Сэрвіс «Пошук найбліжэйшых слоў» апрацоўвае паслядоўнасці сімвалаў, раздзеленыя сімваламі водступаў, і параўноўвае іх з карыстальніцкімі слоўнікавымі паслядоўнасцямі. Вынікам працы сэрвіса з’яўляецца HTML-табліца з парамі «слова – адпаведнік», дзе слова – зыходная паслядоўнасць сімвалаў, адпаведнік – слоўнікавая паслядоўнасць сімвалаў, найбліжэйшая да слова згодна з адлегласцю Левенштэйна.
Асноўныя тэрміны і паняцці
Адлегласць Левенштэйна (рэдакцыйная адлегласць, дыстанцыя рэдагавання) – метрыка, якая вымярае рознасць паміж дзвюма паслядоўнасцямі сімвалаў. Яна вызначаецца як мінімальная колькасць аднасімвальных аперацый (а менавіта ўстаўкі, выдалення, замены), неабходных для ператварэння адной паслядоўнасці сімвалаў у іншую. У агульным выпадку аперацыям, якія выкарыстоўваюцца ў гэтым ператварэнні, можна прызначыць розныя цэны (у рамках працы сэрвіса аперацыі раўнацэнныя). Шырока выкарыстоўваецца ў тэорыі інфармацыі і камп’ютарнай лінгвістыцы. Упершыню задачу вымярэння дыстанцыі рэдагавання паставіў у 1965 годзе савецкі матэматык Уладзімір Левенштэйн.
Практычная каштоўнасць
Практычная каштоўнасць сэрвіса «Пошук найбліжэйшых слоў» у многім абумоўленая сферай прымянення вылічэння адлегласці Левенштэйна. Дадзенае вылічэнне актыўна прымяняецца:
- для выпраўлення памылак у слове (у пошукавых сістэмах, базах дадзеных, пры ўводзе тэксту, пры аўтаматычным распазнаванні адсканіраванага тэксту або маўлення);
- для параўнання тэкставых файлаў (пры дадзеным параўнанні ролю «сімвалаў» граюць радкі, а ролю «радкоў» – файлы);
- у біяінфарматыцы – для параўнання генаў, храмасом і бялкоў.
Асаблівасці сэрвіса
Некаторыя мовы праграмавання (напрыклад, PHP) маюць стандартныя ўбудаваныя функцыі для вылічэння адлегласці Левенштэйна. Тым не менш, рэалізацыя дадзеных функцый можа сур’ёзна абмяжоўваць даўжыню радкоў, якія параўноўваюцца, у выніку чаго апрацоўка вялікіх радкоў прыводзіць да заведама няправільнага выніку. Акрамя таго, няма ніякай гарантыі, што дадзеная функцыя не рэалізавана рэкурсіўна. Падобная рэалізацыя ў многіх выпадках можа запатрабаваць непажаданыя затраты сістэмных рэсурсаў. Нашае вылічэнне адлегласці Левенштэйна рэалізавана ітэратыўна і мае высокі парог даўжыні радкоў, якія параўноўваюцца – 1 мільён сімвалаў (абмежаванне ўстаноўлена толькі для выключэння перагрузак сервера).
Усе словы, якія аналізуе сэрвіс, праходзяць папярэднюю апрацоўку. Так, «словамі» сэрвіс лічыць толькі тыя паслядоўнасці, якія складаюцца з асноўных кірылічных і лацінскіх сімвалаў, асноўных сімвалаў апострафа, націску і сімвала злучка, а таксама адпавядаюць пэўнаму шаблону (якому адпавядае пераважная большасць слоў натуральных моў). Апрацоўка рэгістранезалежная – напрыклад, сімвалы «к» і «К» лічацца адным і тым жа сімвалам.
Алгарытм працы сэрвіса
Асноўны алгарытм
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, Text;
- Карыстальніцкі ўвод слоўнікавых слоў, Dictionary;
- Значэнне опцыі, якая адказвае за ўключэнне ў выніковую табліцу слоў, для якіх у слоўніку знойдзены поўны адпаведнік, KnownWordsIgnore. Калі роўнае true, падобныя словы не будуць выводзіцца;
- Асноўныя сімвалы, з якіх можа складацца слова (асноўныя кірылічныя і лацінскія сімвалы), MainChars;
- Дадатковыя сімвалы, з якіх можа складацца слова (сімвалы апострафа, галоўнага і пабочнага націску, сімвал злучка), AdditionalChars.
Пачатак алгарытму.
Крок 1.1. Прывядзенне ўсіх слоў у Dictionary да ніжняга рэгістра. Размежаванне Dictionary на асобныя элементы; раздзяляльнікам выступаюць усе магчымыя сімвалы водступаў.
Крок 1.2. Стварэнне пераменнай Result і запіс у яе пачатковага кода выніковай HTML-табліцы:
<table id=”resultTableId” class=”table table-sm table-striped” style=”table-layout: fixed; width: 100%;”><thead><tr><th scope=”col”><b>Unknown word</b></th><th scope=”col”><b>Possible variant</b></th></tr></thead><tbody>’;
Крок 1.3. Стварэнне масіву ParagrapsArr і запаўненне яго радкамі карыстальніцкага ўводу Text (карыстальніцкім уводам, раздзеленым паводле сімвала пераводу радка).
Крок 2. Для кожнага элемента Paragraph у ParagraphsArr выканаць крокі 2.1. – 2.3.
Крок 2.1. Выдаліць з Paragraph пачатковыя і канцавыя сімвалы водступаў.
Крок 2.2. Стварыць масіў WordsArr і паслядоўна запоўніць яго ўсімі элементамі Paragraph, якія адпавядаюць шаблону [<адзін сімвал MainChars>+<0 або больш сімвалаў MainChars або AdditionalChars>] альбо шаблону [0 або больш сімвалаў MainChars].
Крок 2.3. Для ўсіх элементаў Word у WordsArr выканаць крокі 2.3.1. – 2.3.3.
Крок 2.3.1. Стварыць пераменную Nearest для наступнага запісу найбліжэйшага да Word слова і ініцыялізаваць яе пустым значэннем. Стварыць пераменную Distance для наступнага запісу адлегласці Левенштэйна і ініцыялізаваць яе значэннем 999999.
Крок 2.3.2. Для кожнага элемента Entry у Dictionary выканаць крокі 2.3.2.1. – 2.3.2.2.
Крок 2.3.2.1. Стварыць пераменную Lev і запісаць у яе адлегласць паміж Word і Entry, вызначаную з дапамогай функцыі вылічэння адлегласці Левенштэйна.
Крок 2.3.2.2. Калі Lev = 0, зрабіць пераменную Nearest роўнай Word, устанавіць значэнне Distance роўным 0 і завяршыць цыкл, распачаты ў кроку 2.3.2. Інакш, калі Lev < Distance, зрабіць пераменную Nearest роўнай Entry, пераменную Distance – роўнай Lev. Паўтарэнне дадзенага кроку на кожнай ітэрацыі цыкла, распачатага ў кроку 2.3.2., прывядзе да знаходжання найбліжэйшага да Word слова.
Крок 2.3.3. Калі KnownWordsIgnore = true, і пры гэтым Distance не роўная 0, дапоўніць Result радком выгляду [«<tr><td style=”word–wrap: break–word“>»+Word+« </td><td style=”word–wrap: break–word“>»+Nearest+«</td></tr>»]. Калі KnownWordsIgnore = false, дапоўніць Result дадзеным радком у любым выпадку.
Крок 3. Дапоўніць Result радком «</tbody></table>» і скончыць фарміраванне выніковай табліцы.
Крок 4. Выдаць карыстальніку выніковую табліцу.
Канец алгарытму.
Функцыя вылічэння адлегласці Левенштэйна
Уваходныя дадзены алгарытму:
- Першае слова, First;
- Другое слова, Second.
Пачатак алгарытму.
Крок 1. Калі словы First і Second ідэнтычныя, вярнуць 0 і завяршыць алгарытм.
Крок 2.1. Стварыць пераменную FLen і запісаць у яе даўжыню радка First. Стварыць пераменню SLen і запісаць у яе даўжыню радка Second.
Крок 2.2. Калі FLen = 0 альбо SLen = 0, вярнуць FLen (у выпадку SLen = 0) альбо SLen (у выпадку FLen = 0) і завяршыць алгарытм.
Крок 3. Стварыць масіў Dist і паслядоўна запоўніць яго лічбамі ад 0 да SLen, кожная лічба большая за папярэднюю на адзінку.
Крок 4. Для I = 0; I < FLen; I++ выканаць крокі 4.1. – 4.3.
Крок 4.1. Стварыць масіў ForDist, які складаецца з адзінага элемента, роўнага I+1.
Крок 4.2. Для J = 0; J < SLen; J++ выканаць крокі 4.2.1 – 4.2.2.
Крок 4.2.1. Стварыць лічбавую пераменную Cost для запісу карэктыроўкі «цаны» аперацыі замены. Калі сімвал First[I] роўны сімвалу Second[J], ініцыялізаваць Cost значэннем 0, інакш – значэннем 1.
Крок 4.2.2. Далучыць да ForDist новы элемент (у праграмнай рэалізацыі парадкавы нумар дадзенага элемента роўны J+1), роўны мінімальнаму з трох наступных значэнняў:
- Dist[J+1] + 1 (цана аперацыі ўстаўкі);
- ForDist[J] + 1 (цана аперацыі выдалення);
- Dist[J] + Cost (цана аперацыі замены).
Крок 4.3. Паслядоўна ініцыялізаваць ячэйкі масіву Dist значэннямі адпаведных ячэек масіву ForDist, які атрымаўся пасля выканання кроку 4.2. (даўжыня абодвух масіваў будзе роўнай). Дадзены крок выконваецца ў канцы кожнай ітэрацыі цыклу, распачатага ў кроку 4.
Крок 5. Вярнуць значэнне апошняй ячэйкі масіву Dist (праграмна – значэнне ячэйкі, парадкавы нумар якой адпавядае SLen) і завяршыць алгарытм.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Знешні выгляд карыстальніцкага інтэрфейсу прадстаўлены на малюнку 1.
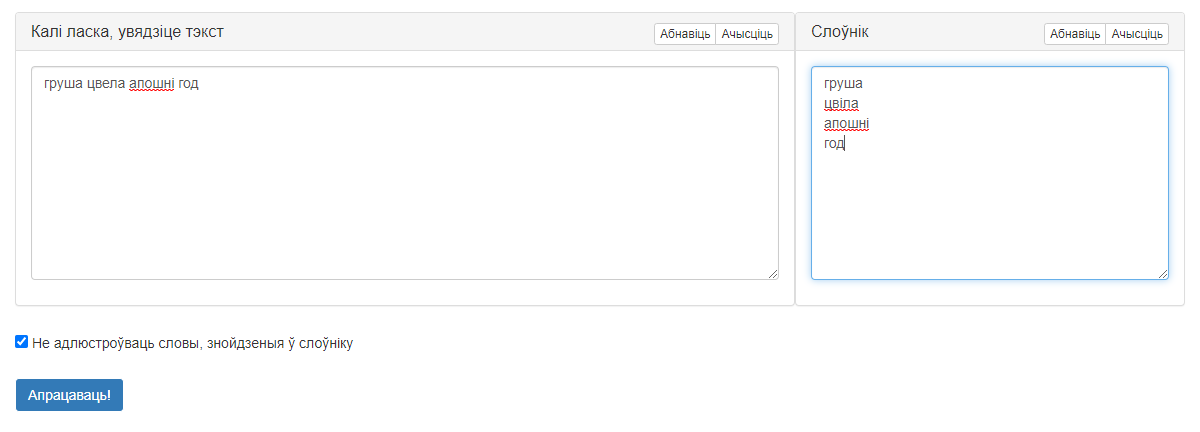
Малюнак 1 – Графічны інтэрфейс сэрвіса «Пошук найбліжэйшых слоў»
Інтэрфейс мае наступныя вобласці:
- Поле ўводу тэксту для апрацоўкі. Дадзенае поле забяспечанае кнопкамі «Абнавіць» (вярнуць дадзеныя па змаўчанні) і «Ачысціць» (выдаліць усе дадзеныя);
- Поле «Слоўнік» для ўводу слоў для праверкі. Дадзенае поле таксама забяспечанае кнопкамі «Абнавіць» і «Ачысціць»;
- Опцыя «Не адлюстроўваць словы, знойдзеныя ў слоўніку», якая ўплывае на канчатковы вынік працы сэрвіса;
- Кнопка «Апрацаваць!», якая запускае апрацоўку і дае магчымасць атрымаць вынікі.
Пасля націскання на кнопку «Апрацаваць!» і правядзення апрацоўкі ўнізе экрана з’яўляецца табліца з вынікамі.
Карыстальніцкія сцэнарыі працы з сэрвісам
Сцэнарый 1. Апрацоўка з адлюстраваннем усіх слоў зыходнага тэксту
- Увесці тэкст у поле ўводу тэксту.
- Увесці словы для праверкі, раздзеленыя прабеламі і/або сімваламі табуляцыі і пераводу радка, у поле «Слоўнік».
- Пераканацца, што опцыя «Не адлюстроўваць словы, знойдзеныя ў слоўніку» адключаная. Калі опцыя уключана, зняць адпаведны сцяжок.
- Націснуць кнопку «Апрацаваць!».
- Атрымаць вынік у полі выдачы вынікаў. Пры неабходнасці ўнесці змены ў зыходны тэкст і націснуць кнопку «Апрацаваць!» яшчэ раз.
Магчымы вынік працы сэрвіса згодна з дадзеным сцэнарыем прадстаўлены на малюнку 2.
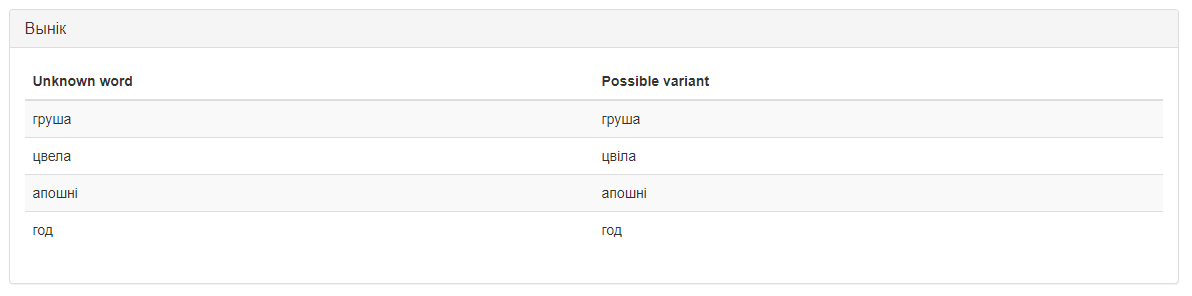
Малюнак 2 – Вынік працы сэрвіса «Пошук найбліжэйшых слоў» згодна са сцэнарыем 1
Сцэнарый 2. Апрацоўка з адлюстраваннем толькі невядомых слоў
- Увесці тэкст у поле ўводу тэксту.
- Увесці словы для праверкі, раздзеленыя прабеламі і/або сімваламі табуляцыі і пераводу радка, у поле «Слоўнік».
- Пераканацца, што опцыя «Не адлюстроўваць словы, знойдзеныя ў слоўніку» ўключаная. Калі опцыя адключана, адзначць адпаведны сцяжок.
- Націснуць кнопку «Апрацаваць!».
- Атрымаць вынік у полі выдачы вынікаў. Пры неабходнасці ўнесці змены ў зыходны тэкст і націснуць кнопку «Апрацаваць!» яшчэ раз.
Магчымы вынік працы сэрвіса згодна з дадзеным сцэнарыем прадстаўлены на малюнку 3.

Малюнак 3 – Вынік працы сэрвіса «Пошук найбліжэйшых слоў» згодна са сцэнарыем 2
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Пошук найбліжэйшых слоў» праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/NearestWordsFinder/api.php. Праз масіў data перадаюцца наступныя параметры:
- localization – мова лакалізацыі. Можа прымаць значэнні «en» (ангельская мова) і «be» (беларуская мова).
- text – паслядоўнасці сімвалаў, размешчаныя паміж сімваламі водступу, якія будуць параўноўвацца са слоўнікавымі значэннямі.
- dictionary – паслядоўнасці сімвалаў, размешчаныя паміж сімваламі водступу, якія будуць параўноўвацца са словамі зыходнага тэксту.
- knownWordsIgnore – параметр, які адказвае за адлюстраванне слоў тэксту, знойдзеных у слоўніку. Можа прымаць значэнні «0» (адлюстроўваць) і «1» (не адлюстроўваць).
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/NearestWordsFinder/api.php”,
data:{
“localization”: “en”,
“text”: “укоз об налогах на растаможивании автомобилей”,
“dictionary”: “указ налоги на налогах автомобили растаможить растаможил растаможивании автомобилей об”,
“knownWordsIgnore”: 0
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON- з зыходным тэкстам (параметр text) і кодам выніковай HTML-табліцы (параметр result) з парамі «слова – адпаведнік», дзе слова – зыходная паслядоўнасць сімвалаў, адпаведнік – слоўнікавая паслядоўнасць сімвалаў, найбліжэйшая да слова згодна з адлегласцю Левенштэйна. Напрыклад, паводле прыведзенага вышэй AJAX-запыту будзе сфарміраваны наступны адказ:
[
{
“text”: “укоз об налогах на растаможивании автомобилей“,
“result”: <table id=\”resultTableId\” class=\”table table-sm table-striped\” style=\”table-layout: fixed; width: 100%;\”><thead><tr><th scope=\”col\”><b>Unknown word<\/b><\/th><th scope=\”col\”><b>Possible variant<\/b><\/th><\/tr><\/thead><tbody><tr><td style=\”word-wrap: break-word\”> укоз<\/td><td style=\”word-wrap: break-word\”> указ<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>об <\/td><td style=\”word-wrap: break-word\”>об<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>налогах<\/td><td style=\”word-wrap: break-word\”>налогах<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>на<\/td><td style=\”word-wrap: break-word\”>на<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>растаможивании<\/td><td style=\”word-wrap: break-word\”>растаможивании<\/td><\/tr><tr><td style=\”word-wrap: break-word\”>автомобилей<\/td><td style=\”word-wrap: break-word\”>автомобилей<\/td><\/tr><\/tbody><\/table> “,
}
]
Спасылкі на крыніцы
Старонка сэрвіса – https://corpus.by/NearestWordsFinder/
Адлегласць Левенштэйна (артыкул Вікіпедыі) – https://ru.wikipedia.org/wiki/Расстояние_Левенштейна