The service «Voiced Electronic Grammar Dictionary» is designed to obtain information on the correct spelling, pronunciation of words, allows you to see the transcription (classical form and in IPA format), also learn a detailed description of a word about its belonging to a particular part of speech (Figure 1). The service automatically generates a sound file with which you can listen to the word entered by the user and simultaneously save it.
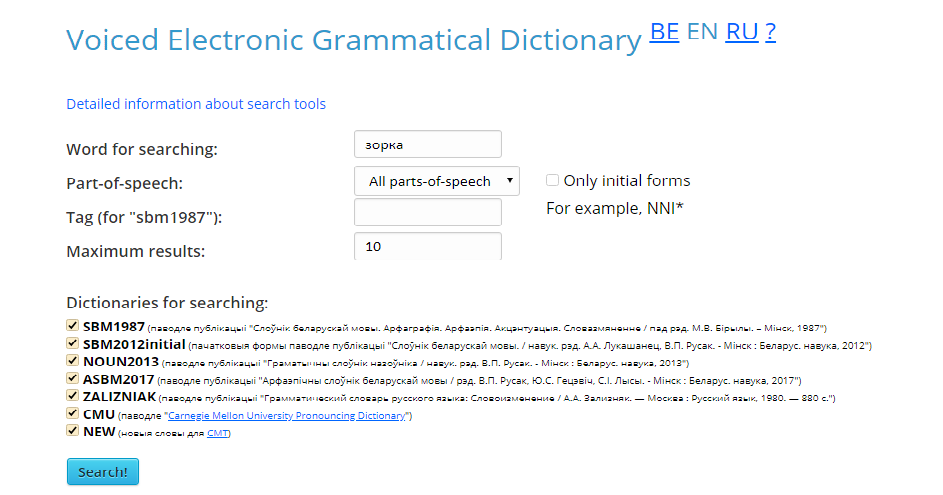
Figure 1
To get information about a word, enter the word In the «Search word» line, indicate which specific part of the speech the word belongs to, select which dictionaries to search for forms of the word, and click on the «Search! / Search!» button. The service supports work with such languages as Russian, Belarusian and English. For each of the languages presented their own specific dictionaries that the user can choose on their own. Dictionaries are presented in Figure 2.

Figure 2
The totals are displayed in the form of a table. An example of the final data is presented in Figure 3.
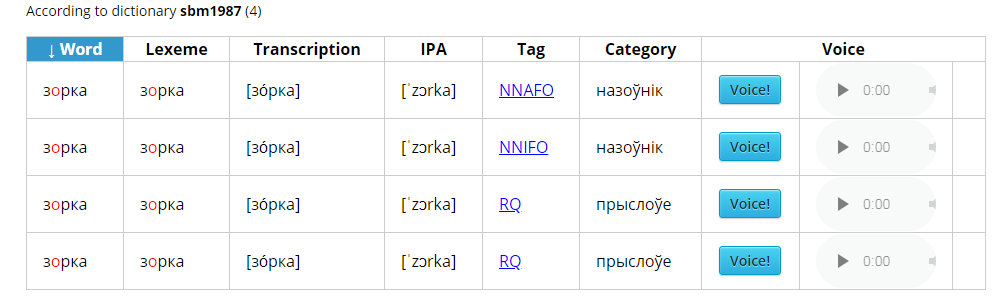


Figure 3
The service allows you to sort the totals for each of the columns. To do this, click on the header of the column by which you want to sort the list. When you click on the same heading again, the list is sorted in the reverse order. Figure 4 shows an example of the final data, sorted by part of speech in alphabetical order (noun, adverb, etc.).

Figure 4
In addition to the main functions, the service has additional ones:
- Opportunities to choose a specific part of speech to which the word belongs. To do this, in the «Part of speech» list choose what the user needs (Figure 5). Or select «All parts of speech» to see all possible word variations.
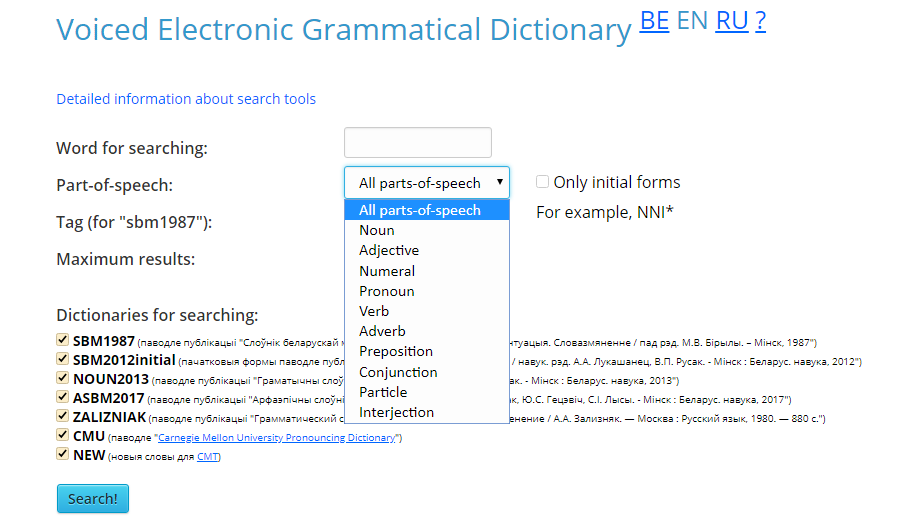
Figure 5
- Select the maximum number of results.
To select the maximum number of results, the user must specify the number in the «Maximum results» line. The number can be arbitrary, but the service limits the results to 30 lines.
- Displays only the initial forms of the word.
The user has the opportunity to see not all forms of the word, but only the initial ones. For this you need to put a tick in front of «Only initial forms». Or — to remove it if the user is interested in all forms of the source word
- Special characters for queries.
Another additional feature of the service is the use of special characters for more advanced search. Characters are opened by clicking on the «Read more about special characters for queries» field. Specific symbols and their capabilities are presented in Figure 6.

Figure 6
Description of special characters for queries:
1. «.» (dot) — used to indicate that a single character can be arbitrary. For example, to get a list of words that begin with “к” and end with “т”, you need to put a dot — «к.т» — instead of the missing letter and then click on the «Search! / Search!» button.
2. «*» (asterisk) — put in place of an arbitrary number of any letters in order to find words that begin with the letter combination «сло» and end with the combination «ік».
3. «+» (plus) — is placed when forming a push request after a vowel to find words with a certain click.
4. «=» (equal) — is set when forming a request after a vowel with a side stress.
Access to the service via the API
To access the service «Voiced Electronic Grammatical Dictionary» via the API, you should send an AJAX-request (type: POST) to the address https://corpus.by/VoicedElectronicGrammaticalDictionary/api.php. With an input array data the following parameters are passed:
- searchRequest — input search request.
- category — category to which the word in the query relates.
- onlyInitialForms — marker for searching only among initial forms.
- tagSbm1987 — tag of sbm1987 format.
- maximumResults — limit on the number of results collected.
- Markers for dictionaries usage:
- sbm1987 — «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987»;
- sbm2012initial — «Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. — Мінск : Беларус. навука, 2012»;
- noun2013 — nouns by the book «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adjective2013 — adjectives by the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- numeral2013 — numerals by the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- pronoun2013 — pronouns by the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- verb2013 — verbs by the book «Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adverb2013 — adverbs by the book «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- asbm2017 — «Арфаэпічны слоўнік беларускай мовы / уклад.: В. П. Русак, Ю. С. Гецэвіч, С. І. Лысы, В. А. Мандзік ; рэдкал.: В. П. Русак, Ю. С. Гецэвіч, С. І. Лысы. – Мінск : Беларус. навука, 2017»;
- zalizniak — «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. — Москва : Русский язык, 1980. — 880 c.»;
- cmu — «Carnegie Mellon University Pronouncing Dictionary»;
- tts — text-to-speech system dictionary;
- uwp_be — Belarusian words, collected by the system «Unknown Words Processor»;
- uwp_ru — Russian words, collected by the system «Unknown Words Processor».
Example of AJAX-request:
$.ajax({
type: “POST”,
url: “https://corpus.by/VoicedElectronicGrammaticalDictionary/api.php”,
data:{
“searchRequest”: “дз.сяты”,
“category”: “усе”,
“onlyInitialForms”: 0,
“tagSbm1987”: “”,
“maxContexts”: 10,
“sbm1987”: 1,
“sbm2008”: 1,
“sbm2012initial”: 1,
“noun2013”: 1
}
success: function(msg){ }
});
The server returns a JSON-array with the following parameters:
- searchRequest — input search request.
- resultArr — resulting array.
- resultCntArr — array with the number of results for each dictionary.
For example, the following reply will be formed on the above listed AJAX-request:
[
{
“searchRequest”: “дз.сяты”,
“resultArr”: {
“sbm1987”: {
“-1”: {
“id”: “ID”,
“word”: “Word”,
“accent”: “Accented word”,
“lexeme”: “Lexeme”,
“transcriptionCyr”: “Transcription”,
“transcriptionIPA”: “IPA”,
“tag”: “Tag”,
“category”: “Category”
}
“0”: {
“0”: {
“id”: “1436479”,
“word”: “дзесяты”,
“accent”: “дзеся+ты”,
“lexeme”: “дзесяты”,
“transcriptionCyr”: “[z’эс’а́ты]”,
“transcriptionIPA”: “[d͡zʲɛˈsʲatɨ]”,
“tag”: “DOMO”,
“category”: “лічэбнік”
}
“1”: { <…> }
“2”: { <…> }
“3”: { <…> }
}
}
“sbm2012initial”: { <…> }
“asbm2017”: { <…> }
}
“resultCntArr”: {
“sbm1987”: 4,
“sbm2012initial”: 1,
“noun2013”: 0,
“asbm2017”: 1
}
}
]
Спасылкі на крыніцы
Старонка сэрвіса: https://corpus.by/VoicedElectronicGrammaticalDictionary/?lang=en
Cross references
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Русак, В.П. Роля сучасных камп’ютарна-лінгвістычных рэсурсаў у фарміраванні культуры вуснай і пісьмовай мовы / В.П. Русак, Ю.С. Гецэвіч, В.А. Мандзік, С.І. Лысы // Першы міжнародны навуковы кангрэс беларускай культуры : зборнiк матэрыялаў (Мiнск, Беларусь, 5 – 6 мая 2016 г.) / Цэнтр даследаванняў беларускай культуры, мовы і літаратуры НАН Беларусі ; гал. рэд. А. І. Лакотка. — Мінск : Права і эканоміка, 2016. — C. 364-366.