The «Short U Spell Checker» service is developed for quick checking of large electronic texts in the Belarusian language in order to find and correct one of the most common errors – errors in the using of the letters “у” and “ў”.
The service receives the text in Belarusian in the usual form. If the user clicks the «Check it!» button, the service will indicate two possible types of errors: firstly, if the letter “у” is written in the position where the letter “ў” should probably be; secondly, in the opposite case, if the letter “ў” is written where, probably, the letter “y” should be.
Basic terms and concepts
Ў – the non-syllable (short) У – the 22nd letter of the Belarusian alphabet. Belarusian Cyrillic is the only Slavic linguistic sign system in which this letter is used (with the exception of cases when the letter is used in Ukrainian linguistic literature). The sound [ў], denoted by the letter “ў“, alternates with the sounds [у] [в] and [л] depending on the place in the word and the origin of the word. More details – https://be.wikipedia.org/wiki/%D0%8E.
Practical value
– The service will be useful for solving issues of automation of proofreading and editing texts in Belarusian. For this reason, the service is included in the «Methodology for the proofreading of large electronic texts using Corpus.by services» (https://ssrlab.by/5406).
– Also the service will be useful to improve the quality of speech synthesis using automated systems. One of the important points in speech synthesis is that the input text should not have orthographic mistakes. Otherwise, obviously, the result of the speech synthesizer’s text processing will be an incorrect sound text that grates on ears.
Service Features
– In the process of searching for possible errors, the service not only determines whether the vowel or consonant is before «у», but also analyzes characters that are not letters, if the letter «у» is at the beginning of a word. These characters can have a direct impact on the writing of a word.
– Not all words of the Belarusian language obey the general rules for writing the letter «Ў». For this reason, the service provides the opportunity to use exceptions dictionary (can be attached by a special box) or a user list of exceptions. The service processes the text taking into accout these sets of words.
– There are special rules for writing abbreviations with the letter “у” in the Belarusian language. But since the service does not distinguish abbreviations from other words automatically, to obtain accurate results, the user is prompted to enter the abbreviations that appear in the text in the corresponding field.
– The service considers the following characters as punctuation marks: «,», «.», «:», «;», «!», «?», «–», «—», «(», «)». Symbols «[», «]», «{», «}», «_», «%», «№», «#», «^», «$», «@» and others are not punctuation marks for the processing algorithm of the service. A hyphen («-») is a punctuation mark (identified with a dash) only if it is surrounded by spaces on both sides.
Service operation algorithm
Algorithm input data:
-
User text input, UText;
-
The set of the characters of Arabic numerals, the main Cyrillic and Latin characters in upper and lower case, LettersAndNumbers;
-
The set of all the characters of the Belarusian alphabet in upper and lower case, LettersBel, LettersBel ⊂ LettersAndNumbers;
-
The set of all Cyrillic and Latin characters in upper case Uppercase, Uppercase ⊂ LettersAndNumbers;
-
The set of all Cyrillic and Latin characters in the lower case Lowercase, Lowercase ⊂ LettersAndNumbers;
-
The set of all letters of the Belarusian language denoting vowels in upper and lower case, Vovels, Vovels ⊂ LettersBel;
-
The set of all letters of the Belarusian language denoting consonants in upper and lower case, Consonants, Consonants ⊂ LettersBel;
-
The set of punctuation marks, PunctuationMarks;
-
Dictionary of exceptions, DicExceptions;
-
User list of exception words, UserExceptions;
-
Boolean variable responsible for using the exception dictionary, BoolDic;
-
User list of abbreviations, UserAbbreviations.
The beginning of the algorithm.
Step 1.1. Breakdown of UText into the set Lines according to the linefeed characters.
Step 1.2. Forming of the set of exceptions Exceptions. If BoolDic = true, Exceptions is generated from DicExceptions data, if BoolDic = false – from UserExceptions data.
Step 1.3. Forming of the set abbreviations Abbreviations from the user list of abbreviations UserAbbreviations. This set includes all abbreviations of UserAbbreviations in which each character Char ∈ LettersBel.
Step 1.4. Creation of ErrU and ErrUn sets for storing information about the erroneous use of the letters “у” (“У”) and “ў” (“Ў”), respectively, ErrU = ∅, ErrUn = ∅.
Step 2.1. Breakdown of the next element of the set Lines[Z] into a two-dimensional array of words with separators WordsAndSeparators using a regular expression. A “word with separator” is considered to be each new part of Lines[Z], consisting of many characters Char and corresponding to the following rule: the first Char ∈ LettersAndNumbers, the following Char ∈ LettersAndNumbers (there can be 0 or more), the final Char ∉ LettersAndNumbers (there can be 0 or more). Word and Separator are separate elements of the array.
Step 2.2. If Lines [Z] = ∅, increment Z and go to step 2.1.
Step 2.3. If Word [X] ∈ Exceptions, an increment of X and the transition to the new Word[X] occur. Otherwise, the set of contexts Contexts is being formed. Each element of the set Contexts is associated with the corresponding element of the set Chars (see Step 2.4.) and consists of Y pairs «Word – Separator» preceding this element and Y of the same pairs following the given element (0 ⩽ Y ⩽ 3, Y ∈ N).
Step 2.4. Dividing elements of WordsAndSeparators into the set of characters Chars, creating the LastLetter variable to store the Char that precedes the current Char, and the LastSeparator variable to store the character that separates the current verified set from the previous one. LastSeparator can be a punctuation mark, a space, and also attach to itself one or more Char ∉ LettersAndNumbers & PunctuationMarks.
Step 2.5. If Chars[A] = “у” or “У” and Word[X] ∉ Abbreviations and Word[X] ≠ “У”, perform steps 2.5.1 – 2.5.3, otherwise go to step 2.6.
Step 2.5.1. If A = 0, check the condition LastSeparator ∈ PunctuationMarks. If the condition is true, then increment A and go to step 2.5. If not, check the condition LastLetter ∈ Vovels. If this condition is true, then add to the set ErrUn the five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘«y» after the vowel «{LastLetter}» without a punctuation mark’ (hereinafter, the content of Comment may vary depending on the language of the user interface).
Step 2.5.2. If the element Chars[A-1] is specified and Chars[A-1] ∈ Vovels, check whether it is true that the element Chars[A + 1] is equal to the characters “м“, “М“, “с” and “С“, and is it also correct that A+2 make the value of the set Chars. If at least one of the above conditions is not fulfilled, then add to the set ErrUn a five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘«у» after the vowel «{LastLetter}»’.
Step 2.5.3. If the element Chars[A-1] is specified and is equal to the character «–» (hyphen), then check whether the element Chars[A-2] is specified, as whetrer the condition Chars[A-2] ∈ Vovels is true. If both conditions are filfulled, then add to the set ErrUn the five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘«у» after the vowel {LastLetter} and hyphen’.
Step 2.6 If Chars[A] = “ў”, perform steps 2.6.1. – 2.6.5. Otherwise, go to step 2.7.
Step 2.6.1. If A = 0, check the condition LastSeparator ∈ PunctuationMarks. If the condition is true, then add to the set ErrU the five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = «ў» cannot be used after a punctuation mark’. If not, check the LastLetter ∈ Consonants condition. If the condition is filfulled, then add to the set ErrU the five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘«ў» after the consonant «{LastLetter}» without a punctuation mark’.
Step 2.6.2. If the element Chars[A-1] is specified and Chars[A-1] ∈ Consonants, then add to the set ErrU the five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘«ў» after the consonant «{LastLetter}»’.
Step 2.6.3. If the element Chars[A-1] is specified and Chars[A-1] = «-» (hyphen), then check whether the element Chars[A-2] is specified and whether the condition Chars[A-2] ∈ Consonants is true. If yes, then add to the set ErrU five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘«ў» after the consonant «{LastLetter}» and a hyphen’.
Step 2.6.4. If the element Chars[A-1] is specified and Chars[A-1] = «М» or «м», and A+2 make the value of the set Chars, then add to the set ErrU the five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘borrowed word ending in «–ум»’.
Step 2.6.5. If the element Chars[A-1] is specified and Chars[A-1] = “С” or “с”, and A+2 make the value of the set Chars, then add to the set ErrU the five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘borrowed word ending in «–ус»’.
Step 2.7. If Chars[A] = “Ў”, and at least one element of the set Chars ∈ Lowercase, then add to the set ErrU the five <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, where Comment = ‘CAPITAL «Ў» IS ONLY ALLOWED IN A TEXT WHERE ALL WORDS ARE WRITTEN IN CAPITAL LETTERS’.
Step 2.8. If the last element of the set Chars is reached, zero out A and set a new value for the variable LastLetter = Chars[B], where B is the value of the set Chars, and make LastSeparator equal to the paired element of the current element Words of the WordsAndSeparators array. If the last element of the WordsAndSeparators array is reached, increment Z, zero out X and A, and go to step 2.1. If the last element of the set Chars is not reached, then increment A and go to step 2.5. If the last element of the set Lines is reached, then go to step 3.
Step 3. Consistently display the contents of the sets ErrUn and ErrU.
The end of the algorithm.
User interface description
The graphical interface of the service is shown in Figure 1.

Figure 1 – The graphical interface of the service «Short U Spell Checker»
The interface has the following areas:
-
Field for user text for verification input
-
Field «Exceptions» for user input of exceptions
-
Box «Exception Dictionary» (attaches an exception dictionary to the processing, which takes precedence over the content of the «Exceptions» field)
-
Field for entering abbreviations that may appear in the text
-
«Check it!» Button: by pressing this button the user receives the result of text processing by the service.
The field for text for checking input and the field for exceptions input are equipped with the «Refresh» button (return data by default) and the «Clear» button (delete all data).
User scenarios of work with the service
Scenario 1 Obtaining data about erroneous use of the letters «y» («У») and «ў» («Ў») (basing the algorithm on a user exceptions list)
1. Enter text from the keyboard or copy text from the clipboard into the corresponding input field.
2. Enter the list of exceptions in the «Exceptions» field or complete/reduce the list proposed by default.
3. Verify that the «Exception Dictionary» box is unchecked (if not, uncheck it).
4. If necessary, edit the content of the field «Abbreviations in the text».
5. Click the «Check it!» button and get the results.
Scenario 2. Obtaining data about erroneous use of the letters «y» («У») and «ў» («Ў») (basing the algorithm on the dictionary of exceptions)
1. Enter text from the keyboard or copy text from the clipboard into the corresponding input field.
2. Verify that the «Exception Dictionary» box is checked (if not, check it).
3. If necessary, edit the content of the field «Abbreviations in the text».
4. Click the «Check it!» button and get the results.
A possible result of the service work is presented in Figure 2.
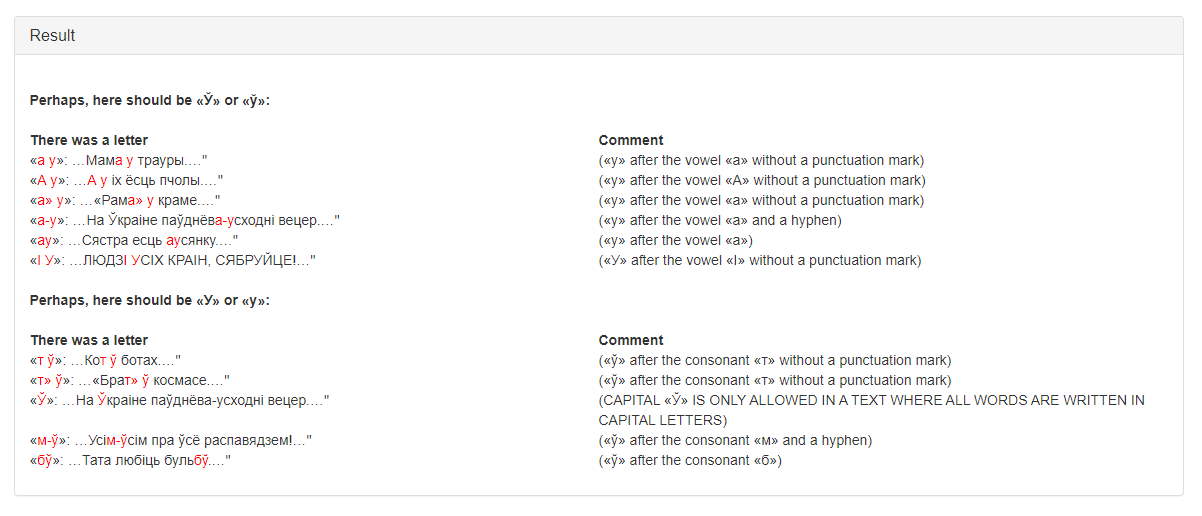
Figure 2 – the result of the service «Short U Spell Checker» work
Access to the service via the API
To access the «Short U Spell Checker» service via the API, you need to send an AJAX request of the POST type to the address https://corpus.by/ShortUSpellChecker/api.php. The following parameters are passed through the data array:
- inputText – an arbitrary input text in Belarusian.
- exceptions – a list of exceptions.
- abbreviations – a list of abbreviations.
Example of the AJAX request:
$.ajax({
type: “POST”,
url: “https://corpus.by/ShortUSpellChecker/api.php”,
data:{
“inputText“: “Кот ў ботах.
На Ўкраіне паўднёва-усходні вецер.
Тата любіць бульбў.”,
“exceptions“: “авіяшоу акварыум”,
“abbreviations“: “УНР УДК“
},
success: function(msg){ },
error: function() { }
});
The server will return a JSON array with input text (parameter text), a table of cases of «ў» misuse (parameter res_unc) and a table of cases of «у» misuse (parameter res_uc). For example, using the above AJAX request, the following response will be generated:
[
{
“text”: “Кот ў ботах.
На Ўкраіне паўднёва–усходні вецер.
Тата любіць бульбў.”,
“res_unc“: “<table class=”pale” width=”100%”><tbody><tr><td width=”50%” valign=”top”><b>Сустрэлася</b></td><td width=”50%” valign=”top”><b>Каментар</b></td></tr><tr><td width=”50%” valign=”top”>«<font color=”red”>а-у</font>»: …ботах.
На Ўкраіне паўднёв<font color=”red”>а-у</font>сходні вецер.
Тата любіць …”</td><td width=”50%” valign=”top”> <i>(«у» пасля галоснай «а» і злучка)</i></td></tr></tbody></table>”,
“res_uc“: “<table class=”pale” width=”100%”><tbody><tr><td width=”50%” valign=”top”><b>Сустрэлася</b></td><td width=”50%” valign=”top”><b>Каментар</b></td></tr><tr><td width=”50%” valign=”top”>«<font color=”red”>т ў</font>»: …Ко<font color=”red”>т ў</font> ботах.
На Ўкраіне …”</td><td width=”50%” valign=”top”> <i>(«ў» пасля зычнай «т» без знакаў прыпынку)</i></td></tr><tr><td width=”50%” valign=”top”>«<font color=”red”>Ў</font>»: …ў ботах.
На <font color=”red”>Ў</font>краіне паўднёва-усходні вецер.
Тата …”</td><td width=”50%” valign=”top”> <i>(ВЯЛІКАЯ «Ў» ДАЗВАЛЯЕЦЦА ТОЛЬКІ Ў ТЭКСТАХ, ДЗЕ ЎСЕ СЛОВЫ ПІШУЦЦА ВЯЛІКІМІ ЛІТАРАМІ)</i></td></tr><tr><td width=”50%” valign=”top”>«<font color=”red”>бў</font>»: …вецер.
Тата любіць буль<font color=”red”>бў</font>.…”</td><td width=”50%” valign=”top”> <i>(«ў» пасля зычнай «б»)</i></td></tr></tbody></table>”
}
]
Service page – https://corpus.by/ShortUSpellChecker/?lang=be
Cross referencrs
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Казлоўская, Н.Д. Этапы і асаблівасці перакладу юрыдычнай лексікі на прыкладзе Кодэкса аб шлюбе і сям’і з выкарыстаннем камп’ютарна-лінгвістычных рэсурсаў / Н.Д. Казлоўская, А.У. Бабкоў, Ю.С. Гецэвіч, А.В. Крывальцэвіч, Г.Р. Станіславенка, М.У. Марчык, І.В. Рэентовіч // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы I Респ. науч.-практ. конф. с междунар. участием, Минск, 23–24 февр. 2017 г. / БГУ, факультет социокультурных коммуникаций ; редкол. : О.Г. Прохоренко (отв. ред.) [и др.]. — Минск : Изд. центр БГУ, 2017. — C. 189-191.
- Станіславенка, Г.Р. Рэдагаванне электронных масіваў тэкстаў на беларускай мове з выкарыстаннем камп’ютарна-лінгвістычных сэрвісаў платформы www.corpus.by / Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 262-267.
- Марчык, М.У. Вычытка тэксту вялікага памеру на беларускай мове / М.У. Марчык, С.І. Лысы, Ю.С. Гецэвіч // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы II Междунар. науч.-практ. конф., Минск, 1–2 марта 2018 г. / редкол. : О. Г. Прохоренко (отв. ред.) [и др.]. — Минск : Издательский центр БГУ, 2018. — C. 58-63.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.