Service «Tokenizer» is intended to highlight tokens in the text. The text that requires tokenization is sent to the service input. After processing the text on the output, the user receives a list of the extended tokens.
Basic terms and concepts
Tokenization — selection of tokens in the text by a special computer program. This is the process of analyzing the input sequence of symbols into lexemes, in order to obtain the output of the identified sequences, the so-called «tokens». Lexical analysis is used in the compilers and interpreters of the source code of programming languages, and in various parsers of words of natural languages.
Token (lexical analysis) — a sequence of characters in lexical analysis in computer science, corresponding to a lexeme. An object that is created from a lexeme in the process of lexical analysis (tokenization).
Token template — a formal description of the class of tokens that can create this type of token.
User Interface Description
The user interface of the service is shown in Figure 1.
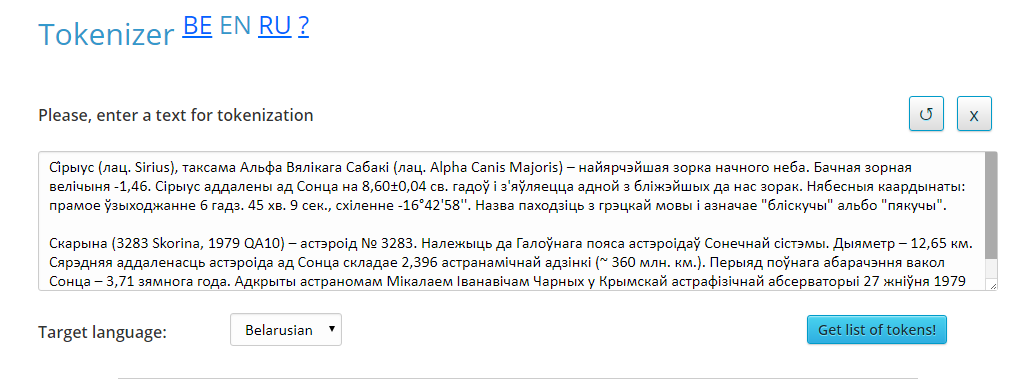
Figure 1. User interface of the service «Tokenizer»
The interface has the following areas:
- text input field that requires tokenization;
- language selection menu;
- the button «Get list of tokens!», which starts tokenization;
- output field where selected tokens are displayed.
User script for working with the service
- Enter the text that requires tokenization in the input field.
- Choose a language.
- Click the button «Get list of tokens!».
- View highlighted tokens (Figure 2).
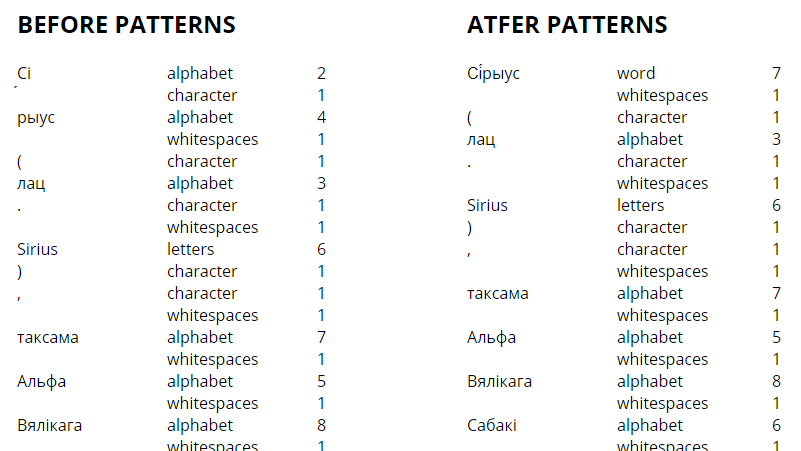 Figure 2. «Tokenizer» results example
Figure 2. «Tokenizer» results example
Access to the service via the API
To access the service «Tokenizer» via the API, you should send an AJAX-request (type: POST) to the address https://corpus.by/Tokenizer/api.php. With an input array data the following parameters are passed:
- inputText — arbitrary input text.
- language — language of the input text. Belarusian (параметр be), English (параметр en) and Russian (параметр ru) are available.
Example of AJAX-request:
$.ajax({
type: “POST”,
url: “https://corpus.by/Tokenizer/api.php”,
data:{
“inputText”: “Сі́рыус (лац. Sirius), таксама Альфа Вялікага Сабакі (лац. Alpha Canis Majoris) – найярчэйшая зорка начного неба.”,
“language”: “be”
},
success: function(msg){ },
error: function() { }
});
The server returns a JSON-array with the following parameters:
- text — input text.
- CharacterArr — array with grouped character sequences.
- ResultArr — array with character sequences grouped according to additional rules.
For example, the following reply will be formed on the above listed AJAX-request:
[
{
“text”: “Сі́рыус (лац. Sirius), таксама Альфа Вялікага Сабакі (лац. Alpha Canis Majoris) – найярчэйшая зорка начного неба.”,
“CharacterArr”: {
“0”: {
“0”: “Сі”,
“1”: “alphabet”,
“2”: 2
},
“1”: {
“0”: “́”,
“1”: “character”,
“2”: 1
},
“2”: {
“0”: “рыус”,
“1”: “alphabet”,
“2”: 4
},
<…>
},
“ResultArr”: {
“0”: {
“0”: “Сі́рыус”,
“1”: “word”,
“2”: 7
},
“1”: {
“0”: ” “,
“1”: “whitespaces”,
“2”: 1
},
“2”: {
“0”: “(“,
“1”: “character”,
“2”: 1
},
<…>
}
}
]
Links to sources
Service page: https://corpus.by/Tokenizer/?lang=en