Service «Talking Head Synthesizer» provides a visualization of the text entered by the user. An electronic text is sent to the service input, the service processes the input text and forms a video file with an animated head that says the entered phrase. «Talking head» conveys the facial expressions of a human head and the synthesized sound when pronouncing an incoming text. The user can view the final video file and save it.
Basic terms and concepts
Speech synthesis — the formation of a speech signal in the electronic text.
Text-to-speech synthesizer (TTS) is a system capable of generating speech from text. It contains two blocks: a linguistic word processing unit for a phoneme view with marks of accent, intonation (prosody) and rhythm, as well as a speech signal processing unit that converts a previously received phoneme view into a speech sound signal.
Features of the service
The service generates «talking heads» from a person’s photo. Now, the service allows visualizing the input text with the help of four «talking heads», three of which are male speech synthesizer and one female speech synthesizer:
- B.M. Labanaŭ (Barys speech synthesizer);
- A.V. Tuzikaŭ (Barys speech synthesizer);
- U.V. Haliankoŭ (Barys speech synthesizer);
- L.I. Tsyrulnik (Alesia speech synthesizer).
In order to create a personal «head», it is necessary to take several photos of a person’s face in certain positions of the mouth and lips mimicry. Synthesizing the «talking head», the service uses the work of «Text-to-speech synthesizer», and also builds a sequence of photos with the positions of the lips corresponding to thethe phoneme that is synthesized (pronounced «talking head») at a particular moment.
The service is at the stage of refinement and improvement, therefore now a large amount of text is synthesized with difficulty. In this regard, it is desirable to submit to the input text of no more than one sentence.
Practical value
The service will help to perceive speaking to people with hearing impairments, since they will have the opportunity to see facial expressions when pronouncing the input phrase. This expands the possibilities and scope of speech synthesizer. The service allows you to further personalize the input text, since it creates «talking heads» based on photographs of real-life people. «Talking heads» have prospects of application in the following areas:
- telephone call systems from infokiosks;
- voice and alarm alert systems;
- e-book reading systems;
- training systems;
- talking computers for the visually and hearing impaired;
- personalization of online presence for people with disabilities (personal speaking avatar).
Description of the user interface
The graphical interface of the service is shown in Figure 1.
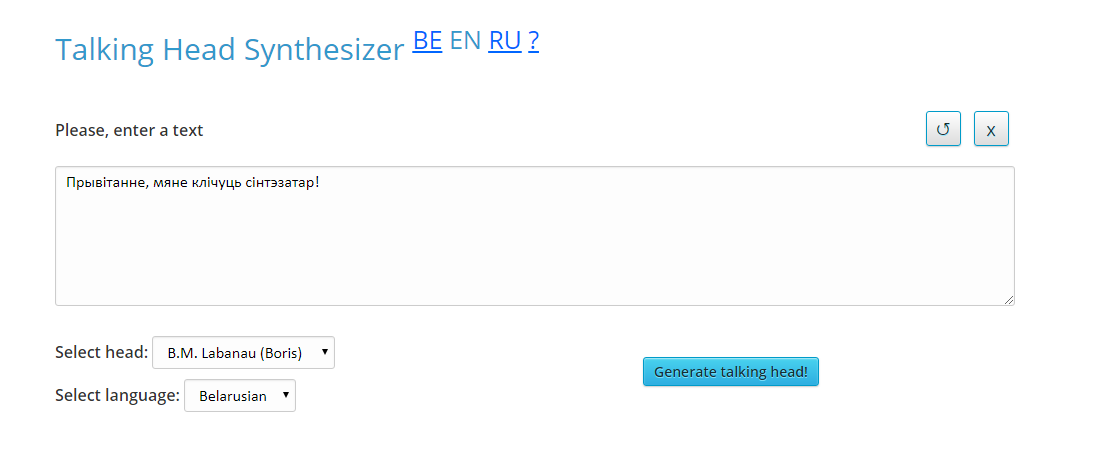
Figure 1. Graphical interface of the service «Talking Head Synthesizer»
The interface contains the following areas:
- electronic text entry field;
- the choice of «talking head»;
- the button «Get talking head!», which starts the generation of the «talking head» and allows you to get the final video file.
User script for working with the service
- Enter in the text box an electronic text for visualization.
- In the drop-down menu «Select head» select «talking head».
- Click the «Get talking head!» button to get the final video file.
- Click the play button and view the result (Figure 2).
- If you need to save the result to your computer, you need to click on «download video» and / or «download audio», after which the final file will be downloaded in * .mp4 format (video with synthesized speech) *.wav (only synthesized speech).

Figure 2. «Talking Head Synthesizer» results example
Access to the service via the API
To access the service «Talking Head Synthesizer» via the API, you should send an AJAX-request (type: POST) to the address https://corpus.by/TalkingHeadSynthesizer/api.php. With an input array data the following parameters are passed:
- text — arbitrary input text.
- selector — talking head; takes values “male1”, “male2”, “male3” and “female1”.
- selector_language — input text language; takes values “be” and “ru”.
Example of AJAX-request:
$.ajax({
type: “POST”,
url: “https://corpus.by/TalkingHeadSynthesizer/api.php”,
data:{
“text”: “Груша цвіла апошні год.”,
“selector”: “male1”,
“selector_language”: “be”
},
success: function(msg){ },
error: function() { }
});
The server returns a JSON-array with the following parameters:
- text — input text.
- VideoLink — ULR, where resulting video is saved.
- AudioLink — ULR, where resulting audio is saved.
For example, the following reply will be formed on the above listed AJAX-request:
[
{
“text”: “Груша цвіла апошні год.”,
“VideoLink”: “https://corpus.by/_cache/TalkingHeadSynthesizer/video/2019-09-03_17-18-50_80-94-171-2_403_output.mp4”,
“AudioLink”: “https://corpus.by/_cache/TalkingHeadSynthesizer/wav/2019-09-03_17-18-50_80-94-171-2_403.wav”
}
]
Links to sources
Service page: https://corpus.by/TalkingHeadSynthesizer/?lang=en
Service «Text-to-speech synthesizer»: https://corpus.by/TextToSpeechSynthesizer/?lang=en
Cross references
- Лобанов, Б.М. Ретроспективный обзор исследований и разработок лаборатории распознавания и синтеза речи / Б.М. Лобанов // Автоматическое распознавание и синтез речи: сб. науч. тр. – Минск: ИТК НАН Беларуси, 2000. – С. 6-24.
- Гецэвіч, Ю.С. Праектаванне натуральна-моўных інтэрфейсаў для даведкавых сістэм / Ю.С. Гецэвіч, У.А. Жытко, С.А. Гецэвіч, Л.І. Кайгародава, К.А. Нікалаенка // Інфарматыка. – 2019. – Т. 16, № 3. – С. 37-47.