The “Phonetic Minimizer” service allows the user to form a minimized set of sentences covering all phonetic units present in the original corpus basing on a corpus of texts in Belarusian. The service receives the text entered by the user or the user selected text base. The user can define two minimization parameters: the base unit by which minimization is carried out, and the search boundary to which a search is performed for each unique phonetic unit. The output consists of three text files: a file with a minimized corpus of sentences, a file with a list of unique phonetic units, and a file with a list of rare phonetic units.
Basic terms and concepts
Text-to-speech synthesizer – a system capable of generating text by speech. It contains two blocks: the block of linguistic processing of text to a phonemic form with the notation of accent, intonation (prosody) and rhythm, and also the block for processing a speech signal that converts the previously received phonemic form into an audio speech signal.
Phonetic minimization – a special selection of texts, as a result of which the volume of the text corpus will be maximally reduced, but phonetic completeness will be preserved.
Practical value
The “Phonetic Minimizer” service can help solve a number of tasks. First of all, the service can be applied in developing a system for synthesizing Belarusian speech based on a language model. The significantly reduced corpus volume makes the creation of such systems affordable for a wide range of developers and researchers. In addition, the automation of the selection of the minimized phonetically complete set of texts in the Belarusian language can be used in a number of diverse scientific fields, for example, in linguistic studies or in the creation of special manuals for the study of Belarusian phonetics.
User interface description
The graphical interface of the service is shown in Figure 1.
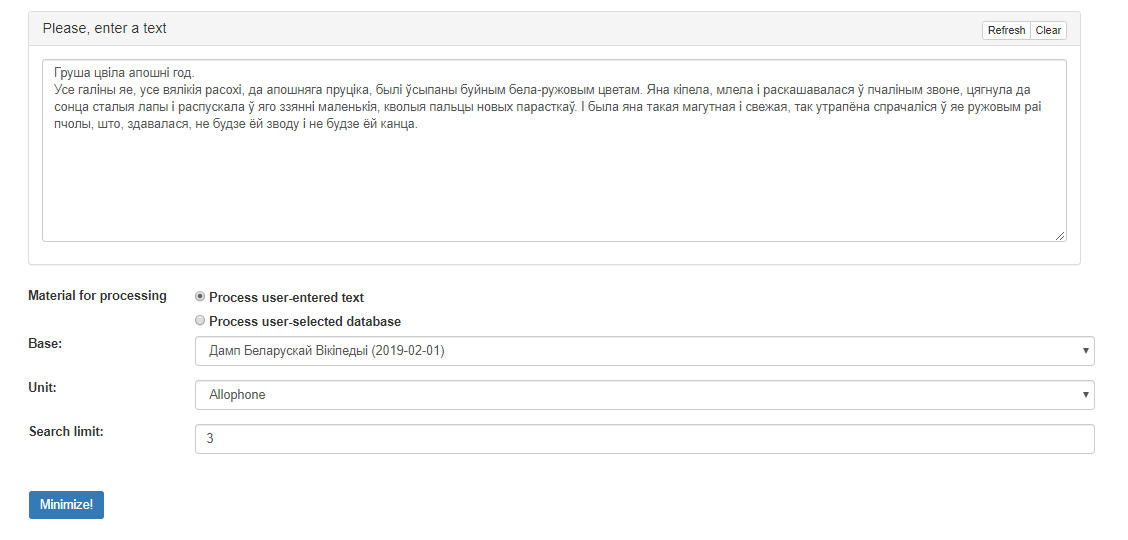
Figure 1 – Graphical interface of the service «Phonetic minimizer»
The interface contains the following areas:
-
text field: the field for entering the corpus of sentences;
- radio button: selection of the input method for data that will be processed;
- selector: selection of the text database for processing;
- selector: select the base unit for processing;
- text line: a line for determining the quantitative boundary of the search;
- the button “Minimize!”, which starts processing and gives the opportunity to get results.
User scenarios of working with the service
Scenario 1. Working with user-entered text
1. Go to the “Phonetic Minimizer” service page.
2. Among the group of options “Material for processing”, select the option “Process user-entered text”.
3. Enter the input text for processing.
4. Select the base unit for processing.
5. Define the search boundary.
6. Click on the “Minimize!” Button
Scenario 2. Working with the user-selected database
1. Go to the “Phonetic Minimizer” service page.
2. Among the group of options “Material for processing”, select the option “Process user-selected database”.
3. Select a database of texts for processing.
4. Select the base unit for processing.
5. Define the search boundary.
6. Click on the “Minimize!” button
The results of the service work are presented in Figure 2 and 3.


Figure 2, 3 – Results of the «Phonetic Minimizer» service work
Phonetic minimization algorithm
The “Phonetic Minimizer” algorithm makes it possible to form a minimized corpus of texts covering all sound units present in the original corpus.
Allophonic text in a format that uses a speech synthesizer (https://corpus.by/TextToSpeechSynthesizer/?lang=be) was taken as a phonetic representation of the text. Such a text is a sequence of designations of allophones, pauses, word boundaries and syllable boundaries. Below is a fragment of the spelling text and its corresponding allophone text.
Груша цвіла апошні год. Усе галіны яе, усе вялікія расохі, да апошняга пруціка, былі ўсыпаны бурным бела-ружовым цветам.
GH004,R022,U022,>,SH002,A323,/,>,C’002,V’002,I241,>,L002,A012,/,>,A221,>,P001,O012,>,SH002,N’004,I242,/,>,GH001,O032,T000,/,>,#P4,>,U203,>,S’001,E042,/,>,GH004,A233,>,L’002,I042,>,N004,Y323,/,>,J’012,A243,>,J’011,E040,/,>,#C3,>,U203,>,S’001,E043,/,>,V’012,A243,>,L’002,I043,>,K’002,I343,>,J’012,A342,/,>,R002,A222,>,S001,O023,>,H’002,I340,/,>,#C3,>,D004,A322,>,A221,>,P001,O012,>,SH002,N’004,A342,>,GH004,A231,/,>,P002,R012,U023,>,C’002,I342,>,K004,A330,/,>,#C3,>,B002,Y013,>,L’004,I241,/,>,W013,S001,Y021,>,P002,A312,>,N004,Y221,/,>,B002,U012,R001,>,N004,Y221,M001,/,>,B’002,E141,>,L004,A312,>,R002,U222,>,ZH002,O021,>,V012,Y211,M003,/,>,C’002,V’001,E042,>,T002,A321,M000,/,>,#P4
The codes of the allophones in this list consist of the alphabetic name of the phoneme (for example, GH), the symbol of softness «’» (if any) and a digital code indicating one or another phoneme specificity. In a series of experiments described below not only complete (for example, ZH002), but also shortened (for example, ZH0) records of allophones will be used, in which the last two digits indicating the context of the allophone in the word are discarded. Also in this list you can observe the symbols of the word boundary «/» and the syllable boundary «>».
Algorithm input data:
- A file with a sentence corpus in an allophone record, Fs;
- Basic phonetic unit, unit;
- Search boundary, lim (defines the minimum required amount of each unique phonetic unit).
The beginning of the algorithm.
Step 1. Creating a list of sentences. Uploading a file with a list of sentences in the allophone record Fs occurs. The list Ls = <s1, …, sN> is formed, where sn is the nth sentence, n = 1, …, N.
Step 2. Selection of sentences with the necessary phonetic units. An empty set Ls‘ is created for entering the selected sentences into it, as well as a counter of phonetic units Cnt, where phonetic units and their quantities are collected in the selected sentences of the set Ls‘. Each sentence sn from the set of sentences Ls goes through steps 2.1–2.3.
Step 2.1 Forming of a list of phonetic units of the sentence. All phonetic elements of the sentence sn are selected according to the selected basic phonetic unit unit. If the basic phonetic unit is an allophone or syllable, then the section is performed according to the corresponding separating characters present in the allophone record of sentences. If the base unit is a combination of the above units, such as a dyphone, triphone, etc., first a division into elementary units from which combinations are subsequently made is carried out. The result will be a set of phonetic units Un = <u1, …, uM>, where um is the mth phonetic unit of the sentence sn, m = 1, …, M.
Step 2.2 Choice of the sentence. Enumerating the phonetic units um from the set Un is implemented. If the further phonetic unit occurs in the Cnt counter less than lim times, then the enumeration stops and transition to step 2.3 occurs. Otherwise, if all the phonetic units of the sentence are enumerated, but none of them matches the above condition, we proceed to the next sentence sn+1 and step 2.1. If the processed sentence is the last sentence of the set (n = N), then go to step 3.
Step 2.3 Listing sentences in a variety of selected. Enumerating the phonetic units um from the set Un is implemented. If um is absent in the Cnt counter, a corresponding record is created with a value of one. If the phonetic unit is already in the Cnt counter, then the corresponding value increases by one. If all phonetic units of the sentence are enumerated, the transition to the next sentence sn+1 and step 2.1 occurs. If the processed sentence is the last sentence of the list Ls (n = N), then transition to step 3 occurs.
Step 3. Minimizing the set of selected offers. An empty set Ls” is created for entering only those selected sentences from the set Ls‘ that contain at least one phonetic element, the removal of which reduces the total number of such elements below the search boundary lim. A copy of the Cnt counter of phonetic units Cnt‘ is created, where the correspondences of phonetic units and their quantities in the minimized set Ls” are collected. Each sentence s‘k from the set of sentences Ls‘ goes through the following four steps.
Step 3.1 Forming of a list of phonetic units of the sentence. All phonetic elements of the sentence s‘k are distinguished by the selected phonetic unit unit by anology with step 2.1. The set of phonetic units is transformed into the set of correspondences of the phonetic units and their quantities in the set. Thus, the result of the step is the set U’k = << u’1, cnt1>, …, <u’J, cntJ >>, where u’j is the jth phonetic unit, cntj is the number of meetings of the phonetic unit u’j in the sentence s’k, j = 1, …, J.
Step 3.2 Choosing the sentence. The phonetic units u‘j from the set U‘k are being enumerated. If the difference in the number of meetings of the phonetic unit u‘j in the set of selected sentences Ls‘ and the set of phonetic units of the current sentence U‘k is less than the boundary lim, then the enumeration stops – proceeding to step 3.3 occurs. Otherwise, if all the phonetic units of the sentence are enumerated, but none of them corresponds to the above condition, the transition to step 3.4 occurs.
Step 3.3 Listing sentences in a minimized set. The sentence s‘k is entered in the minimized set Ls‘‘. Proceeding to the next sentence s‘k+1 and step 3.1 occurs. If the processed sentence is the last sentence of the set (k = K), then go to step 4.
Step 3.4 Deleting the sentence. All phonetic elements of the sentence s‘k are represented in the remaining sentences of the set Ls‘ in sufficient quantity, therefore the sentence is not included in the minimized list Ls”. The phonetic units u‘j from the set U‘k are being enumerated. The frequencies of each phonetic unit cntk are subtracted from the frequency of the corresponding phonetic unit in the counter Cnt‘. If all phonetic units of a sentence are enumerated, the transition to the next sentence s‘k+1 and step 3.1 occurs. If the processed sentence is the last sentence of the set (k = K), then go to step 4.
Step 4. Forming of the result. The set of Ls” sentences is sorted by the Belarusian alphabet, and the Cnt counter is sorted by frequency. The result is brought in a vivid text format, displayed on the screen and saved in a file on the server.
The end of the algorithm.
Access to the service via the API
To access the “Phonetic Minimizer” service via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/PhoneticMinimizer/api.php. The following parameters are passed through the data array:
- text – a text corpus in Belarusian.
- unit – the basic phonetic unit. The following base units are available: allophone, dyphone, triphone, syllable, allophoneShort, dyphoneShort, triphoneShort, syllableShort.
- limit – the search boundary that determines the minimum required amount of each unique phonetic unit.
An example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/PhoneticMinimizer/api.php”,
data:{
“text“: “Усе галіны яе, усе вялікія расохі, да апошняга пруціка, былі ўсыпаны буйным бела-ружовым цветам. Яна кіпела, млела і раскашавалася ў пчаліным звоне, цягнула да сонца сталыя лапы і распускала ў яго ззянні маленькія, кволыя пальцы новых парасткаў. І была яна такая магутная і свежая, так утрапёна спрачаліся ў яе ружовым раі пчолы, што, здавалася, не будзе ёй зводу і не будзе ёй канца.”,
“unit”: “allophone”,
“limit”: “1“
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with the following parameters:
- filename – the name of the file on the server in which the received minimized sentence corpus is saved.
- MinimizedCorpusCnt – the number of sentences after minimization.
- UniqueUnitsCnt – the number of unique phonetic units.
- RaritiesCnt – the number of rare phonetic units (phonetic units that were found in number less than limit).
For example, using the above AJAX request, the following response will be generated:
[
{
“filename”: “2020-01-17_17-28-54_80-94-171-2_288_minText.txt”,
“MinimizedCorpusCnt”: “1”,
“UniqueUnitsCnt”: “68”,
“RaritiesCnt”: “0”
}
]
References to sources
Service page: https://corpus.by/PhoneticMinimizer/?lang=be
Cross references