The “Spell Checker” service is designed to check words spelling. The service receives an electronic text that requires verification. By pressing the “Check it!” button the service compares text words with words in attached dictionaries. The service qualifies the words of the input text found in at least one of the dictionaries as spelled correctly and discards them. Words that are not found in dictionaries are qualified by the service as spelled incorrectly. The service displays them in a list in alphabetical order.
Basic terms and concepts
Orthography, spelling – the uniformity of words and grammatical forms in writing. Also, a set of rules providing this uniformity.
Proofreading – verification of the written text before sending it to the customer, publication or other way of use.
Dictionary (“brute-force”) search – a way to solve applied linguistic tasks, which belongs to the class of search methods for solutions by exhausting all possible variants. The complexity of exhaustive search in the general case depends on the number of all possible variants of solutions to the task.
Practical value
The service has a wide range of application methods and is extremely relevant. Currently the quality of the texts proofreading is an integral requirement for many fields of activity, a requirement for communication between people and institutions. In addition, spelling-correct electronic text is a requirement necessary for the proper functioning of computer systems of human-machine communications. The relevance of the development of the service is also determined by the complicated access to the processing tools for Belarusian-language texts. There is an amateur spelling checker package for MS Office Word, but it requires special search, download and installation [1]. The proofreading of electronic text by machine tools always remains relevant, since manual checking of texts by the user almost guaranteedly means skipping mistakes.
Service features
The service checks texts by comparing the text words with the words in the dictionary database. This dictionary database currently includes the dictionaries listed in table 1.
Table 1 – Characteristics of the dictionaries used by the “Spell Checker” service
|
Included by default |
Dictionary name |
Comments |
Dictionary language |
|
Yes |
SBM1987 |
According to the publication “Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987” | Belarusian |
|
Yes |
SBM2008 |
Belarusian language dictionary on example of Belarusian Grammar Database (bnkorpus.info). Authors: Symon Kakora, Aleś Bułojčyk, Uladź Koščanka. На ўмовах ліцэнзіі CC BY-SA 4.0 | Belarusian |
|
Yes |
SBM2012initial |
Basic forms according to the publication “Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. – Мінск : Беларус. навука, 2012” | Belarusian |
|
Yes |
NOUN2013 |
According to the publication “Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013” | Belarusian |
|
Yes |
ADJECTIVE2013 |
According to the publication “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013” | Belarusian |
|
Yes |
NUMERAL2013 |
According to the publication “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013” | Belarusian |
|
Yes |
PRONOUN2013 |
According to the publication “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013” | Belarusian |
|
Yes |
VERB2013 |
According to the publication “Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013” | Belarusian |
|
Yes |
ADVERB2013 |
According to the publication “Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013” | Belarusian |
|
Yes |
ZALIZNIAK |
According to the publication “Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. — Москва : Русский язык, 1980. — 880 c.” | Russian |
|
Yes |
CMU |
According to “Carnegie Mellon University Pronouncing Dictionary” | English |
|
No |
TTS |
New words for the “Text-To-Speech Synthesizer” service | Belarusian |
|
No |
S2016_01 |
The vocabulary is available by the link | Belarusian |
|
No |
S2016_02 |
The vocabulary is available by the link | Russian |
|
Yes |
S2016_03 |
The vocabulary is available by the link | Belarusian |
|
No |
S2017_04 |
The vocabulary is available by the link | Belarusian |
|
No |
S2017_05 |
The vocabulary is available by the link | Belarusian |
|
No |
*UWP_BE |
Belarusian words from the dictionary available by the link | Belarusian |
|
No |
*UWP_RU |
Russian words from the dictionary available by the link | Russian |
Some of the listed dictionaries (marked by *) are in the process of constant replenishment and development.
Among several currently existing Belarusian services of spell checking, only the “Spell Checker” service was created on the basis of preliminary serious scientific work, since it was developed as one of the stages of preliminary processing and normalization of text for a speech synthesizer.
It is worth noting that this service covers the orthographic section of the spelling, but not grammar, syntax or punctuation. The correctness of word matching and punctuation is outside the competence of the service and remains for the user or other services that are also involved in the methodology of large electronic texts proofreading using the platform www.corpus.by services. The work of the service and the methodology have been tested in numerous projects of the Speech Recognition and Synthesis Laboratory and are in a state of constant development and improvement.
The “Spell Checker” service can process both small texts (from one or several words) and large texts. For example, the service successfully checked the spelling of legislative codes and literary works with a volume of about 470 000 characters with spaces.
Service operation algorithm
Algorithm input data:
- User text input, UText;
- User input of words to ignore, IgnoreList;
- The maximum number of contexts, ContextsMax;
- The set of user-selected dictionaries, Dictionaries;
- The set of letters that a word can consist of, AllLetters;
- The set of Latin characters in upper and lower case, LettersLat, LettersLat ⊂ AllLetters;
- The set of all characters of the Belarusian alphabet in upper and lower case, LettersBel, LettersBel ⊂ AllLetters;
- The set of all characters of the Russian alphabet in upper and lower case, LettersRus, LettersRus ⊂ AllLetters, LettersRus ⋂ LettersBel;
- The set of all letters of the Belarusian alphabet denoting vowels in upper and lower case, VovelsBel, VovelsBel ⊂ LettersBel;
- The set of all letters of the Belarusian alphabet denoting consonants in upper and lower case, ConsonantsBel, ConsonantsBel ⊂ LettersBel
The beginning of the algorithm.
Step 1.1. Splitting of the user text UText into a subset of strings Lines by linefeed characters, splitting of subsets Lines into elements of Words; the element of Words is a combination of characters from the beginning of the line to space, from space to space and from space to the end of the line, each Char character of which corresponds to the condition Char ∈ AllLetters. Counting the total number of elements of Words, recording the value to the variable WordsCount.
Step 1.2. Splitting a user exception list IgnoreList into words that make up the set IgnoreListWords.
Step 1.3. Formation of the final set Result, consisting of the following elements: a subset of data for words with both Cyrillic and Latin letters MixedWords, a subset of data for words that were not found in dictionaries UnknownTokens. Creating variables MixedWordsCount to store the number of elements of MixedWords and UnknownTokensCount to store the number of elements of UnknownTokens.
Step 2.0. Checking the word Words[A] (where A is the number of the next element of the set) for belonging to the set IgnoreListWords. If Words [A] ∈ IgnoreListWords, go to step 3.4, otherwise go to step 2.1.
Step 2.1. Checking the words Words[A] for belonging to one character system – Cyrillic or Latin. To do this, each character Char of the word Words[A] is sequentially checked for occurrence in the sets LettersLat, LettersBel and LettersRus. If all Char belong only to the LettersLat set or only to the LettersBel and LettersRus sets, go to step 3.1, otherwise perform steps 2.1.1 – 2.1.4.
Step 2.1.1. Counting the number of occurrences of Words[A] in the set Words, recording the value in a special variable Words[A].Count.
Step 2.1.2. The formation of Contexts[A] linked to Words[A] – a set of contexts of occurrences of Words[A], each element of which includes the maximum possible number B of elements of Words going before Words[A], and elements of Words coming after Words[A], where 0 ≤ B ≤ 3, B ∈ N. The number of elements Contexts[A] cannot exceed the value of ContextsMax; in case of exceeding, only those contexts that entered the set before reaching the limit will be included.
Step 2.1.3. Marking in Words[A] characters Char and groups of characters Char that do not belong to the dominant character system of the word – Cyrillic or Latin. The“dominant character system” is the system to which the first character or group of characters belongs before the sequence is interrupted by a foreign character. Recording the received “word with marked characters” to the variable WordWithMarkedChars.
Step 2.1.4. Formation of the four <Words[A], Words[A].Count, Contexts [A], WordWithMarkedChars>, writing the four to the MixedWords set, incrementing the MixedWordsCount.
Step 3.1. Normalization of Words[A] – cast into a form suitable for comparison with the data of dictionaries selected by the user:
1) reduction of all characters of the word in lower case;
2) replacement of all possible apostrophe characters («’», «ʼ», «’», «‘», «′») with the only correct character «’»;
3) removal of accents;
4) if the first letter of the word is «ў», replace it with the letter «у».
Step 3.2. Checking with a regular expression whether Words[A] contains a pair of characters <Char + «у»>, where Char ∈ VovelsBel, and <Char + «ў»>, where Char ∈ ConsonantsBel. If there are such pairs, perform steps 3.2.1 – 3.2.4, otherwise go to step 3.3.
Step 3.2.1. Counting the number of occurrences of Words[A] in the set Words, recording the value in a special variable Words[A].Count (similar to step 2.1.1).
Step 3.2.2. The formation of Contexts[A] linked to Words[A] – a set of contexts of occurrences of Words[A], each element of which includes the maximum possible number B of elements of Words going before Words[A], and elements of Words coming after Words[A], where 0 ≤ B ≤ 3, B ∈ N. The number of elements Contexts[A] cannot exceed the value of ContextsMax; in case of exceeding, only those contexts that entered the set before reaching the limit will be included (similar to step 2.1.2).
Step 3.2.3. Obtaining from Words[A] a word with a changed using of the letters «у» and «ў» by replacing all pairs of characters <Char+ «у»> with <Char + «ў»> (Char ∈ VovelsBel) and <Char + «ў»> with <Char + «у»> (Char ∈ ConsonantsBel). Recording the word to the variable RecommendedSpelling.
Step 3.2.4. Formation of the four <Words[A], Words[A].Count, Contexts[A], RecommendedSpelling>, writing the four to the set UnknownTokens, increment UnknownTokensCount.
Step 3.3. Searching for the equivalent of Words[A] among all the elements of the subsets that make up the set Dictionaries (in other words, searching in all dictionaries selected by the user). If Dictionaries = ∅ or Words[A] ∉ Dictionaries, complete steps 3.3.1 – 3.3.3. If Words[A] ∈ Dictionaries, go to step 3.4.
Step 3.3.1. Counting the number of occurrences of Words[A] in the set Words, recording the value in a special variable Words[A].Count (similar to step 2.1.1).
Step 3.3.2. The formation of Contexts[A] linked to Words[A] – a set of contexts of occurrences of Words[A], each element of which includes the maximum possible number B of elements of Words going before Words[A], and elements of Words coming after Words[A], where 0 ≤ B ≤ 3, B ∈ N. The number of elements Contexts[A] cannot exceed the value of ContextsMax; in case of exceeding, only those contexts that entered the set before reaching the limit will be included (similar to step 2.1.2).
Step 3.3.3. The formation of the triple <Words[A], Words[A].Count, Contexts[A]>, recording of the triple in the set UnknownTokens, incrementing UnknownTokensCount.
Step 3.4. If the value of A is less than the number of the last element of the set Words, increment A and go to step 2.0. If the last element of the set of Words is reached, go to step 4.
Step 4. Displaying subsets of the set Result and related data in the following order:
| WORDS WITH BOTH CYRILLIC AND LATIN LETTERS ({MixedWordsCount})
{MixedWords} MARK WORDS SPELLED CORRECTLY AND PRESS «RECHECK IT» ({UnknownTokensCount}) {UnknownTokens} UNIQUE WORD SPELLINGS: {WordsCount} |
Further steps of the algorithm are performed only by clicking the “Recheck it!” button.
Step 5.1 Removing from the set UnknownTokens elements marked by the user (with a corresponding decrease in the value of UnknownTokensCount) and adding deleted elements to the set UserMarkedWords ⊂ Result. Creating the variable UserMarkedWordsCount for saving the number of elements in the set UserMarkedWords.
Step 5.2 Clearing the output field. Displaying subsets of the set Result and related data in the following order:
| WORDS WITH BOTH CYRILLIC AND LATIN LETTERS ({MixedWordsCount})
{MixedWords} MARK WORDS SPELLED CORRECTLY AND PRESS «RECHECK IT» ({UnknownTokensCount}) {UnknownTokens} WORDS MARKED AS CORRECTLY SPELLED ({UserMarkedWordsCount }) {UserMarkedWords} UNIQUE WORD SPELLINGS: {WordsCount} |
The end of the algorithm.
User interface description
The user interface of the service is shown in Figure 1.
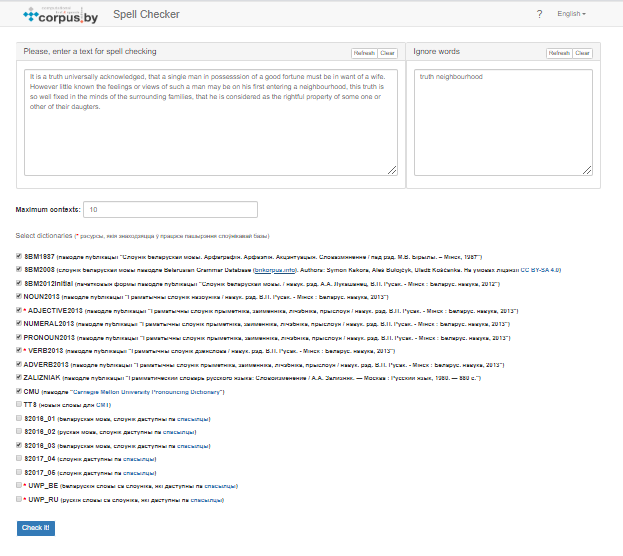
Figure 1 – The graphical interface of the service “Spell Checker”
The interface contains the following areas:
- field for electronic text input;
- field “Ignore words” – input field for words that should be ignored during checking;
- field “Maximum contexts” – to set the maximum number of contexts of unknown words;
- field for dictionary selection;
- the “Check it!” button, which starts processing and makes it possible to obtain results in the output field.
The text input field and the input field for words for ignoring are equipped with the “Refresh” (return data by default) and “Clear” (delete all data) buttons.
After processing the text by the service, the user receives the following lists of information in the output field:
- “Words with both Cyrillic and Latin letters (quantity)” – contains words that consist of both Cyrillic and Latin characters, which is most likely an erroneous spelling;
- “Mark words spelled correctly and press «Recheck it» (quantity)” – contains words unknown to the service, which probably contain an error (that is the main result of the service work that the user needs);
- “Unique word spellings: (quantity)” – the number of words in the input electronic text.
Also, after the service has processed the text, the “Recheck it!” button will appear under these lists. By clicking on this button, the words marked by the user as written without mistakes will be grouped into the “Words marked as correctly spelled” list.
In the right column of the summary table characters are selected that do not belong to the dominant character system of letters of which the word consists. The “dominant character system” is considered to be Cyrillic or Latin, depending on which of them a character or combination of characters that continue from the beginning of the word to a foreign character belongs to. Also in the right column there are suggestions for the correct spelling of words unknown to the service (at the moment – only for some cases of incorrect use of the letters “у” and “ў”).
User scenarios of work with the service
Note: for the best quality of checking the Belarusian-language text with the “Spell Checker” service, it is recommended to correct the text with the “Short U Spell Checker” service at first and read the help info before using this service.
Scenario 1. Checking of the entire arbitrary text
- Enter the text for checking in the input field.
- Make sure that the “Ignore words” field is blank. If there is any data in it, delete it manually or by clicking the “Clear” button.
- Enter the desired number of contexts in the field “Maximum contexts”.
- In the dictionary selection field, select the necessary dictionaries by checking or unchecking the box next to the dictionary, or leave the default marks.
- Click the “Check it!” button and get the result in the output field that appears below.
- View the list of “Words with both Cyrillic and Latin letters (number)”, if any, and, if necessary, make changes to the source text (for example, a .doc file or page), replacing incorrectly used Latin characters with Cyrillic.
- View the list “Mark words spelled correctly and press “Recheck it”, find the words with errors and make changes to the source text. Save the source text.
Scenario 2. Checking of the arbitrary text using a list of ignored words.
- Enter the text for checking in the input field.
- Enter words that do not need to be checked and will be ignored by the service in the “Ignore words” field. For example, these are specific words previously unknown to the service that are often used in highly specialized text: abbreviations, terminology, etc.
- Enter the desired number of contexts in the field “Maximum contexts”.
- In the dictionary selection field, select the necessary dictionaries by checking or unchecking the box next to the dictionary, or leave the default marks.
- Click the “Check it!” button and get the result in the output field that appears below.
- View the list of “Words with both Cyrillic and Latin letters (number)”, if any, and, if necessary, make changes to the source text (for example, a .doc file or page), replacing incorrectly used Latin characters with Cyrillic.
- View the list “Mark words spelled correctly and press “Recheck it”, find the words with errors and make changes to the source text.
- Save the source text.
A possible result of the service work is presented in Figure 2.
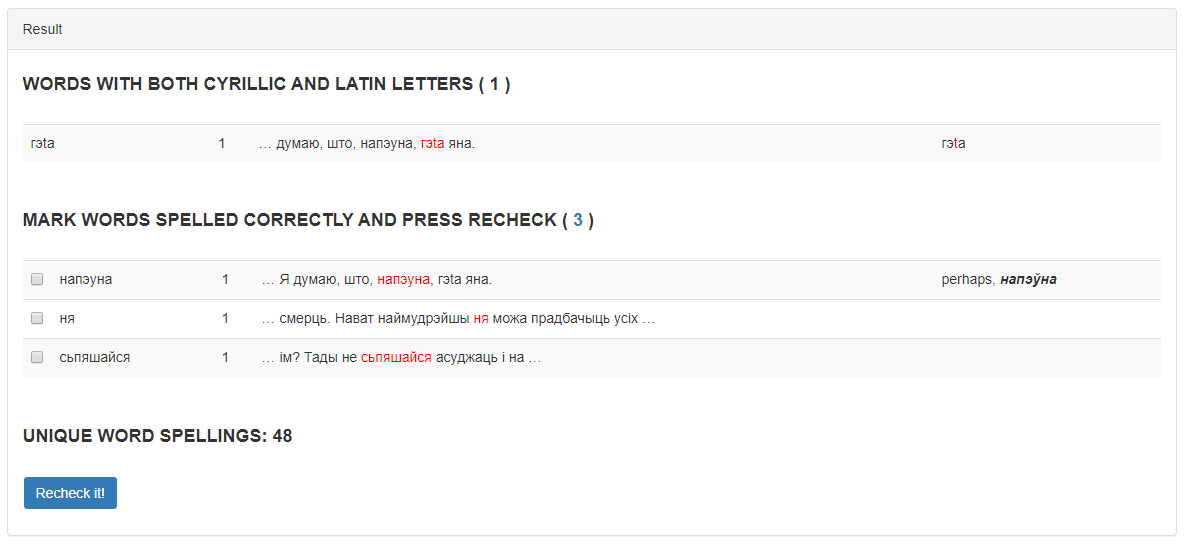
Figure 2 – The result of the service “Spell Checker” work
Access to the service via the API
To access the “Spell Checker” service via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/SpellChecker/api.php. The following parameters are passed through the data array:
- text — arbitrary input text.
- ignoreList — a list of words that don’t need to be checked.
- maxContexts — limit on the number of collecting contexts.
- Markers of dictionary using:
- sbm1987 — «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987»;
- sbm2008 — Belarusian language dictionary according to Belarusian Grammar Database (bnkorpus.info);
- sbm2012initial — «Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. — Мінск : Беларус. навука, 2012»;
- noun2013 — nouns according to the book «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adjective2013 — adjectives according to the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- numeral2013 — numerals according to the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- pronoun2013 — pronouns according to the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- verb2013 — verbs according to the book «Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adverb2013 — adverbs according to the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- zalizniak — «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. — Москва : Русский язык, 1980. — 880 c.»;
- cmu — «Carnegie Mellon University Pronouncing Dictionary»;
- tts — dictionary of the system of text-to-speech synthesis;
- S2016_01, S2016_02, S2016_03, S2017_04, S2017_05 — custom dictionaries;
- uwp_be — Belarusian words collected by the system «Unknown Words Processor»;
- uwp_ru — Russian words collected by the system «Unknown Words Processor».
Example of the AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/SpellChecker/api.php”,
data:{
“text”: “– Ён заслугоўвае сьмерці.
– Заслугоўвае! Мяркую, гэта так. Многія з тых, хто жыве, заслугоўваюць сьмерці. Некаторыя ж з памерлых заслугоўваюць жыцьця. Ці можаш ты вярнуць яго ім? Тады не сьпяшайся асуджаць і на сьмерць. Нават наймудрэйшы ня можа прадбачыць усіх наступстваў. (Дж.Р.Р. Толкін «Уладар Пярсьцёнкаў»)”,
“ignoreList”: “Дж Р Толкін”,
“maxContexts”: 10,
“sbm1987”: 1,
“sbm2008”: 1,
“sbm2012initial”: 1,
“noun2013”: 1
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with input text (text parameter), a list of words missing in the dictionary (result parameter) and an extended result table (output parameter). For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “Груша цвіла апошні грод.”,
“result”: “жыцьця
ня
пярсьцёнкаў
сьмерці
сьмерць
сьпяшайся”,
“output”: “<h2 class=”sub-caption-smaller”><b>ПАЗНАЧЦЕ СЛОВЫ БЕЗ ПАМЫЛАК І КЛІКНІЦЕ “ПЕРАПРАВЕРЫЦЬ!” ( <a href=”https://corpus.by/showCache.php?s=SpellChecker&t=out&f=2019-09-03_17-03-08_80-94-171-2_255_labeled_unknown.txt”>6</a> )</b></h2><br><table id=”misspellingTableId” class=”pale” width=”100%”><tbody><tr><td width=”2%”><input type=”checkbox” name=”token_0_status” value=”1″></td><td width=”13%”>жыцьця</td><td width=”5%” align=”center”>1</td><td width=”60%”>… з памерлых заслугоўваюць <font color=”red”>жыцьця</font>. Ці можаш ты … </td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_1_status” value=”1″></td><td width=”13%”>ня</td><td width=”5%” align=”center”>1</td><td width=”60%”>… сьмерць. Нават наймудрэйшы <font color=”red”>ня</font> можа прадбачыць усіх … </td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_2_status” value=”1″></td><td width=”13%”>пярсьцёнкаў</td><td width=”5%” align=”center”>1</td><td width=”60%”>… Р. Толкін «Уладар <font color=”red”>Пярсьцёнкаў</font>»)</td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_3_status” value=”1″></td><td width=”13%”>сьмерці</td><td width=”5%” align=”center”>2</td><td width=”60%”>– Ён заслугоўвае <font color=”red”>сьмерці</font>. – Заслугоўвае! Мяркую, гэта … <hr size=”1″ style=”opacity:0.2; margin: 1px 0px;”>… хто жыве, заслугоўваюць <font color=”red”>сьмерці</font>. Некаторыя ж з … </td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_4_status” value=”1″></td><td width=”13%”>сьмерць</td><td width=”5%” align=”center”>1</td><td width=”60%”>… асуджаць і на <font color=”red”>сьмерць</font>. Нават наймудрэйшы ня … </td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_5_status” value=”1″></td><td width=”13%”>сьпяшайся</td><td width=”5%” align=”center”>1</td><td width=”60%”>… ім? Тады не <font color=”red”>сьпяшайся</font> асуджаць і на … </td><td width=”20%”></td></tr></tbody></table><br><h2 class=”sub-caption-smaller”><b>ЗНОЙДЗЕНА ЎНІКАЛЬНЫХ НАПІСАННЯЎ СЛОЎ: 46</b></h2><br><button type=”button” id=”RecheckButtonId” name=”RecheckButton” class=”blue-button”>Пераправерыць!</button>”
}
]
Source references
Service page: http://corpus.by/SpellChecker/?lang=be
“Short U Spell Checker” service page: http://corpus.by/ShortUSpellChecker/?lang=be
“Text–To–Speech Synthesizer” service page: http://corpus.by/TextToSpeechSynthesizer/?lang=be
Cross references
- Праверка арфаграфіі // Беларускі N-корпус [Электронны рэсурс]. — 2017. Рэжым доступу : http://bnkorpus.info/download.html. — Дата доступу : 07.03.2017.
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Drahun, A. Semi-Automatic Proofreading of Belarusian and English texts / A. Drahun, Yu. Hetsevich, A. Bakunovich, Dz. Dzenisiuk, J. Shynkevich // International Conference NooJ 2019: Book of Abstracts. – Hammamet, Tunisia, 2019.
- Станіславенка, Г.Р. Рэдагаванне электронных масіваў тэкстаў на беларускай мове з выкарыстаннем камп’ютарна-лінгвістычных сэрвісаў платформы www.corpus.by / Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 262-267.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.