The «Text Summarizer» service is designed to automatically summarize arbitrary text documents. It takes any text data as an input and returns its summary as an output.
Basic terms and concepts
Source text – any input text data to summarize.
Summary – a shortened version of the source text.
Summarization – the process of making the summary of the source text.
Text mining – the process of deriving useful information from text.
Practical value
Text summarization is used in many text mining algorithms like classification and clustering in order to reduce text sizes and increase performance accordingly.
Service operation algorithm
The algorithm is based on this paper.
Input:
- Source text, ST (string)
- Threshold parameter, T (float)
- Error tolerance parameter, ET (float)
- Summary length in sentences, L (integer)
Output:
- Summary, S (string)
Algorithm:
- let T_w = log(N / N_w) for each word w in ST, where N is the ST sentences number, N_w is the number of sentences containing word w
- let L_w_i be the number of occurrences of word w in the i-th sentence
- let W_i be a set of i-th sentence words
- let G = (V, E, W) be an undirected complete graph with vertices V, edges E and edge weights W, where
V = {the s-th serial number in ST | ∀ sentence s ∈ ST},
E = {(i, j) | ∀ i, j ∈ V ⨯ V, i ≠ j},
W = {Num_i_j / (√Den_i * √Den_j) | ∀ (i, j) ∈ E)}, where
Num_i_j = sum of L_w_i * L_w_j * T_w^2 for each word w in W_i ∩ W_j,
Den_i = sum of (L_w_i * T_w)^2 for each word w in the i-th sentence - for each edge e ∈ E with weight w ∈ W:
if w > T then:
w = 1
else:
E = E \ {e} - for each remaining edge (i, j) ∈ E with weight w ∈ W:
w = w / (D_i * D_j)
, where D_i is the i-th vertex degree - let M be an incidence matrix of the resulting graph G
- for each element (i, j) ∈ M with value M_i_j and corresponding edge weight w ∈ W:
if M_i_j ≠ 0 then:
M_i_j = w - let R be a N-vector; initially R = (1 / N, 1 / N, …, 1 / N)
- while the Euclidean norm of R values at the current and previous iterations is greater than ET:
R = M^T ⨯ R - sort R in descending order
- extract the L most valuable sentences from ST corresponding to the first L coordinates of R
- join the extracted sentences into the summary S in the order of appearance in ST and return S
User interface description
The interface of the service is shown in Figure 1.
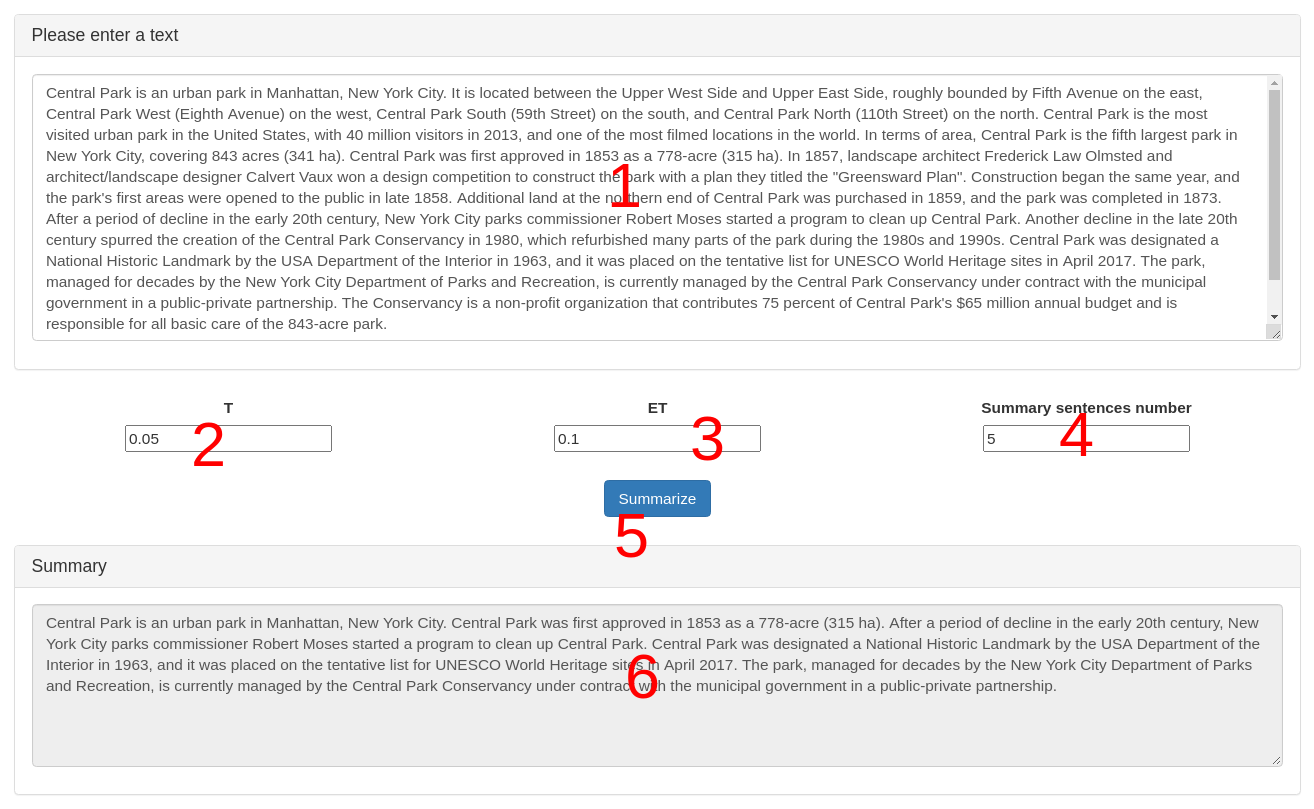
Figure 1 – Graphical interface of the service «Text Summarizer»
The interface has the following areas:
- source text input field
- threshold input field
- error tolerance input field
- summary length input field
- start summarization button
- summary output field
Possible scenario for working with the service:
- enter any text data in the source text input field (1)
- specify the summary sentences number (4)
- press the «Summarize» button (5)
- analyze the resulting summary (6)
- fine tune the algorithm parameters if necessary (2, 3)
Access to the service via the API
To access the «Text Summarizer» via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/TextSummarizer/api. The following parameters are passed through the data array:
- text – text to summarize (mandatory)
- threshold – threshold parameter (optional, 0.05 by default)
- tolerance – error tolerance parameter (optional, 0.1 by default)
- length – summary length in sentences (optional, 5 by default)
Example of AJAX-request:
$.ajax({
type: “POST”,
url: “https://corpus.by/TextSummarizer/api”,
data: {
“text”: “Брэст — горад у Беларусі, адміністрацыйны цэнтр Брэсцкай вобласці і Брэсцкага раёна, на рацэ Заходні Буг пры ўпадзенні ў яго Мухаўца. За 349 км ад Мінска. Тэрыторыя горада — 146,12 км². Насельніцтва 343 985 чал. З’яўляецца адным з найважнейшых транспартных вузлоў Беларусі. Эканамічны і культурны цэнтр, вузел чыгунак і аўтамабільных дарог, аэрапорт, рачны порт, звязаны Дняпроўска-Бугскім каналам з басейнамі Дняпра і Прыпяці. Упершыню згадваецца ў «Аповесці мінулых гадоў» пад назваю Бе́рестье, у гістарычных крыніцах таксама сустраюцца напісанні Бересте, Бересть, у нямецкіх летапісах Брэйзіка. Тапонім «Берасце» ўтварыўся ад слова «бе́раст», «бе́расць» (дрэвавая ці куставая расліна сямейства вязавых). Значэнне мае хутчэй за ўсё зборнае — бераставы гай.”,
“threshold”: “0.05”,
“length”: “1”,
},
origin: “*”,
contentType: “application/json; charset=utf-8”,
headers: {
“x-api-key” : “123”
},
success: function(msg) { },
error: function(err) { }
});
The server returns a JSON-array with the following keys:
- text – text to summarize
- threshold – threshold parameter
- tolerance – error tolerance parameter
- length – summary length in sentences
- summary – resulting summary
For example, the following reply will be formed on the above listed AJAX-request:
{
“text”: “Брэст — горад у Беларусі, адміністрацыйны цэнтр Брэсцкай вобласці і Брэсцкага раёна, на рацэ Заходні Буг пры ўпадзенні ў яго Мухаўца. За 349 км ад Мінска. Тэрыторыя горада — 146,12 км². Насельніцтва 343 985 чал. З’яўляецца адным з найважнейшых транспартных вузлоў Беларусі. Эканамічны і культурны цэнтр, вузел чыгунак і аўтамабільных дарог, аэрапорт, рачны порт, звязаны Дняпроўска-Бугскім каналам з басейнамі Дняпра і Прыпяці. Упершыню згадваецца ў «Аповесці мінулых гадоў» пад назваю Бе́рестье, у гістарычных крыніцах таксама сустраюцца напісанні Бересте, Бересть, у нямецкіх летапісах Брэйзіка. Тапонім «Берасце» ўтварыўся ад слова «бе́раст», «бе́расць» (дрэвавая ці куставая расліна сямейства вязавых). Значэнне мае хутчэй за ўсё зборнае — бераставы гай.”,
“threshold”: “0.05”,
“tolerance”: “0.1”,
“length”: “1”,
“summary”: “Брэст — горад у Беларусі, адміністрацыйны цэнтр Брэсцкай вобласці і Брэсцкага раёна, на рацэ Заходні Буг пры ўпадзенні ў яго Мухаўца.”,
}
Source references
Service page – https://corpus.by/TextSummarizer/?lang=en