраць слоўнікі SBM1987, SBM2012initial і іншыя, на рускай мове – толькі слоўнік ZALIZNIAK, на англійскай мове – толькі слоўнік CMU.
Апрацоўка тэксту сэрвісам на дадзены момант мае наступныя асаблівасці:
– Пошук ажыццяўляецца па кожным абраным карыстальнікам слоўніку асобна. Гэта значыць, што выпадкі міжмоўнай амаграфіі кшталту бел. «выго́да» (1.Усё, што задавальняе максімальныя запатрабаванні, чым зручна карыстацца; 2. Прыволле) – рус. «вы́года» (Прыбытак, даход, які атрымліваецца з чаго-небудзь) ці бел. «свая́» (прыналежны займеннік) – рус. «сва́я» (брус, які забіваецца ў грунт для апоры збудавання) выяўленыя не будуць. Калі міжмоўная амаграфія прысутнічае, але для слова могуць быць знойдзеныя амаграфічныя варыянты ў межах адной мовы, напрыклад, як у выпадках «го́дны» і «годны́» для рускай мовы (адна з форм прысутнічае таксама ў беларускай мове) ці «ра́са» і «раса́» для беларускай мовы (адна з форм прысутнічае таксама ў рускай мове), сэрвісам будзе прадэманстравана толькі амаграфія ў межах адной мовы.
– Для ажыццяўлення карэктнага пошуку ў слоўніках словы папярэдне прыводзяцца да аднаго рэгістру – верхняга ці ніжняга (у залежнасці ад слоўніка). Таксама на дадзены момант слоўнікі, якія можна падключыць, не змяшчаюць уласныя імёны. Гэта значыць, што выпадкі кшталту рус. «Ко́ли» (мужчынскае імя ў родным склоне) і «коли́» (загадны лад 2-й асобы адзіночнага ліку дзеяслова «колоть») ці «Ма́ши» (жаночае імя ў родным склоне) і «маши́» (загадны лад 2-й асобы адзіночнага ліку дзеяслова «махать») не будуць разглядацца сэрвісам як амаграфічныя.
– Літары рускага алфавіта «е» і «ё» лічацца сэрвісам рознымі. Гэта значыць, што выпадкі амаграфіі кшталту «же́ны» («жёны») і «жены́» не будуць пазначаныя як амаграфічныя.
– Паводле Оксфардскага слоўніка, у ангельскай мове слова «Homograph» азначае «a word that is spelt like another word but has a different meaning from it, and may have a different pronunciation, for example bow /baʊ/, bow /bəʊ/» (бел. «слова, якое пішацца так, як іншае слова, але мае рознае з ім значэнне і можа мець рознае вымаўленне, напрыклад, bow /baʊ/, bow /bəʊ/»). Гэта значыць, што ангельскія амографы вызначаюцца сэрвісам па іншых правілах. Напрыклад, амографам будзе з’яўляцца слова «awesome», паколькі яно мае розныя варыянты вымаўлення пачатковага галоснага, а таксама «record», паколькі мае адно напісанне для слоў з рознымі значэннямі (дзеяслова і назоўніка), да таго ж вымаўленне дадзеных слоў розніцца націскамі.
Алгарытм працы сэрвіса
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, UText;
- Мноства слоўнікаў, падключаных карыстальнікам, Dictionaries;
- Мноства кірылічных сімвалаў у верхнім і ніжнім рэгістры, LettersCyr;
- Мноства лацінскіх сімвалаў у верхнім і ніжнім рэгістры, LettersLat;
- Мноства дадатковых сімвалаў (апострафы, сімвалы націскаў, злучок), AdditionalCharacters.
Пачатак алгарытму.
Крок 1.1. Стварэнне мноства асноўных сімвалаў MainCharacters шляхам зліцця мностваў LettersCyr і LettersLat.
Крок 1.2. Раздзяленне UText на мноства ParagrapsArr паводле сімвала пераводу радка. Стварэнне пустога асацыятыўнага масіву UniqueWordsArr для наступнага запісу ўнікальнх слоў, знойдзеных у ParagrapsArr.
Крок 1.3. Для кожнага элемента Paragraph мноства ParagrapsArr выканаць крокі 1.3.1. – 1.3.4.
Крок 1.3.1. Выдаліць з Paragraph усе пачатковыя і канцавыя сімвалы водступаў.
Крок 1.3.2. Калі Paragraph = ∅, перайсці да наступнага элемента Paragraph і выканаць крок 1.3.1.
Крок 1.3.3. Стварэнне масіву WordsArr і запаўненне яго элементамі, складзенымі са зместу Paragraph. «Элементам» лічыцца спецыяльны набор сімвалаў ад пачатку радка да прабелу, ад прабелу да прабелу і ад прабелу да канца (або сімвалу пераводу) радка, які адпавядае шаблону <[1 сімвал MainCharacters]+[0 або больш сімвалаў MainCharacters і AdditionalCharacters]> альбо шаблону <[ 0 або больш сімвалаў MainCharacters]>. Стварэнне пераменнай WordsCnt і запіс у яе колькасці элементаў WordsArr.
Крок 1.3.4. Для I = 0; I < WordsCnt, I++ выканаць крокі 1.3.4.1. – 1.3.4.2.
Крок 1.3.4.1. Стварэнне пераменнай Word = WordsArr[I].
Крок 1.3.4.2. Калі Word ≠ ∅, прывесці ўсе сімвалы Word да ніжняга рэгістра і замяніць усе пачатковыя сімвалы «ў» на «у» (неабходня для наступнага карэктнага пошуку ў слоўніках). Паспрабаваць запісаць Word у асацыятыўны масіў UniqueWordsArr, выкарыстоўваючы значэнне Word у якасці ключа і прысвоіўшы яму значэнне 1. Калі слова паводле ключа Word ужо прысутнічае у UniqueWordsArr, інкрэментаваць адпаведнае яму значэнне.
Крок 2.1. Стварэнне асацыятыўнага масіву UniqueHomographsArr для наступнага запісу ўнікальных амографаў і спадарожнай інфармацыі.
Крок 2.2. Для кожнага UniqueWord у UniqueWordsArr і кожнага Dictionary у Dictionaries выканаць крокі 2.2.1. – 2.2.3.
Крок 2.2.1. Стварыць асацыятыўныя масівы AccentArr і ResultArr. Калі Dictionary = Homographs_ Be (гэта значыць, што на дадзеным кроку цыкла праглядаецца слоўнік з такою назвай), праверыць, ці прысутнічае ў Dictionary элемент, ідэнтычны бягучаму элементу UniqueWord. Калі прысутнічае, запісаць у масіў AccentArr значэнне элемента слоўнікавага артыкула Category, які адпавядае бягучаму UniqueWord, а ў масіў ResultArr – значэнне адпаведных элементаў слоўнікавага артыкула AccentedWord, Category і LexemeId, пасля чаго перайсці да кроку 2.2.3. Інакш – перайсці да наступнага кроку.
Крок 2.2.2. Калі Dictionary ≠ Homographs_Be, выканаць крокі 2.2.2.1. – 2.2.2.3.
Крок 2.2.2.1. Стварыць пераменную UniqueWordWithSlashes і запісаць у яе значэнне бягучага UniqueWord, акружанае сімваламі слэша. Калі пры гэтым UniqueWordWithSlashes складаецца толькі з сімвалаў, якія належаць да мноства LettersLat, акружаных сімваламі слэша, прывесці ўсе сімвалы UniqueWordWithSlashes да верхняга рэгістра. Стварыць пераменную Query для захоўвання запыту да слоўнікавай базы і сфарміраваць яе значэнне згодна з шаблонам «SELECT * FROM %s WHERE word=’%s», где %s – значэнне UniqueWordWithSlashes. Дадзены крок неабходны для ажыццяўлення карэктнага пошуку па слоўнікавых базах.
Крок 2.2.2.2. Калі паводле запыту, запісанага ў пераменнай Query, у бягучым Dictionary удалося знайсці якія-небудзь дадзеныя, то да таго моманту, пакуль стандартная функцыя звароту да базы дадзеных не дойдзе да апошняга радка Row у табліцы вынікаў, выконваць крокі 2.2.2.2.1. – 2.2.2.2.3.
Крок 2.2.2.2.1. Стварыць пераменную AccentedWord. Калі ў бягучым Row зададзены элемент слоўнікавага артыкула Accent, запісаць у AccentedWord яго значэнне, прыведзеная да ніжняга рэгістра; калі пры гэтым у AccentedWord адсутнічае сімвал «+», завяршыць дадзены крок цыкла, перайсці да наступнага Row і выканаць 2.2.2.2.1. яшчэ раз. Калі элемент Accent не зададзены, запісаць у AccentedWord значэнне элемента Transcription, прыведзенае да ніжняга рэгістра.
Крок 2.2.2.2.2. Калі ў бягучым Row задедзены і элемент LexemeId, і элемент Tag, рэініцыялізаваць Query значэннем значением «SELECT * FROM tags WHERE tag=’%s’ LIMIT 1», дзе %s – значэнне элемента Tag, і паспрабаваць знайсці якія-небудзь дадзеныя паводле гэтага запыту. Калі дадзеныя ўдалося знайсці, то для кожнага радка табліцы вынікаў запісаць у створаную пераменную CategoryVar значэнне элемента слоўнікавага артыкула Category (калі ён зададзены), а ў пераменную LexemeIdVar – значэнне элемента слоўнікавага артыкула LexemeId, пасля чаго вызваліць сістэмныя рэсурсы ад вынікаў запыту.
Крок 2.2.2.2.3. Запісаць у масіў AccentArr значэнне CategoryVar, у масіў ResultArr – значэнні AccentedWord, CategoryVar і LexemeIdVar.
Крок 2.2.2.3. Ачысціць сістэмныя рэсурсы ад вынікаў запытаў да слоўнікавых баз дадзеных.
Крок 2.2.3. Калі ў AccentArr прысутнічае больш за адзін элемент, выканаць крокі 2.2.3.1. – 2.2.3.8.
Крок 2.2.3.1. Калі ў UniqueHomographsArr не зададзены элемент, роўны бягучаму UniqueWord, задаць такі элемент у выглядзе пустога масіву. Стварыць пераменную AccentList і ініцыялізаваць яе пустым значэннем.
Крок 2.2.3.2. Для кожнага элемента AccentedWord у AccentArr (дадзенаму элементу адпавядае свой масіў CategoryArr) здзейсніць наступныя дзеянні ў прамым парадку:
- Дадаць да AccentList значэнне бягучага AccentedWord.
- Калі CategoryArr ≠ ∅, дадаць да AccentList радок « <small>(» значэнне ўсіх унікальных элементаў CategoryArr, аб’яднаных у радок з дапамогай радка «, », і радок «)</small>».
- Дадаць да AccentList радок «<br>\n».
Крок 2.2.3.3. Замяніць у AccentList усе камбінацыі [любы сімвал + сімвал «=»] на той жа сімвал, але забяспечаны сімвалам пабочнага націску і акружаны тэгамі HTML для надання яму сіняга колеру. Замяніць у AccentList усе камбінацыі [любы сімвал + сімвал «+»] на той жа сімвал, але забяспечаны сімвалам асноўнага націску і акружаны тэгамі HTML для надання яму чырвонага колеру.
*** Крокі 2.2.3.2. і 2.2.3.3. неабходныя для фарміравання карэктнай выдачы***
Крок 2.2.3.4. Выдаліць з ResultArr значэнні, якія паўтараюцца. Стварыць асацыятыўныя масівы LexemeIdArr і CategoryArr.
Крок 2.2.3.5. Калі элемент HomographArray, які адпавядае бягучаму UniqueWord, які ў сваю чаргу адпавядае бягучаму Dictionary, не зададзены (тут і далей гэты элемент будзе названы як X), то для кожнага элемента WordInfo у ResultArr праверыць, ці зададзены ў ім элемент слоўнікавага артыкула Category і элемент LexemeId. Калі хаця б адзін з дадзеных элементаў не зададзены, запісаць у X значэнне Accents, роўнае AccentList, і значэнне Type, роўнае «-» (г. зн. тым амаграфіі не вызначаны).
Крок 2.2.3.6. Калі пасля папярэдняга кроку X не зададзены, то для кожнага элемента WordInfo у ResultArr праверыць, ці зададзены ў LexemeIdArr элемент WordInfo, які ў сваю чаргу адпавядае элементу слоўнікавага артыкула LexemeId. Калі не зададзены, зрабіць яго роўным адзінцы, інакш запісаць у X значэнне Accents, роўнае AccentList, і значэнне Type, роўнае «one paradigm» (г. зн. амографы належаць да адной парадыгмы скланення або спражэння).
Крок 2.2.3.7. Калі пасля папярэдняга кроку X не зададзены, то для кожнага элемента WordInfo у ResultArr праверыць, ці зададзены ў CategoryArr элемент WordInfo, які ў сваю чаргу адпавядае элементу слоўнікавага артыкула Category. Калі не зададзены, зрабіць яго роўным адзінцы, інакш запісаць у X значэнне Accents, роўнае AccentList, і значэнне Type, роўнае «one part of speech» (г. зн. амографы належаць да адной часціны мовы).
Крок 2.2.3.8. Калі пасля папярэдняга кроку X не зададзены, то запісаць у X значэнне Accents, роўнае AccentList, і значэнне Type, роўнае «different parts of speech» (г. зн. амографы належаць да розных часцін мовы).
Крок 3. Фарміраванне кантэкстаў. Для кожнага элемента Paragraph мноства ParagrapsArr выканаць крокі 3.1. – 3.4.
Крок 3.1. Выдаліць з Paragraph усе пачатковыя і канцавыя сімвалы водступаў.
Крок 3.2. Калі Paragraph = ∅, перайсці да наступнага элемента Paragraph і выканаць крок 3.1.
Крок 3.3. Стварэнне масіву WordsArr і запаўненне яго элементамі, складзенымі са зместу Paragraph. «Элементам» лічыцца спецыяльны набор сімвалаў ад пачатку радка да прабелу, ад прабелу да прабелу і ад прабелу да канца (або сімвалу пераводу) радка, які адпавядае шаблону <[1 сімвал MainCharacters]+[0 або больш сімвалаў MainCharacters і AdditionalCharacters]> альбо шаблону <[ 0 або больш сімвалаў MainCharacters]>. Стварэнне пераменнай WordsCnt і запіс у яе колькасці элементаў WordsArr.
Крок 3.4. Для I = 0; I < WordsCnt, I++ выканаць крокі 3.4.1. – 3.4.3.
Крок 3.4.1. Стварэнне пераменнай Word = WordsArr[I].
Крок 3.4.2. Калі Word ≠ ∅, прывесці ўсе сімвалы Word да ніжняга рэгістра і замяніць усе пачатковыя сімвалы «ў» на «у».
Крок 3.4.3. Для элемента масіву UniqueHomographsArr, роўнага значэнню Word, запісаць у UniqueHomographsArr Y элементаў, якія ідуць у WordsArr да элемента Word, сам элемент Word і Y элементаў, якія ідуць у WordsArr пасля элемента Word, 0 ⩽ Y ⩽ 3, Y ∈ N, дзе N – мноства натуральных лікаў.
Крок 4. Фарміраванне выдачы. Для кожнага знойдзенага амографа прадставіць варыянты націску, тып амографа, колькасць сустраканняў дадзенага амографа ў зыходным тэксце, кантэксты ўжывання і назву слоўніка, у якім дадзены амограф быў знойдзены.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Карыстальніцкі інтэрфейс сэрвіса прадстаўлены на малюнку 1.
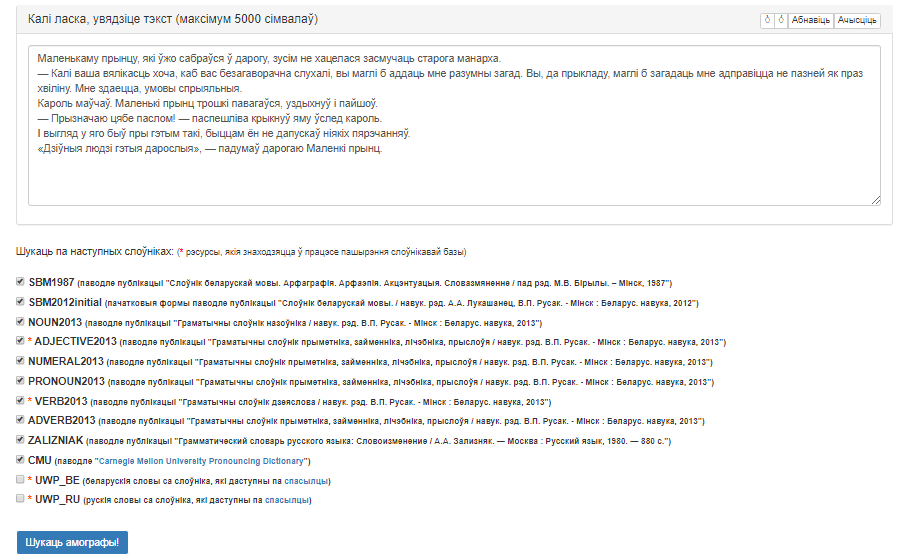
Малюнак 1 – Графічны інтэрфейс сэрвіс «Ідэнтыфікатар амографаў»
Інтэрфейс змяшчае наступныя вобласці:
- поле ўводу электроннага тэксту;
- поле выбару слоўнікаў;
- кнопка «Шукаць амографы!», якая запускае апрацоўку;
- поле вываду вынікаў, якое з’яўляецца пасля апрацоўкі і мае выгляд табліцы.
У полі вываду вынікаў выводзяцца наступныя дадзеныя:
- слова-амограф;
- варыянты націску ў словах-амографах;
- тып амографа (часцінамоўнае вызначэнне);
- колькі разоў ужываецца ў тэксце;
- кантэксты ўжывання;
- слоўнік(і), па якім(якіх) быў праведзены пошук амографаў.
Таксама сэрвіс прапануе карыстальніку атрымаць амографы ў форме звычайнага спіса. Каб атрымаць такі спіс, патрэбна націснуць на адпаведную спасылку ў полі вываду.
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Пошук па слоўніках, абраных па змаўчанні
- Увесці ў поле ўводу тэкст, які патрабуе вызначэння амографаў.
- Націснуць кнопку «Шукаць амографы!» для запуску пошуку і атрымання вынікаў.
- Прагледзець спіс знойдзеных амографаў у полі вываду і пры патрэбе ўнесці праўкі ў зыходны тэкст (напрыклад, паставіць націскі).
Сцэнар 2. Пошук па слоўніках, абраных карыстальнікам
- Увесці ў поле ўводу тэкст, які патрабуе вызначэння амографаў.
- Выбраць неабходныя слоўнікі.
- Націснуць кнопку «Шукаць амографы!» для запуску пошуку і атрымання вынікаў.
- Прагледзець спіс знойдзеных амографаў у полі вываду і пры патрэбе ўнесці праўкі ў зыходны тэкст (напрыклад, паставіць націскі).
Магчымы вынік працы сэрвіса прадстаўлены на малюнку 2.
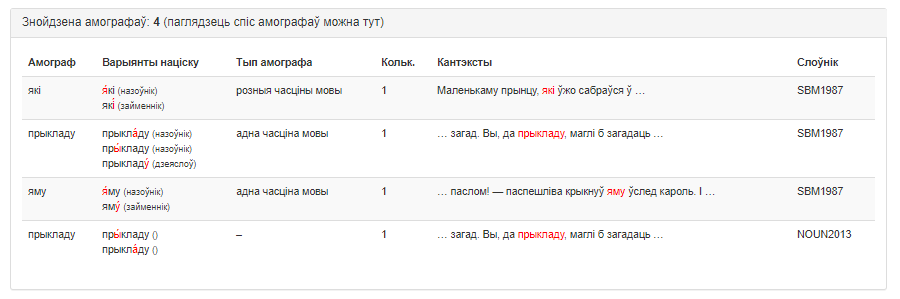
Малюнак 2 – Вынік працы сэрвіса «Ідэнтыфікатар амографаў»
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Ідэнтыфікатар амографаў» праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/HomographIdentifier/api.php. Праз масіў data перадаюцца наступныя параметры:
- text – адвольны ўваходны тэкст.
- Маркеры выкарыстання слоўнікаў:
- sbm1987 – «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987»;
- sbm2012initial – «Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. – Мінск : Беларус. навука, 2012»;
- noun2013 – назоўнікі паводле кнігі «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adjective2013 – прыметнікі паводле кнігі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- numeral2013 – лічэбнікі паводле кнігі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- pronoun2013 – займеннікі паводле кнігі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- verb2013 – дзеясловы паводле кнігі «Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adverb2013 – прыслоўі паводле кнігі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- zalizniak – «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. – Москва : Русский язык, 1980. – 880 c.»;
- cmu – «Carnegie Mellon University Pronouncing Dictionary»;
- uwp_be – беларускія словы, сабраныя сістэмай «Апрацоўка невядомых слоў»;
- uwp_ru – рускія словы, сабраныя сістэмай «Апрацоўка невядомых слоў».
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/HomographIdentifier/api.php”,
data:{
“text”: “– Маё жыццё такое аднастайнае. Я палюю на курэй, людзі палююць на мяне. Усе куры падобны адна на адну, і ўсе людзі падобны адзін на аднаго. З гэтай прычыны мне і сумнавата. Але, калі ты прыручыш мяне, жыццё маё нібы сонцам азарыцца. Я навучуся распазнаваць твае крокі сярод тысячы іншых. Калі я чую людскія крокі, я ўцякаю і хаваюся. Твае ж паклічуць мяне з нары як музыка. І потым – паглядзі! Бачыш, там, удалечыні, жытняе поле? Я не ем хлеба. Жыта мне ні да чаго. Збажына нічога не напамінае мне. І гэта так сумна! А ў цябе залатыя валасы. І як цудоўна было б, калі б ты прыручыў мяне! Залатое жыта заўсёды было б мне напамінкам пра цябе… Я палюбіў бы песню ветру ў калоссі…”,
“sbm1987”: 1,
“sbm2012initial”: 1
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з уваходным тэкстам (параметр text), спісам знойдзеных у тэксце амографаў (параметр result), масівам з дэталямі выніку (параметр resultArr), колькасцю выяўленых амографаў (параметр resultCnt) і спасылкай на спіс выяўленых амографаў (параметр resultUrl). Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “Груша цвіла апошні грод.”,
“result”: “куры
людскія
нары
музыка
музыка”,
“resultArr”: {
“SBM1987”: {
“куры”: {
“accents”: “ку́ры куры́”,
“type”: “адна часціна мовы”,
“count”: 1,
“contexts”: “… на мяне. Усе куры падобны адна на …”
},
“людскія”: {
“accents”: “лю́дскія людскі́я”,
“type”: “адна часціна мовы”,
“count”: 1,
“contexts”: “… Калі я чую людскія крокі, я ўцякаю …”
},
“нары”: {
“accents”: “нары́ на́ры”,
“type”: “адна часціна мовы”,
“count”: 1,
“contexts”: “… паклічуць мяне з нары як музыка. І …”
},
“музыка”: {
“accents”: “музы́ка му́зыка”,
“type”: “адна часціна мовы”,
“count”: 1,
“contexts”: “… з нары як музыка. І потым – паглядзі! …”
}
},
“SBM2012initial”: {
“музыка”: {
“accents”: “музы́ка му́зыка”,
“type”: “–”,
“count”: 1,
“contexts”: “… з нары як музыка. І потым – паглядзі! …”
}
}
},
“resultCnt”: “5”,
“resultUrl”: “https://corpus.by/<…>”,
}
]
Спасылкі на крыніцы
Старонка сэрвіса: https://corpus.by/HomographIdentifier/?lang=be
Перакрыжаваныя спасылкі
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Окрут, Т.І. Вырашэнне праблемы амаграфіі з дапамогай NOOJ для больш чым 50 амографаў рускай мовы / Т.І. Окрут, Д.А. Пакладок, Ю.С. Гецэвіч, Б.М. Лабанаў // Контрастивные исследования и прикладная лингвистика : материалы Междунар. науч. конф., Минск, 29-30 окт. 2014 г. В 2 ч. Ч.2 / отв. ред.: А.В. Зубов, Т.П. Карпилович. – Минск : МГЛУ, 2015. — P. 79-83.
- Okrut, T. Context-Sensitive Homograph Disambiguation with NooJ in Belarusian and Russian Electronic Texts / T. Okrut, B. Lobanov, Y. Yakubovich // International Scientific Conference on the Automatic Processing of Natural-Language Electronic Texts “NooJ’2015″ / ed. B.M. Lobanov, Yu.S.Hetsevich. — Minsk : UIIP NASB, 2015. — P. 48.
- Станіславенка, Г.Р. Рэдагаванне электронных масіваў тэкстаў на беларускай мове з выкарыстаннем камп’ютарна-лінгвістычных сэрвісаў платформы www.corpus.by / Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 262-267.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.