The service “Word Frequency Counter” solves the task of obtaining statistics on the use of arbitrary symbolic sequences in electronic text. A special case of this task is the task of calculating the frequency of use of words in electronic text
Basic terms and concepts
Number of uses – the absolute quantitative value of occurrences of a given sequence of characters (words) in a particular set of word usage (text).
Frequency of use – the term of lexicostatistics intended to determine the relative quantitative indicator of occurrences of a given sequence of characters (words) in a particular set of word usage (text). The frequency of use Freqx is calculated by the formula
Freqx = Qx / Qall ,
where Qx is the number of uses of the word x, Qall is the total number of uses of the word. In most cases, the frequency of use is expressed as a percentage:
Freqx = Qx / Qall * 100% .
“Mass fraction” of use – a working term that means how huge physically the number of characters of all occurrences of a given sequence (word) from the total number of characters in the text. The “mass fraction” of the use MFracx is expressed as a percentage and is calculated by the formula
MFracx = (Symbx * Qx / Symball) * 100% ,
where Symbx is the number of characters that make up the word x, Qx is the number of uses of the word x, Symball is the total number of characters in the text.
Practical value
The service will be useful:
– for lexicographers involved in compiling frequency dictionaries;
– for linguists involved in determining the verbal framework of a particular language (words, knowing of which will be enough to understand most texts in a given language);
– for linguists involved in research in the field of linguistic typology based on an analysis of written sources;
– for specialists involved in proofreading texts (finding erroneous uses of words according to the pattern of erroneous use);
– for the needs of stylistic proofreading of texts – determination of the use of a particular word too often (and the subsequent manual replacement of it with synonymous) and the finding of “parasite words”.
Service Features
– The service allows to process texts in many natural and artificial symbolic languages (if the characters of the language alphabet are entered in a special field);
– In the case of working with the Belarusian language, the service defines the letters “у” and “ў” as ordinary separate characters, therefore, for example, the word “узвышша” in the contexts of “пад узвышшам” and “на ўзвышшы” will be defined as two separate word usage;
– The service does not recognize hyphens and symbols of the word break in the source text, accepting them as the same character. If the text editor from which the source text is taken does not automatically delete hyphens when copying, the user will have to manually delete word break symbols to obtain correct results;
– At the moment, the service determines only the absolute number of word usage.
Service operation algorithm
Algorithm input:
-
User text input, UText;
-
A set of ignored words, IgnWordsList;
-
A set of symbols that a word can consist of, AccSymbList;
-
A set of symbols that a word can consist of, but with which the word cannot start, AccNotStartSymbList;
-
A «Search only the following words» set, WordsForSearchList;
-
Number of contexts, QCont;
-
Case sensitivity, CaseSens;
-
An indication of whether to display the left and right contexts separately, LandRCont.
The beginning of the algorithm.
Step 1. Formation of the sets UText, IgnWordsList, AccSymbList, AccNotStartSymbList, WordsForSearchList. The set UText is divided into subsets of Paragraphs[1 … X] with the help of a regular expression that separates the text elements by the line feed symbol. These sets, in turn, are broken down into elements Word[1 … X]. The sets IgnWordsList, WordsForSearchList, if they are not empty, are divided into the elements IgnWord[1 … X] and SearchWord[1 … X] respectively, using a regular expression that separates the text elements by all indent symbols. These separatings are necessary for the software implementation of the algorithm only, therefore, the resulting subsets and elements (with the exception of elements Word [X]) will not be used in its further description.
Step 2.1. Counting the unique elements of the set UText and adjusting its composition. Elements that do not meet the following conditions are excluded from the set: Word [X] ∈ AccSymbList (character-by-character verification), Word [X] ∈ WordsForSearchList (if WordsForSearchList = ∅, this condition is not checked), Word [X] [1] ∉ AccNotStartSymbList , Word [X] ∉ IgnWordsList. Moreover, if any element of the set of WordsForSearchList ∉ UText, it will not be searched.
Step 2.2. If the condition CaseSens = false, all UText elements are reduced to lower case and the same elements are identified, then transition to step 2.3 occurs. If the condition CaseSens = true, a simple transition to step 2.3 occurs.
Step 2.3. Counting the number of identical elements Q[Word[X]] of the set UText and generating, for each such element, the set of contexts Contexts, Contexts = {LContexts, RContexts} in case of LandRCont = true, Contexts = {SingCont} in case of LandRCont = false. Moreover, if LandRCont = true, the formation of left and right contexts for each occurrence of each UText element is performed, if LandRCont = false, uniform contexts are formed for each occurrence of each UText element.
Step 3. Output the results. If LandRCont = true, the results are displayed on the screen in the form of a table, each row of which consists of fours <Q[Word[X]], LContexts[X], Word[X], RContexts[X]>; if LandRCont = false, an output consisting of triples <Q[Word [X]], Word[X], SingCont[X]> is produced. Moreover, for each element Word[X] only the QCont of the first elements of the set Contexts will be displayed.
The end of the algorithm.
User Interface Description
To obtain the necessary statistics, the user has the opportunity to enter arbitrary text in the “Please enter a text” field (the number “1” in Figure 1) and specify (adjust) the contents of the four sets to configure the service for a specific task.
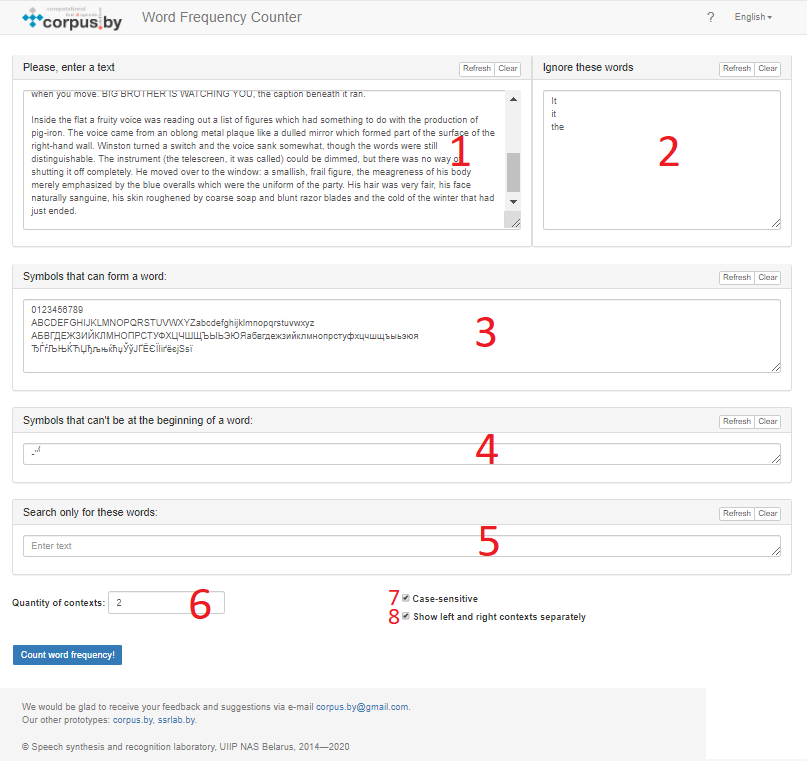
Figure 1 – The user interface of the service “Word Frequency Counter”
The first set is the sequences of symbols (words) that will be ignored by the service during the preparation of statistics (field “Ignore these words”, the number “2” in Figure 1).
The second set is the symbols that can form a word. Here the user can place the alphabet or a set of characters that will be used to recognize words in the text (the field “Symbols that can form a word”, the number “3” in Figure 1).
By default, in the field “Symbols that can form a word” all alphabetic characters of the encoding “Windows-1251” and numeric characters are placed:
0123456789
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюя
ЂЃѓЉЊЌЋЏђљњќћџЎўЈҐЁЄЇІіґёєјЅѕї
Important: if the sequence “symbols from space to space” contains around itself symbols that are not in the second set, if you specify a positive number of contexts, they will be displayed from the side of their placement. If the specified sequence contains symbols that are not in the second set within it, they will be perceived by the system as separators of the sequence.
The third set is the symbols that can form a word, but can’t be at the beginning of a word. By default, these are symbols of primary and partial accent, an apostrophe and a hyphen (Field “Symbols that can form a word, but can’t be at the beginning of a word”, the number “4” in Figure 1).
Important: when processing this set, the algorithm is case-sensitive.
The fourth set is a list containing words by which (and only by which) the user wants to get statistics (field “Search only for these words”, the number “5” in Figure 1).
If you leave this field empty, the service will display statistics for all words that appear in the text, given into account the data of sets 1, 2 and 3.
Important: The first set (“Ignore these words”) takes precedence over the fourth. This means that if a word is simultaneously entered in the first and fourth sets, it will be ignored by the service.
The user can receive a certain number of contexts for each of the found symbol sequences by indicating in the “Quantity of contexts” field (the number “6” in Figure 1) a positive integer number (any other data will be perceived by the service as the number “0”). In addition, the user has the following possibilities:
– indicate whether it is necessary to take into account the case of letters that make up the words of the input text, ignored words, and words defined for the search when calculating statistics (option “Case-sensitive”, the number “7” in Figure 1)
– specify the format for the output of the final data (option “Show left and right contexts separately”, the number “8” in Figure 1). The context includes up to three words before and up to three words after the found word and consists of words placed from the beginning to the end of each line of text (the line boundary is determined by the line break character invisible to the user).
Fields for entering the main data are equipped with the buttons “Refresh” (return the field data by default) and “Clear” (delete all data). The summary table is equipped with a “Copy” button for copying data in text format. Also, the table can be sorted by any of its columns.
User work with the service scenario
Scenario 1. Getting statistics for all words in the input text
1. Enter any text from the keyboard or copy it from the clipboard into the text input field.
2. Clear the data field “Ignore these words”. The fields “Symbols that can form a word” and “Symbols that can form a word, but can’t be at the beginning of a word” should be remained unchanged, the field “Search only for these words” should be left blank.
3. Indicate the required quantity of contexts in the “Quantity of contexts” field.
4. Determine whether it is necessary to match case and display the left and right contexts separately using the appropriate options.
5. Press the button “Count word frequency!” and get statistics.
The results will look similar to those shown in Figures 2 and 3.
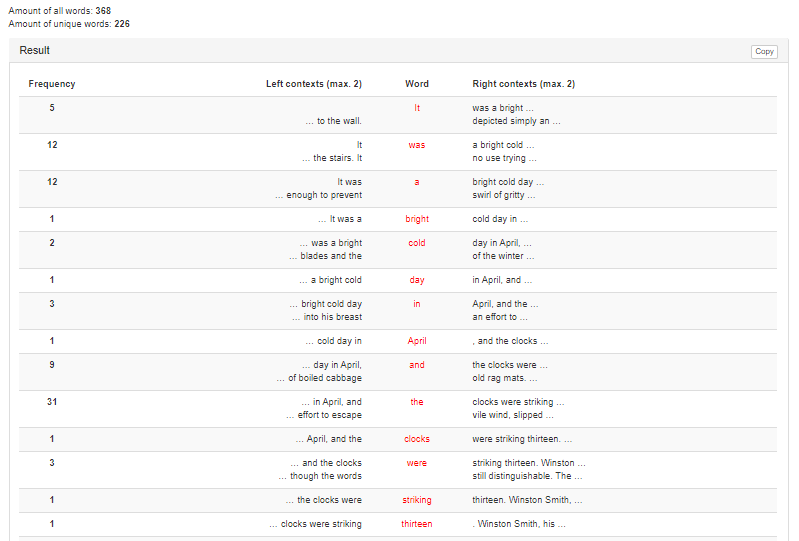
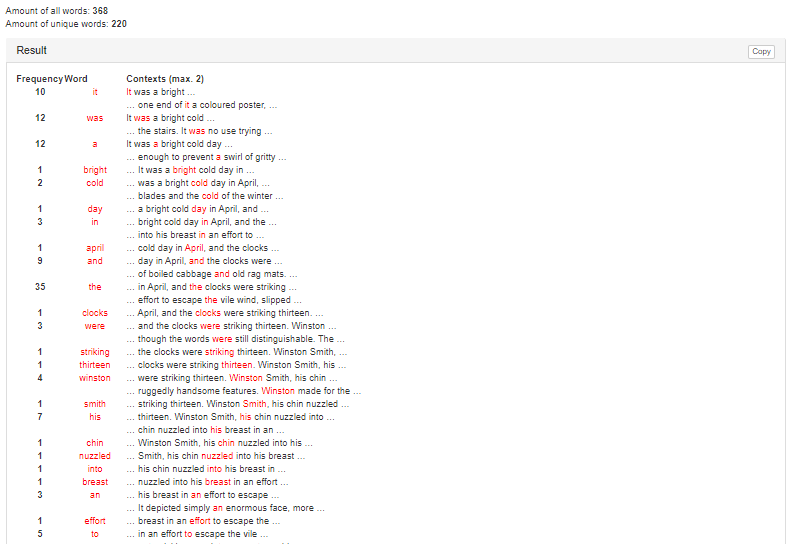
Figures 2, 3 – Getting statistics for all words in the input text
Scenario 2. Getting statistics about necessary words in the input text
1. Enter any text from the keyboard or copy it from the clipboard into the text input field.
2. Fill in the “Ignore these words” field (if necessary).
3. Change the content of the fields “Symbols that can form a word” and “Symbols that can form a word, but can’t be at the beginning of a word” (if necessary).
4. Set the required words for the search using the “Search only for these words” field.
5. Indicate the required quantity of contexts in the “Quantity of contexts” field.
6. Determine whether it is necessary to match case and display left and right contexts separately using the appropriate options.
7. Press the button “Count word frequency!” and get statistics.
An example of filling of the fields and defining options is presented in Figure 4, the result of the service work with similar input data is shown in Figure 5.
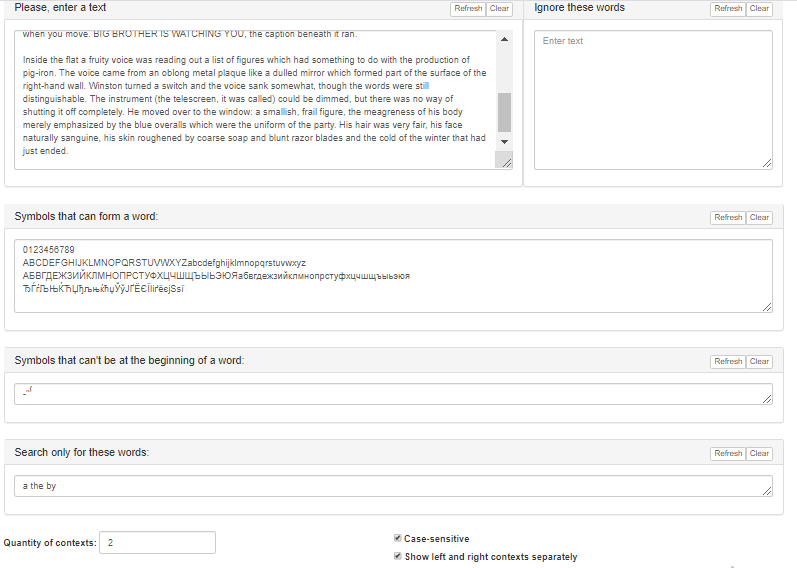
Figure 4 – Getting statistics on necessary words of the input text – an example of the source data
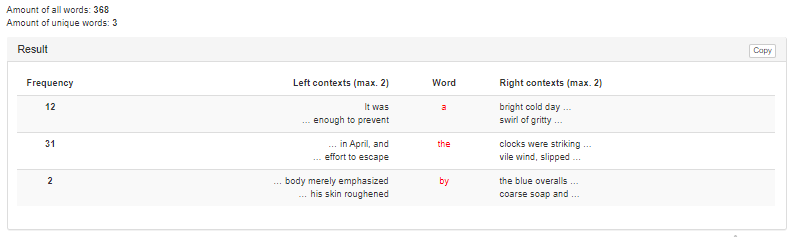
Figure 5 – Getting statistics on necessary words of the input text – an example of the result of the service work
Access to the service via API
To access the service “Word Frequency Counter” via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/WordFrequencyCounter/api.php.
Elements of the input array data have the following parameters:
- text – arbitrary input text.
- stop_words – a list of stop words – words that should not be counted. Words are written through a space or line feed.
- words_to_count – a list of words to count. It is introduced when it is necessary to count specific words. Words are written through a space or line feed.
- symbols_of_words – a list of symbols that can form a word.
- symbols_in_words – a list of symbols that can form a word, can’t be at the beginning of a word.
- contextsMax – the maximum quantity of contexts. If the value is “0”, contexts are not output.
- caseSensitive – case sensitivity marker. With a value of “1”, the word frequency is counted case-sensitive, with a value of “0”, case-insensitive.
- contextSensitive – a marker for displaying the left and right contexts in separate columns to the left and right of the word. With a value of “1”, the left and right contexts are displayed in separate columns to the left and right of the word, with a value of “0”, the left and right contexts are displayed in the same column with the word.
Example of AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/WordFrequencyCounter/api.php”,
data:{
“text”: “Груша цвіла апошні год.”,
“stop_words”: “груша цвіла апошні”,
“words_to_count”: “”,
“symbols_of_words”: “0123456789\nABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz\nАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюя\nЂЃѓЉЊЌЋЏђљњќћџЎўЈҐЁЄЇІіґёєјЅѕї”,
“symbols_in_words”: “-‘’ʼ̀́”,
“contextsMax“: “2″,
“caseSensitive“: “1″,
“contextSensitive“: “1″
}
success: function(msg){ }
});
The server will return a JSON array with input text (text parameter), the number of words in the input text (wordsCnt parameter), the number of unique words in the input text (uniqueCnt parameter) and the resulting table (result parameter). For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “Груша цвіла апошні год.”,
“wordsCnt”: 4,
“uniqueCnt”: 1,
“result”: “<table class=”sort”><thead><tr><td>Частата</td><td>Левыя кантэксты (макс. 2)</td><td>Слова</td><td>Правыя кантэксты (макс. 2)</td></tr></thead><tbody><tr valign=”top”><td width=”100″ align=”center”><b>1</b></td><td align=”right”><br></td><td width=”150″ align=”center”><font color=”red”>Груша</font></td><td> цвіла апошні год.<br></td></tr></tbody></table>”
}
]
Service page – https://corpus.by/WordFrequencyCounter/?lang=be
Cross references
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Станіславенка, Г.Р. Рэдагаванне электронных масіваў тэкстаў на беларускай мове з выкарыстаннем камп’ютарна-лінгвістычных сэрвісаў платформы www.corpus.by / Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 262-267.
- Гецэвіч, Ю.С. Праектаванне інтэрнэт-сервісаў для працэсараў сінтэзатара маўлення па тэксце з магчымасцю прадстаўлення бясплатных электронных паслуг насельніцтву / Ю.С. Гецэвіч, С.І. Лысы // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2014) : доклады XIII Международной конференции (Минск, 20 ноября 2014 г.). – Минск : ОИПИ НАН Беларуси, 2014. — C. 265-269.