Сэрвіс «Спецыялізаваны фанетычны слоўнік» прызначаны для адлюстравання транскрыпцыі спісаў слоў спецыялізаванай тэматыкі. На дадзены момант слоўнік змяшчае словы для рускай мовы, гэтыя словы ўжываліся ў бытавым і гутарковым тэматычным дамене. На старонцы сэрвіса знаходзіцца спіс літар па алфавіце, з якіх пачынаюцца словы з прапісаным фанетычным разборам. Карыстальнік можа выбраць любую літару і слова, што пачынаецца з абранай літары, і паглядзець транскрыпцыі яго парадыгмы, а таксама падрабязны фанетычны разбор кожнай словаформы.
Словаформа можа мець адну і болей транскрыпцый, не ўсе з якіх з’яўляюцца афіцыйнай нормай, але ўжываюцца ў гутарковым маўленні і павінны быць улічаныя, напрыклад, пры даследаванні асаблівасцей маўлення ці пры стварэнні сістэмы распазнавання маўлення.
Інфармацыя пра словаформу складзена ў наступным парадку: словаформа з націскам {часціна мовы, род, склон, лік / n варыянтаў транскрыпцыі}.
Асноўныя тэрміны і паняцці
Парадыгма — сукупнасць усіх словаформаў слова. Напрыклад, дрэва, дрэва, дрэву, дрэва, дрэвам, дрэве, дрэвы, дрэваў, дрэвам, дрэвы, дрэвамі, дрэвах.
Словаформа ці форма слова — выяўляе розныя граматычныя значэнні слова пры захаванні яго лексічнага значэння.
Транскрыпцыя ў лінгвістыцы — пісьмовая перадача тым ці іншым наборам пісьмовых знакаў (фанетычным алфавітам) элементаў гукавога маўлення (фанем, алафонаў, гукаў). У лінгвістычнай тэорыі і практыцы транскрыпцыя мае разнастайнае прымяненне.
Фанетыка — раздзел лінгвістыкі, які вывучае гукі маўлення і гукавую будову мовы, у прыватнасці, склады, гукаспалучэнні, заканамернасці злучэння гукаў у маўленчы ланцужок.
Фанетычны разбор слова — падрабязны аналіз слова з пункту гледжання яго правільнага вымаўлення: вызначэнне колькасці літар, гукаў, націску ў слове, вылучэнне галосных і зычных гукаў, іх класіфікацыя.
Асаблівасці сэрвіса
Слоўнікавая база сэрвіса на дадзены момант змяшчае 13713 словаформаў, кожная з якіх мае свой фанетычны разбор.
Практычная каштоўнасць
Фанетычны разбор слоў і словаформ дапаможа карыстальніку ў працы і вывучэнні прадстаўленай мовы, а менавіта фанетычныга складніку слова і варыянтаў яго вымаўлення. Таксама гэтая база фанетычных разбораў і транскрыпцый можа быць выкарыстана для дапамогі ў напісанні дакладаў на тэмы, звязаныя з мовай, маўленнем і яго паходжаннем.
Пры дапрацоўцы сэрвіса і папаўненні архіва новымі словаформамі ён зможа даць карыстальніку магчымасць пошуку патрэбнага слова і яго разбору.
Апісанне інтэрфейсу карыстальніка
Графічны інтэрфейс сэрвіса ўключае наступныя часткі, прадстаўленыя на малюнку 1-3.
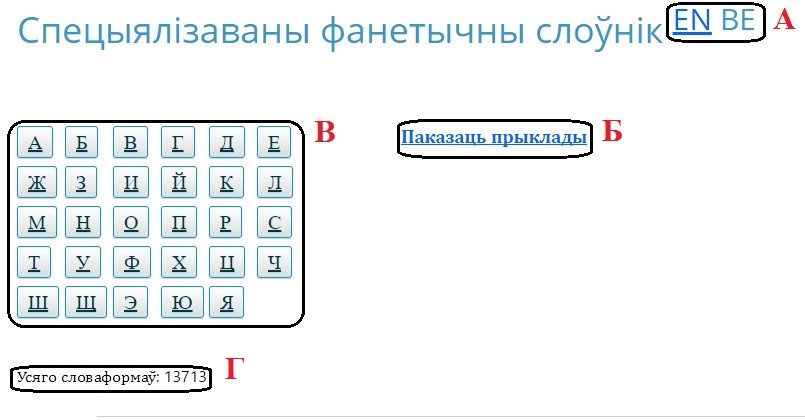
Малюнак 1. Асноўная старонка сэрвіса «Спецыялізаваны фанетычны слоўнік»
А — кнопкі выбару лакалізацый.
Б — спасылка на прыклады слоў.
В — табліца літар у алфавітным парадку, кожная з якой вядзе на спіс слоў, якія пачынаюцца з пазначанай літары.
Г — паказвае колькасць словаформ у слоўніку.
Д — спіс слоў для прагляду парадыгм і фанетычнага разбору (малюнак 2).

Малюнак 2. Спіс слоў для прагляду парадыгм і фанетычнага разбору
Кожнае слова прадстаўлена такім чынам, як на малюнку 3.
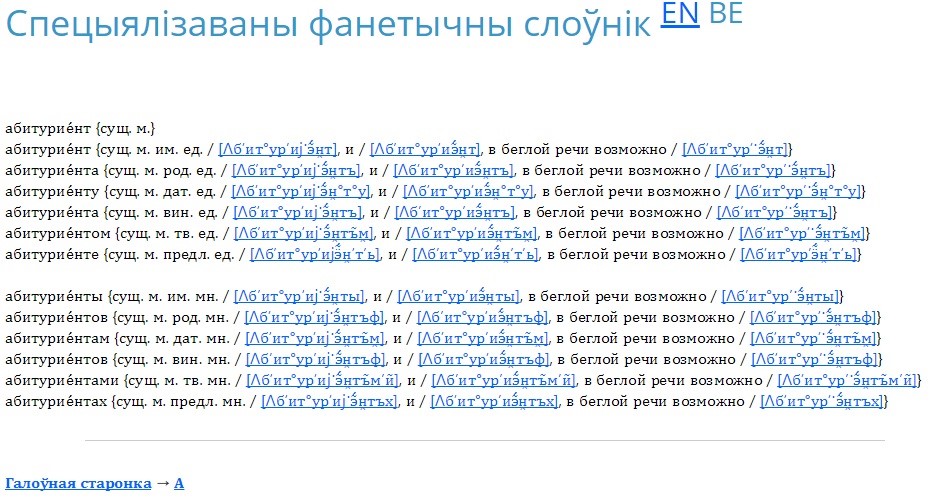
Малюнак 3. Разбор слова ў сэрвісе «Спецыялізаваны фанетычны слоўнік»
Карыстальніцкі сцэнар працы з сэрвісам
- Праглядзець прыклады прадстаўленых у слоўніку слоў.
- Націснуць літару, з якой пачынаецца слова, разбор якога неабходна даведацца.
- Выбраць слова са спісу слоў і праглядзець яго разбор (у прыватнасці, парадыгму і транскрыпцыі).
- Націснуць на транскрыпцыю, каб пабачыць фанетычны разбор слова паводле яе.
Доступ да сэрвіса праз API
Для доступу да сэрвіса “Спецыялізаваны фанетычны слоўнік” праз API неабходна адправіць AJAX-запыт тыпу GET на адрас https://corpus.by/SpecializedPhoneticDictionary/api.php. Праз масіў data перадаюцца наступныя параметры:
- localization — мова лакалізацыі; прымае значэнні “en”, “be”, “ru”.
- op — назва аперацыі; прымае значэнні:
- getFirstLetters — выбар дадзенай аперацыі вядзе да атрымання фрагмента html-старонкі, які ўяўляе сабой меню выбару даступных літар (падраздзелаў слоўніка).
- getLexemes — выбар дадзенай аперацыі вядзе да атрымання фрагмента html-старонкі, які ўяўляе сабой меню выбару лексемы на абраную літару.
- getParadigm — выбар дадзенай аперацыі вядзе да атрымання фрагмента html-старонкі, які ўяўляе сабой меню выбару словаформ абранай лексемы.
- getPhoneticParsing — выбар дадзенай аперацыі вядзе да атрымання фрагмента html-старонкі, які ўяўляе сабой фанемны разбор абранай словаформы.
- ex — маркер адлюстравання спісу слоў на галоўнай старонцы сэрвіса; неабходны толькі пры op = “getFirstLetters”; прымае значэнні “show”, “hide”.
- letter — падраздзел слоўніка, у які ўваходзяць словы, што пачынаюцца з пэўнай літары; напрыклад, “Я”.
- lexeme — лексема, словаформы якой будуць прыведзены разам з транскрыпцыямі; напрыклад, “янва́рский”.
- wordform — словаформа. Напрыклад, “янва́рскими”.
- transcription — транскрыпцыя. Напрыклад, “[ṷ,и̃э,н,в,а́,р̭,с,к’,и̃,м’,и̃]”.
Прыклад AJAX-запыту:
$.ajax({
type: “GET”,
url: “https://corpus.by/SpecializedPhoneticDictionary/api.php”,
data: {
“localization”: “en”,
“op”: “getPhoneticParsing”,
“letter”: “Я”,
“lexeme”: “янва́рский”,
“wordform”: “янва́рскими”,
“transcription”: “[ṷ,и̃э,н,в,а́,р̭,с,к’,и̃,м’,и̃]”
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з выніковым фрагментам html-старонкі (параметр result). Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“result”: “янва́рскими [ṷи̃<sup>э</sup>нва́р̭ск’и̃м’и̃]<br><br>
<table><tbody><tr><td>[ṷ] – согласный, среднеязычный средненёбный, аппроксимант, сонорный, палатальный<br>
</td></tr><tr><td>[и̃<sup>э</sup>] – гласный, безударный, переднего ряда, верхне-среднего подъёма, нелабиализованный, назализованный<br>
</td></tr><tr><td>[н] – согласный, переднеязычный дорсальный зубной, смычно-проходный носовой, сонорный, твердый<br>
</td></tr><tr><td>[в] – согласный, губно-зубной, щелевой, шумный звонкий, твердый<br>
</td></tr><tr><td>[а́] – гласный, ударный, среднего ряда, нижнего подъёма, нелабиализованный<br>
</td></tr><tr><td>[р̭] – согласный, переднеязычный, какуминальный, передненёбный, дрожащий, десонантизованный, твердый<br>
</td></tr><tr><td>[с] – согласный, переднеязычный, дорсальный, зубной, щелевой, шумный, глухой, твердый<br>
</td></tr><tr><td>[к’] – согласный, заднеязычный средненёбный, взрывной, шумный глухой, мягкий<br>
</td></tr><tr><td>[и̃] – гласный, безударный, переднего ряда, верхнего подъёма, нелабиализованный, назализованный<br>
</td></tr><tr><td>[м’] – согласный, губно-губной, смычно-проходный носовой, сонорный, мягкий<br>
</td></tr><tr><td>[и̃] – гласный, безударный, переднего ряда, верхнего подъёма, нелабиализованный, назализованный<br>
</td></tr></tbody></table><div class=”divider”></div><a href=”https://corpus.by/SpecializedPhoneticDictionaryViaApi/index.php?lang=en”>Main page</a> → <a href=”https://corpus.by/SpecializedPhoneticDictionaryViaApi/index.php?lang=en&op=getLexemes&letter=%D0%AF”>Я</a> → <a href=”https://corpus.by/SpecializedPhoneticDictionaryViaApi/index.php?lang=en&op=getParadigm&letter=%D0%AF&lexeme=%D1%8F%D0%BD%D0%B2%D0%B0%CC%81%D1%80%D1%81%D0%BA%D0%B8%D0%B9″>янва́рский</a>”
}
]
Спасылкі на крыніцы
Старонка сэрвісу: https://corpus.by/SpecializedPhoneticDictionary/?lang=be
Апісанне падрыхтавалі:
ПАНКЕВІЧ Арцём Яўгеньевіч, МАРЧЫК Марына Уладзіміраўна