The service «Character frequency counter» provides statistical and reference information about the characters in the text, which allows to identify and correct their erroneous use. The service receives an arbitrary electronic text or a sequence of characters. The service calculates the total number of characters of the input text and the number of unique characters in the text. The output for each unique character displays information:
- code according to the Unicode standard;
- name (for characters that are presented in the database);
- character usage frequency:
- absolute;
- relative;
- the context of use encountered by the service for the first time.
The total data is displayed to the user in the form of a table.
Basic terms and concepts
The total number of characters – the number of all character usage in the text.
The number of unique characters – the number of all characters in the text (used 1 or more times).
Absolute character usage frequency (FreqAbs) – the number of cases of using a certain character in the text.
Relative character using frequency (FreqRel) – the proportion of the number of cases of using a certain symbol relative to all character usages of the text. It is calculated by the formula:
FreqRel = FreqAbs / ChUseAll * 100% ,
where ChUseAll is the total number of character uses.
Unicode – a character encoding standard that includes characters from almost all the written languages of the world. Currently, this standard is the most common on the Internet.
Practical value
Service is used to solve numerous problems.
For example, the processing of text by this service is one of the steps in the methodic of proofreading large-sized text, where the service helps to identify the misuse of characters in the text. So, the user must view the final list of characters and check the following points in it:
- whether the number of brackets is the same, for example, /(/, /)/, /[/, /]/;
- whether the number of double quotes is the same /“/, /”/; /«/, /»/; /„/, /“/;
- whether the symbol /”/ is present in the text, which is actually a symbol of second and not the quotation mark and should be replaced with one of the quotation marks if used incorrectly;
- whether the text contains the symbol /’/, which is called an apostrophe by the Unicode standard, but is not used as an apostrophe in the Belarusian press and should be replaced by the symbol /’/ (Alt + 0146);
- whether the hyphen /-/, short /–/, long /—/ dashes are used correctly;
- whether Latin letters are present in the Cyrillic text.
So, for example, if the number of left and right brackets does not match, then most likely there are punctuation errors in the text. According to the found erroneous use of characters, it is necessary to make changes to the text, it is advisable to re-check the corrected text with the service, and proceed to the next stage of the proofreading (see the methodic).
Service features
– Up to date, the database of characters names covers all the characters that appear simultaneously in the Unicode and ASCII tables, that is, the volume of the database is 256 entries (no name was entered for the symbol ). If the symbol name is not found by the service in the database, the «–» symbol will be displayed as a response to the user.
– The service determines the frequency of only those characters that are found in the Unicode table. The behavior of the service when trying to process other characters has not been investigated.
– The contexts of the use of symbols are formed in the following way: the initial set of symbols is sequentially divided into subsets, each of which consists of a maximum of 28 characters. It means that the length of the last context will be equal to the remainder of dividing the total length of user input by 28.
Service operation algorithm
Algorithm input data:
- User text input, UText;
- User input in the «Search only the following characters» field, SearchOnly;
- A set of characters of the Unicode table, Unicode;
- A set of characters of the ASCII table, ASCII ⊂ Unicode;
- A set of ASCIINames character names.
The beginning of the algorithm.
Step 1.1. The formation of subsets Line according to the following conditions: Lines ⊂ UText, the minimum volume of Line = 1 character usage (ChUse), the standard (and maximum) volume of Line = 28 ChUse. Subsets Line are formed by gradually separating the maximum Line volume from UText: for example, in case of a length of UText = 116 ChUse, four subsets of 28 ChUse length and one subset of 4 ChUse length will be formed.
Step 1.2. Formation of a set of character usage CharsUse according to the user text UText. Writing the quantitative volume value of the CharsUse set to the ChUseAll variable.
Step 1.3. Formation of a set СhForSearch, consisting of unique characters of user input SearchOnly;
Step 1.4. Formation of CharsUniq – a subset of associations of unique symbols of the CharsUse set, in which the key is each subsequent unique symbol <|CharUniq [X]|>, and the value is the absolute frequency of its use [ChFreqAbs[X]]. The absolute frequency of use of ChFreqAbs[X] is calculated by incrementing with each new meeting of CharUniq[X] in CharsUse.
Step 1.5. If ChForSearch ≠ ∅, the correction of the CharUniq set occurs – removal of all CharUniq[X] ∉ СhForSearch from it. Writing the quantitative value of the volume of the CharUniq set to the UniqChars variable.
Step 2.1. The formation of triples <CharQniq[X], Line[X], ChFreqAbs[X]>, where Line[X] is the first in order subset of Line in which CharUniq[X] is used.
Step 2.2. Calculation of the relative frequency of use of FreqRel[X] for each character according to the formula FreqRel[X] = ChFreqAbs[X] / ChUseAll * 100%.
Step 2.3. Definition of Code[X] – CharQniq[X] character codes, Code[X] ∈ Unicode.
Step 2.4. Forming Name – a set of CharQniq[X] character names. If Code[X] ∈ ASCII and Code[X] ≠ , the NamesASCII[X] name is written in Name[X] in the service interface language, if Code[X] ∉ ASCII or Code[X] = , in Name[ X] the symbol «–» is written.
Step 3. Formation of the final table, each row of which is a six <CharUniq[X], Code[X], Name[X], ChFreqAbs[X], FreqRel[X], Line[X]>. Displaying the values of the variables ChUseAll, UniqChars and the summary table to the user.
The end of the algorithm.
User interface description
The graphical interface of the service is shown in Figure 1.
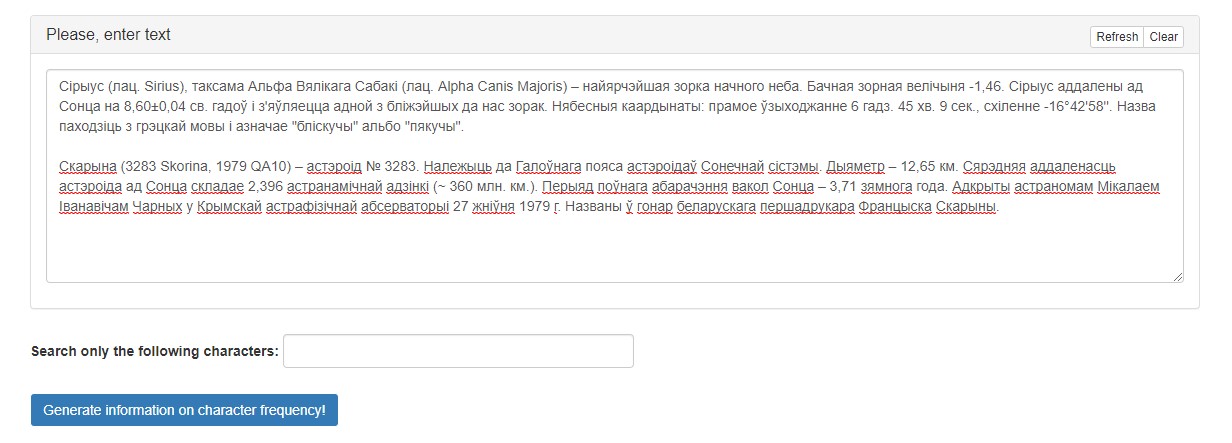
Figure 1. Interface of the service «Character Frequency Counter»
The interface contains the following areas:
- An electronic text input field equipped with the «Refresh» button (return default data) and «Clear» button (delete all data from the field);
- Input field «Search only the following characters»;
- The button «Generate information on character frequency!», which launches text processing and gives the opportunity to get results;
- The field for outputting summary data (appears after the first press of the button «Generate information on character frequency!»).
User scenarios of work with the service
Scenario 1. Obtaining information on all unique characters of the text (the scenario is described as a part of the text proofreading algorithm).
- Enter electronic text or a sequence of characters in the input field.
- Press the button «Generate information on character frequency!».
- If necessary, sort the data: click on the column heading by which you want to sort the list. When you click on the same heading again, the list is sorted in reverse order.
- Browse the list of characters found, looking for possible cases of their misuse, an unequal number of brackets, etc.
- Make changes to the source text.
- (Desirable) re-check the already corrected text with the service and save it.
Scenario 2. Getting information about certain characters of the text.
- Enter electronic text or a sequence of characters in the input field.
- Enter the search characters in the «Search only the following characters» entry field. Characters can be repeated, space is also considered a character.
- Press the button «Generate information on character frequency!».
- If necessary, sort the data: click on the column heading by which you want to sort the list. When you click on the same heading again, the list is sorted in reverse order.
An example of the final data for work by scenario 1 is presented in Figure 2.
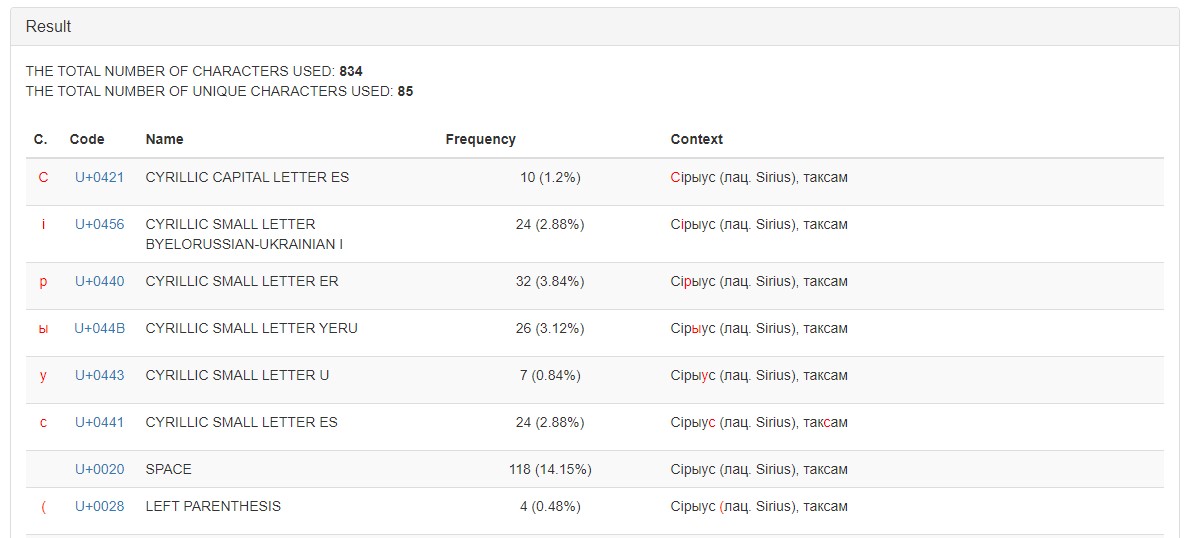
Figure 2. The results of text processing by the service «Character Frequency Counter»
An example of the final data sorted by the number of character uses is presented in Figure 3.
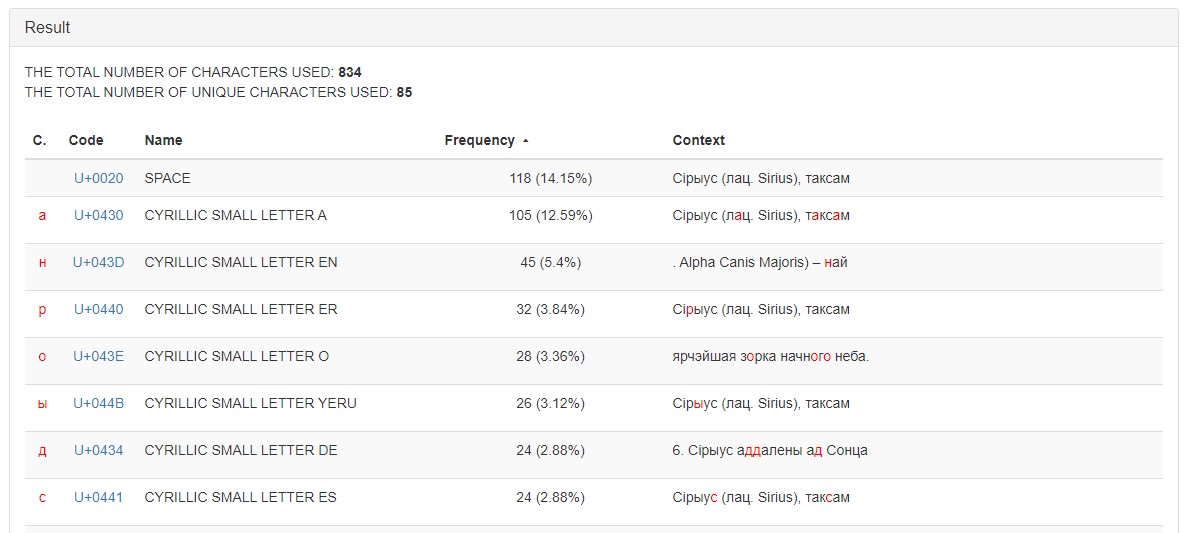
Figure 3. The results of text processing by the service «Character Frequency Counter», sorted by the number of uses of characters (from bigger to smaller)
Access to the service via the API
To access the service «Character Frequency Counter» via the API you need to send an AJAX request of the POST type to the address https://corpus.by/CharacterFrequencyCounter/api.php. The following parameters are passed through the data array:
- text – arbitrary input text.
Example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/CharacterFrequencyCounter/api.php”,
data:{
“text”: “Тэкст.”
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with input text (parameter text) and a summary table of the frequency of characters (parameter result). For example, according to the above AJAX request, the following response will be generated:
[
{
“text”: “Тэкст.”,
“result”: “THE TOTAL NUMBER OF CHARACTERS USED: <b>6</b><br>
THE TOTAL NUMBER OF UNIQUE CHARACTERS USED: <b>6</b><br>
<br>
<table class=”sort” align=”center” width=”100%”><thead><tr><td>C.</td><td>Code</td><td>Name</td><td colspan=”2″>Frequency</td><td>Context</td></tr></thead><tbody><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>Т</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/0422/”>U+0422</a></td>
<td width=”300″>CYRILLIC CAPITAL LETTER TE</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td><font color=”red”>Т</font>экст.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>э</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/044D/”>U+044D</a></td>
<td width=”300″>CYRILLIC SMALL LETTER E</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Т<font color=”red”>э</font>кст.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>к</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/043A/”>U+043A</a></td>
<td width=”300″>CYRILLIC SMALL LETTER KA</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Тэ<font color=”red”>к</font>ст.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>с</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/0441/”>U+0441</a></td>
<td width=”300″>CYRILLIC SMALL LETTER ES</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Тэк<font color=”red”>с</font>т.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>т</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/0442/”>U+0442</a></td>
<td width=”300″>CYRILLIC SMALL LETTER TE</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Тэкс<font color=”red”>т</font>.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>.</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/002E/”>U+002E</a></td>
<td width=”300″>FULL STOP</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Тэкст<font color=”red”>.</font></td>
</tr></tbody></table>”
}
]
References to sources
Service page: https://corpus.by/CharacterFrequencyCounter/?lang=be
Methodic for proofreading large-sized electronic text: https://ssrlab.by/5406
Unicode character table: https://unicode-table.com
Cross references
Перакрыжаваныя спасылкі
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Drahun, A. Semi-Automatic Proofreading of Belarusian and English texts / A. Drahun, Yu. Hetsevich, A. Bakunovich, Dz. Dzenisiuk, J. Shynkevich // International Conference NooJ 2019: Book of Abstracts. – Hammamet, Tunisia, 2019.
- Марчык, М.У. Вычытка тэксту вялікага памеру на беларускай мове / М.У. Марчык, С.І. Лысы, Ю.С. Гецэвіч // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы II Междунар. науч.-практ. конф., Минск, 1–2 марта 2018 г. / редкол. : О. Г. Прохоренко (отв. ред.) [и др.]. — Минск : Издательский центр БГУ, 2018. — C. 58-63.