Сэрвіс «Лематызатар» прызначаны для вызначэння пачатковых форм слоў. На ўваход сэрвісу падаецца адвольны тэкст на беларускай або рускай мове. Вынікам працы сэрвіса з’яўляецца спіс слоў уваходнага тэксту з іх пачатковымі формамі, а таксама спіс слоў, пачатковую форму якіх не ўдалося вызначыць. Агульны выгляд, у якім будзе прадстаўлены вынік, можа быць наладжаны згодна з патрэбамі карыстальніка.
Асноўныя тэрміны і паняцці
Лема (у лінгвістыцы) – нармальная (слоўнікавая, асноўная, кананічная) форма слова. Лемы выкарыстоўваюцца ў слоўніках у якасці загаловачных слоў, пасля якіх могуць пералічвацца іншыя формы лексемы. У рускай і беларускай мовах нармальнымі лічацца наступныя марфалагічныя формы:
- для назоўнікаў – назоўны склон, адзіночны лік;
- для прыметнікаў – назоўны склон, адзіночны лік, мужчынскі род;
- для дзеясловаў, дзеепрыметнікаў, дзеепрыслоўяў – дзеяслоў у інфінітыве незакончанага трывання.
Лематызацыя – працэс прывядзення словаформы да яе пачатковай формы (лемы).
Метад поўнага перабору – спосаб пошуку вырашэння задачы вычарпаннем усіх магчымых варыянтаў. Сэрвіс «Лематызатар» у сваёй працы выкарыстоўвае адзін з відаў поўнага перабору – перабор па слоўніку.
Практычная каштоўнасць
Метад лематызацыі прымяняецца ў пошукавых алгарытмах у працэсе схематызацыі вэб-дакуметаў, а таксама пры іх індэксіраванні. Нягледзячы на высокі тэхналагічны ўзровень сучасных пошукавых сістэм, падобная апрацоўка не заўсёды бывае дакладнай, паколькі пошукавы робат часта ўлічвае толькі адну з магчымых лем словаформы, прыведзенай у тэксце дакумента. Таму далейшае развіццё метадаў лематызацыі, чаму наш сэрвіс прызваны паспрыяць, з’яўляецца прыярытэтнай тэхналагічнай задачай.
Акрамя таго, на дадзены момант у інтэрнэце намі не выяўлена паўнавартасных беларускіх пошукавых сістэм (нават пошукавая сістэма папулярнага партала tut.by выкарыстоўвае алгарытмы «Яндэкса»). Развіццё нацыянальнай інфармацыйнай індустрыі, прыватным выпадкам якога можа быць стварэнне айчынных пошукавых сістэм (якія ў любым выпадку будуць выкарыстоўваць лематызатары), з’яўляецца часткай стратэгіі развіцця інфарматызацыі ў Рэспубліцы Беларусь.
Выкарыстанне лематызацыі значна паляпшае якасць аналізу сайтаў і дакументаў. Калі ў камерцыйнай сферы (напрыклад, для палягчэння знаходжання тавараў і паслуг у інтэрнэце, а таксама для іх прасоўвання) якасная лематызацыя будзе адною з «радавых» пераваг, то пры апрацоўцы дакументаў медыцынскага, юрыдычнага, розных тэхналагічных даменаў дадзеная акалічнасць крытычна важная. Сістэмы лематызацыі рускіх тэкстаў распрацаваныя на сённяшні дзень дастаткова добра, у той час як для беларускай мовы сітуацыя выглядае інакш. Многія працы беларускіх вучоных даступныя чытачам на беларускай мове. Правільная лематызацыя як асноўных тэкстаў, так і дапаможных дадзеных (назваў артыкулаў, звестак пра аўтараў, спісаў літаратуры) можа быць паспяхова прыменена ў дзейнасці бібліятэк.
Прыватнымі выпадкамі прымянення лематызацыі могуць быць крыміналістычная лінгвістычная экспертыза, аналіз тэкстаў на прадмет плагіяту, аналіз мовы тэкстаў пісьменніка, аналіз электронных вучэбных тэкстаў і электронных тэкстаў, пароджаных навучэнцамі, у сістэмах адаптыўнага навучання.
Асаблівасці сэрвіса
У камп’ютарнай лінгвістыцы лематызацыя часта вызначаецца як метад марфалагічнага аналізу, у працэсе якога ад лексемы павінны быць адкінутыя ўсе флектыўныя элементы, якія не адпавядаюць пачатковай форме слова. Для атрымання дапаможных дадзеных, у прыватнасці для вызначэння стандартнай структуры пачатковай формы слоў пэўнай часціны мовы, сістэма лематызацыі можа выкарыстоўваць пошук па слоўніку.
На дадзены момант метад пошуку па слоўніках з’яўляецца адзіным рашэннем, якое прымяняе сэрвіс. Ніжэй прадстаўлены поўны спіс слоўнікаў, якія выкарыстоўваюцца:
- sbm1987 – «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987».
- noun2013 – назоўнікі, згодна з выданнем «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- adjective2013 – прыметнікі, згодна з выданнем «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- numeral2013 – лічэбнікі, згодна з выданнем «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- pronoun2013 – займеннікі, згодна з выданнем «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- verb2013 – дзеясловы, згодна з выданнем «Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- adverb2013 – прыслоўі, згодна з выданнем «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- zalizniak – «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. – Москва : Русский язык, 1980. – 880 c.».
Указаныя рускія і беларускія выданні дастаткова аўтарытэтныя для таго, каб быць выкарыстанымі ў працэсе лематызацыі. Гэта дае пэўныя перавагі: так, формы кшталту «піла» будуць распазнаныя сэрвісам як формы розных часцін мовы («піла» – назоўнік і «піла» – дзеяслоў). Таксама будуць распазнаныя многія амографы («це́лую – целый» і «целу́ю – целовать»), формы слоў, утвораныя нулявой суфіксацыяй («удар»).
Тым не менш, ступень паўнаты слоўнікаў і спецыфіка размяшчэння інфармацыі ў іх электронных копіях параджаюць некаторыя недакладнасці пры апрацоўцы тэксту. Пры падрабязным аналізе працы сэрвіса былі выяўленыя наступныя праблемы:
- Не лематызуюцца ўласныя імёны.
- Не лематызуюцца многія запазычанні («рэлаксацыя», «такенізацыя», «шугарынг»), асабліва ў выпадках, калі такія запазычанні маюць прэфіксы або суфіксы. Тым не менш, некаторыя запазычанні (напрыклад, «ідэнтыфікацыя», «дэпрывацыя») могуць быць лематызаваныя, калі ў іх адсутнічаюць падобныя марфемы.
- Не лематызуецца большасць слоў з суплетыўнымі асновамі. Гэта тычыцца некаторых ступеняў параўнання прыметнікаў («добры – лепшы», «хороший – лучший»), некаторых назоўнікаў («чалавек – людзі»), дзеясловаў («класціся – легчы»). Займеннікі («мы – нас», «я – мяне») у большасці выпадкаў (хаця і не ва ўсіх) будуць лематызаваныя.
- Не лематызуюцца многія словы, якія маюць два і больш кораня («чорна-зялёны»), а таксама лексемы з дадаткамі («чалавек-амфібія»), хаця частка падобных слоў усё ж можа быць лематызавана.
- Словы з памяншальна-ласкальнымі і павелічальна-зневажальнымі суфіксамі («сильненький», «городишко») у многіх выпадках таксама не будуць лематызаваныя. У асаблівасці гэта тычыцца рускай мовы. Для беларускай мовы частка падобных словаформ («цёпленькі», «гарадочак») будзе апрацоўвацца так, нібыта яны з’яўляюцца самастойнымі лексемамі.
- У многіх выпадках цяжкасці будуць выклікаць назвы маладых істот («качаня», «жарабя»).
- Многія прыслоўі з прыстаўкай «па-» (рус. «по-») і суфіксам «-у-» адзначаюцца сэрвісам як невядомыя («па-афганску»), хаця, у прынцыпе, падобныя словы не патрабуюць лематызацыі, паколькі з’яўляюцца нязменнымі.
- Для рускай мовы дзеепрыметнікі і дзеепрыслоўі прыводзяцца не да дзеяслова, а да сваёй «пачатковай словаформы» («сделавши – сделав», «убоявшихся – убоявшийся»). У выпадку з беларускай мовай у падобнай сітуацыі вынік апрацоўкі залежыць ад выбраных карыстальнікам слоўнікаў.
- Для беларускай мовы сінтэтычныя формы ступеняў параўнання («мацнейшы», «найпрыгажэйшы») у агульным выпадку будуць прыводзіцца не да зыходнай формы прыметніка, а да формы назоўнага склону адзіночнага ліку мужчынскага роду, як у выпадку, калі б формы ступеняў параўнання былі самастойнымі прыметнікамі. Для рускай мовы сінтэтычныя формы ступеняў параўнання («сильнейший», «наимощнейший») лематызаваныя не будуць.
- Усе словаформы, утвораныя аналітычным шляхам («самы прыгожы», «зрабіў бы»), разглядаюцца сэрвісам як набор асобных слоў і апрацоўваюцца адпаведным чынам.
Многія з прыведзеных вышэй праблем вырашаюцца шляхам укаранення марфалагічнага аналізу, які ідзе пасля слоўнікавага аналізу. Таму распрацоўка і ўкараненне правіл марфалагічнага аналізу з’яўляецца прыярытэтнай задачай развіцця сэрвіса.
Алгарытм працы сэрвіса
Асноўны алгарытм
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, UText;
- Карыстальніцкі ўвод вядомых лем, UserWords;
- Карыстальніцкі выбар фармату вываду вынікаў, Format;
- Значэнне опцыі, якая адказвае за вывад слоўнікаў, у якіх была знойдзена словаформа, ShowDictionaryNames;
- Сімвал або камбінацыя сімвалаў, якія будуць выкарыстаныя ў якасці раздзяляльніка, Delimiter;
- Карыстальніцкі выбар слоўнікаў, якія будуць задзейнічаныя ў апрацоўцы, Dictionaries.
Пачатак алгарытму.
Крок 1. Раздзяліць UText на масіў параграфаў ParagraphsArr паводле сімвала пераводу радка.
Крок 2. Для кожнага Paragraph у ParagraphsArr выканаць крокі 2.1. – 2.2.
Крок 2.1. Выдаліць з Paragraph пачатковыя і канцавыя прабелы.
Крок 2.2. Калі Paragraph ≠ ∅, апрацаваць Paragraph з дапамогай функцыі апрацоўкі параграфа. Атрыманы вынік запісаць у асацыятыўны масіў токенаў TokensArray. Яшчэ аднім вынікам апрацоўкі з’яўляецца асацыятыўны масіў KnownWords.
Крок 3. Калі TokensArray ≠ ∅, выканаць крокі 3.1. – 3.3.
Крок 3.1. Фарміраванне асацыятыўнага масіву ўнікальных слоў UniqueWords. Для кожнага Token у TokensArray праверыць, ці з’яўляецца значэнне па ключы Type роўным Word, а значэнне па ключы WritingSystem роўным Cyrillic. Калі ўмова для канкрэтнага Token правільная, стварыць пераменную Word і ініцыялізаваць яе элементам сутнасці Token па ключы Normalized, з якога выдаленыя ўсе сімвалы «+» і «=» (сімвалы асноўнага і пабочнага націскаў). Далей, праверыць наступныя ўмовы:
- Ці прысутнічае ў KnownWords лексема, аналагічная элементу сутнасці Token па ключы Normalized. Калі прысутнічае, дадаць у UniqueWords для Word па ключы Known асацыятыўны масіў, у якім ключу Accent адпавядае элемент сутнасці Token па ключы Normalized, а ключу Initial– той жа элемент, знойдзены ў KnownWords, пасля чаго перайсці да апрацоўкі наступнага Token альбо, калі апошні Token дасягнуты, – да кроку 3.2.
- Ці прысутнічае ў KnownWords лексема, аналагічная Word. Калі прысутнічае, дадаць у UniqueWords для Word па ключы Known асацыятыўны масіў, у якім ключу Accent адпавядае значэнне Word, а ключу Initial – такі ж элемент, знойдзены ў KnownWords, пасля чаго перайсці да апрацоўкі наступнага Token альбо, калі апошні Token дасягнуты, – да кроку 3.2.
Калі ніводная з дадзеных умоў не выканана, дадаць у UniqueWords для Word пусты масіў.
Крок 3.2. Вызначыць пачатковую форму ўсіх слоў зыходнага тэксту (там, дзе гэта магчыма) з дапамогай функцыі вызначэння пачатковых форм.
Крок 3.3. Сфарміраваць вынік працы сэрвіса з дапамогай функцыі фарміравання выніку.
Крок 4. Прадставіць карыстальніку вынік працы сэрвіса.
Канец алгарытму.
Функцыя апрацоўкі параграфа
Уваходныя дадзеныя алгарытму:
- Параграф, атрыманы ў выніку раздзялення UText, Paragraph;
- Набор сімвалаў, з якіх можа складацца слова, Letters. Дадзены набор складаецца з асноўных кірылічных і лацінскіх сімвалаў;
- Набор сімвалаў рускага алфавіта, LettersRus;
- Набор сімвалаў беларускага алфавіта, LettersBel;
- Набор лацінскіх сімвалаў (сімвалаў ангельскага алфавіта), LettersLat;
- Набор усіх магчымых сімвалаў апострафа, ApostrophesArr;
- Набор сімвалаў асноўнага націску, AcuteAccentsArr;
- Набор сімвалаў пабочнага націску, GraveAccent;
- Набор сувязных сімвалаў, Linking;
- Карыстальніцкае значэнне раздзяляльніка, UserDelimiter;
- Пусты масіў для запісу токенаў, TokensArray.
Пачатак алгарытму.
Крок 1. Стварэнне пераменный MainChars і запіс у яе ўсіх сімвалаў Letters. Стварэнне пераменнай AdditionalChars і запіс у яе ўсіх сімвалаў AcuteAccentsArr, ApostrophesArr, GraveAccent, Linking, а таксама сімвалаў «=», «+», «-».
Крок 2. Стварэнне масіву WordsArr і запіс у яго ўсіх элементаў Paragraph, якія адпавядаюць шаблону [<Сімвал, які належыць MainChars> + <0 або больш сімвалаў MainChars і AdditionalChars> + <0 або больш сімвалаў MainChars>] (астатнія элементы Paragraph адкідаюцца і не ўдзельнічаюць у далейшай апрацоўцы). Кожны элемент масіву WordsArr, які атрымаўся ў выніку, будзе ўяўляць сабою масіў, у ячэйках якога раздзельна запісаныя слова і раздзяляльнік UserDelimiter.
Крок 3. Для кожнага WordArr у WordsArr выканаць крокі 3.1. – 3.3.
Крок 3.1. Стварэнне пераменнай Word і запіс у яе значэння ячэйкі WordArr, якая адпавядае слову. Стварэнне пераменнай Delimiter і запіс у яе значэння ячэйкі WordArr, якая адпавядае раздзяляльніку.
Крок 3.2. Нармалізацыя Word. Калі Word ≠ ∅, праверыць, ці сустракаецца ў Word хаця б адзін раз які-небудзь сімвал з набору LettersLat. Калі сустракаецца, праверыць таксама, ці сустракаецца ў Word які-небудзь сімвал з набораў LettersRus і LettersBel. Калі так, то запісаць у TokensArray асацыятыўны масіў, у якім ключу Initial адпавядае значэнне Word, ключу Normalized – значэнне Word, апрацаванае функцыяй нармалізацыі токенаў*, ключу Type – радок «word», ключу WritingSystem – радок «mixed». Калі не, то запісаць у TokensArray аналагічны масіў, але ў якім ключу WritingSystem адпавядае значэне «latin». Калі ж сімвалы з LettersLat не сустракаюцца ў Word ніводнага разу, запісаць у TokensArray аналагічны масіў, але ў якім ключу WritingSystem адпавядае значэнне «cyrillic».
* Функцыя нармалізацыі токенаў паслядоўна выконвае наступныя дзеянні:
- Прывядзенне токена да ніжняга рэгістра;
- Замена ўсіх сімвалаў з набору ApostrophesArr на сімвал «’»;
- Замена ўсіх сімвалаў з набору GraveAccent на сімвал «=»;
- Замена ўсіх сімвалаў з набору AcuteAccentsArr на сімвал «+».
Крок 3.3. Нармалізацыя Delimiter. Праверка ўмоў Delimiter ≠ ∅ і Delimiter ≠ «прабел». Калі абедзве ўмовы выконваюцца, праверыць, ці адпавядае хаця б частка Delimiter шаблону [<1 непрабельны сімвал або больш> АЛЬБО <1 прабельны сімвал або больш>]. Калі гэтая ўмова таксама выканана, запісаць усе супадзенні з шаблонам у масіў Matches, стварыць пераменную Cnt і запісаць у яе колькасць элементаў масіву Matches, пасля чаго для I = 0; I < Cnt; I++ выканаць крокі 3.3.1. – 3.3.2.
Крок 3.3.1. Калі Matches[I] ≠ ∅, інкрэментаваць I і праверыць умову Matches[I] ≠ ∅ яшчэ раз.
Крок 3.3.2. Калі I = 0 або I = Cnt – 1 і пры выкананні любой з гэтых умоў Word ≠ ∅, разбіць Matches[I] на масіў сімвалаў Chars і для кожнага Char у Chars запісаць у TokensArray асацыятыўны масіў, у які ключу Initial адпавядае Char, ключу Normalized – значэнне Char, апрацаванае функцыяй нармалізацыі токенаў, ключу Type – радковае значэнне «p». Калі ж абедзве першыя ўмовы не выкананыя, запісаць у TokensArray асацыятыўны масіў, у якім ключу Initial адпавядае Matches[I], ключу Normalized – значэнне Matches[I], апрацаванае функцыяй нармалізацыі токенаў, ключу Type – радковае значэнне «p».
Крок 4. Запісаць у TokensArray асацыятыўны масіў, у якім ключу Initial адпавядае радковае значэнне «\n», ключу Normalized – радковае значэнне «newline», ключу Type – радковае значэнне «p».
Канец алгарытму.
Функцыя вызначэння пачатковых форм
Уваходныя дадзеныя алгарытму:
- Масіў унікальных слоў, сфарміраваны ў асноўным алгарытме, UniqueWords;
- Пераменная для падліку запытаў да базы дадзеных, QueryCnt. Першапачаткова роўная
- Пераменная, якая вызначае ліміт запытаў да базы дадзеных, QueryLimit. Роўная 100.
- Пераменная для падліку апрацаваных унікальных слоў, UniqueWordsCnt. Першапачаткова роўная 0.
- Пераменная UniqueWordsTotal, роўная колькасці ўнікальных слоў у UniqueWords.
- Пусты масіў QueryWordsArr для наступнага запісу слоў, паводле якіх будзе ажыццяўляцца запыт да баз дадзеных слоўнікаў.
- Калекцыя слоўнікаў, выбраных карыстальнікам, Dictionaries.
Пачатак алгарытму.
Кожны крок дадзенага алгарытму выконваецца для кожнага UniqueWord у UniqueWords.
Крок 1. Калі QueryCnt ⩽ QueryLimit і UniqueWordsCnt ≠ UniqueWordsTotal, замяніць у бягучым UniqueWord усе пачатковыя сімвалы «Ў» і «ў» на сімвалы «У» и «у» адпаведна, выдаліць з UniqueWord усе сімвалы «=» і «+», запісаць у QueryWordsArr радок «word=’/UniqueWord/’» (неабходна для наступнага фарміравання карэктнага запыту да базы дадзеных), пасля чаго інкрэментаваць QueryCnt і UniqueWordsCnt.
Крок 2. Калі QueryCnt > QueryLimit альбо UniqueWordsCnt = UniqueWordsTotal, выканаць наступныя крокі алгарытму, інакш – перайсці да наступнага UniqueWord і пачаць алгарытм нанава.
Крок 3. Стварыць пераменную QueryWords і запісаць у яе значэнні ўсіх элементаў QueryWordsArr, раздзеленыя камбінацыяй <«пробел» + or + «пробел»>.
Крок 4. Калі QueryWords ≠ ∅, для кожнага Dictionary у Dictionaries выканаць крокі 4.1. – 4.2.
Крок 4.1. Сфарміраваць радок запыту Query выгляду «SELECT * FROM s1 WHERE s2», дзе s1 = Dictionary, s2 = QueryWords.
Крок 4.2. Калі паводле Query удалося што-небудзь знайсці ў бягучым Dictionary, то да таго часу, пакуль вынікі запыту можна парадкова запісваць у створаную для гэтага пераменную Row (г.зн. пакуль вынікі не вычарпаныя), выконваць крокі 4.2.1. – 4.2.4., пасля чаго вызваліць сістэмныя рэсурсы ад вынікаў запыту паводле Query.
Крок 4.2.1. Прывесці значэнне элемента Row[Word] да ніжняга рэгістра. Стварыць пераменную Initial і ініцыялізаваць яе значэннем «невядомаеСлова».
Крок 4.2.2. Калі Row[LexemeId] ≠ ∅, сфарміраваць радок запыту Query2 выгляду «SELECT * FROM s WHERE lexemeId = d LIMIT 1», дзе s = Dictionary, d = Row[LexemeId]. Калі паводле дадзенага запыту ў бягучым Dictionary удалося што-небудзь знайсці, то да таго часу, пакуль вынікі запыту можна парадкова запісваць у створаную для гэтага пераменную Row2, рэініцыялізаваць Initial значэннем Row2[Word], прыведзеным да ніжняга рэгістра. Як толькі праведзена апошняя рэініцыялізацыя, вызваліць сістэмныя рэсурсы, занятыя вынікамі запыту паводле Query2.
Крок 4.2.3. Калі Row[Initial] ≠ ∅, сфарміраваць радок запыту Query3 выгляду «SELECT * FROM s WHERE initial = d LIMIT 1», дзе s = Dictionary, d = Row[Initial]. Калі паводле дадзенага запыту ў бягучым Dictionary удалося што-небудзь знайсці, то да таго часу, пакуль вынікі запыту можна парадкова запісваць у створаную для гэтага пераменную Row3, рэініцыялізаваць Initial значэннем Row3[Word], прыведзеным да ніжняга рэгістра. Як толькі праведзена апошняя рэініцыялізацыя, вызваліць сістэмныя рэсурсы, занятыя вынікамі запыту паводле Query3.
Крок 4.2.4. Запісаць у UniqueWords для элемента Row[Word], якому адпавядае бягучы Dictionary, асацыятыўны масіў, у якім ключу Accent адпавядае значэнне Row[Accent], ключу Initial – значэнне аднайменнай пераменнай. Пры гэтым, калі Row[Word] пачынаецца на сімвал «у», а ў зыходным тэксце адпаведнае слова пачыналася на «ў», замяніць у Row[Word] і Row[Accent] пачатковыя сімвалы «у» на «ў».
Крок 5. Ачысціць QueryWordsArr і абнуліць QueryCnt для правядзення наступнай ітэрацыі.
Канец алгарытму.
Функцыя фарміравання выніку
Уваходныя дадзеныя алгарытму:
- Асацыятыўныя масівы TokensArray і UniqueWords з вынікамі папярэдняй апрацоўкі;
- Пусты масіў UnknownWordsArr для наступнага запісу невядомых слоў і дадзеных пра іх;
- Пустая пераменная UnknownWords для наступнага запісу невядомых слоў у радковым выглядзе;
- Пустая пераменная Result;
- Набор знакаў пунктуацыі Punctuation;
- Пераменная, якая змяшчае карыстальніцкі раздзяляльнік, LocalDelimiter;
- Карыстальніцкае значэнне опцыі, якая адказвае за адлюстраванне назваў слоўнікаў, DictionaryNamesFlag;
- Пераменныя GeneralDelimiter і MediumDelimiter, неабходныя для фарміравання канчатковага выніку згодна з патрабаваннямі карыстальніка.
| Значэнні пераменных GeneralDelimiter і MediumDelimiter у залежнасці ад опцыі, выбранай карыстальнікам | ||
| Опцыя | GeneralDelimiter | MediumDelimiter |
| «Паказваць вынік у зыходным фармаце» | «прабел» | ∅ |
| «Паказваць увесь вынік у адзін радок» | «прабел» | ∅ |
| «Паказваць вынікі радкамі» | \n* | ∅ |
| «Паказваць вынікі ў слупок» | \n\n | \n |
*\n – сімвал пераводу радка
Пачатак алгарытму.
Кожны крок дадзенага алгарытму выконваецца для кожнага Token у TokensArray.
Крок 1. Калі Token[Type] = «word» (г.зн. токен з’яўляецца словам), выканаць крокі 1.1. – 1.3.
Крок 1.1. Калі Token[WritingSystem] = «cyrillic», выканаць крокі 1.1.1. – 1.1.2.
Крок 1.1.1. Калі ў Token[Normalized] прысутнічае сімвал «+» альбо «=» (г.зн. у слове стаіць націск), выканаць крокі 1.1.1.1. – 1.1.1.3.
Крок 1.1.1.1. Стварыць пераменную Word і запісаць у яе значэнне Token[Normalized] з выдаленымі сімваламі націску.
Крок 1.1.1.2. Калі UniqueWords[Word] ≠ ∅ (г.зн. калі слова было знойдзена ў слоўніках, падключаных карыстальнікам), выканаць крокі 1.1.1.2.1. – 1.1.1.2.2.
Крок 1.1.1.2.1. Калі DictionaryNamesFlag = true, стварыць асацыятыўны масіў LocalResultsArr, пасля чаго для кожнай пары «ключ = DictionaryName, значэнне = DictionaryResults» у UniqueWords[Word] і для кожнага UniqueWordResultsArr у DictionaryResults праверыць наступныя ўмовы:
- Token[Normalized] роўны UniqueWordResultsArr[Accent];
- Token[Normalized] з выдаленымі сімваламі «=» і«+» роўны UniqueWordResultsArr[Accent];
- Token[Normalized] з сімваламі «=», замененымі на сімвалы «+», роўны UniqueWordResultsArr[Accent];
- Token[Normalized] з выдаленымі сімваламі «=» роўны UniqueWordResultsArr[Accent];
Калі хаця б адна з умоў выканана, дадаць у LocalResultsArr радок выгляду <UniqueWordResultsArr[Accent] + LocalDelimiter + UniqueWordResultsArr[Initial] + LocalDelimiter + DictionaryName>, пасля чаго прыбраць значэнні, якія паўтараюцца, з LocalResultsArr і дадаць да Result радок выгляду <Token[Initial] + MediumDelimiter + LocalDelimiter + [значэнні масіву LocalResultsArr, раздзеленыя камбінацыяй «MediumDelimiter + LocalDelimiter» і злучаныя ў радок]>.
Крок 1.1.1.2.2. Калі DictionaryNamesFlag = false, стварыць асацыятыўны масіў LocalResultsArr, пасля чаго для кожнага DictionaryResults у UniqueWords[Word] і для кожнага UniqueWordResultsArr у DictionaryResults праверыць умовы, аналагічныя тым, што апісаныя ў кроку 1.1.1.2.1., і, калі хаця б адна з умоў выканана, зрабіць значэнне LocalResultArr[UniqueWordResultsArr[Accent]][UniqueWordResultsArr[Initial]] роўным 1. Пасля гэтага дадаць да Result радок выгляду <Token[Itinial] + MediumDelimiter> і для кожнай пары «ключ = Accent, значэнне = Initials» у LocalResultsArr дадаць да Result радок выгляду <LocalDelimiter + Accent + LocalDelimiter + [набор ключоў масіву Initials, раздзеленых з дапамогай LocalDelimiter і злучаных у радок] + MediumDelimiter>.
Крок 1.1.1.3. Калі UniqueWords[Word] = ∅ (г.зн. слова не было знойдзена ў слоўніках, падключаных карыстальнікам), дадаць да Result радок выгляду <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «НевядомаеСлова»>, дадаць да UnknownWords радок выгляду <Token[Initial] + [сімвал пераводу радка]>, зрабіць значэнне элемента масіву UnknownWordsArr, які адпавядае Token[Initial], роўным 1.
Крок 1.1.2. Калі ў Token[Normalized] не прысутнічае сімвал «+» альбо «=» (г.зн. у слове не пастаўлены націск), стварыць пераменную Word, роўную Token[Normalized], і выканаць крокі, аналагічныя крокам 1.1.1.2. – 1.1.1.3., з той розніцай, што ў кроках, аналагічных 1.1.1.2.1. і 1.1.1.2.2., замест чатырох апісаных умоў правяраецца адзіная ўмова UniqueWordResultsArr[Accent] ≠ ∅.
Крок 1.2. Калі Token[WritingSystem] = «latin», дадаць да Result радок выгляду <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «ЗамежнаеНевядомае»>.
Крок 1.3. Калі Token[WritingSystem] = «mixed», дадаць да Result радок выгляду <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «ЗмешанаеНапісанне»>.
Крок 2. Калі Token[Type] = «p» (г.зн. токен з’яўляецца раздзяляльнікам), выканаць крокі 2.1. – 2.5.
Крок 2.1. Калі Token[Normalized] = «^», дадаць да Result радок выгляду <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized]>.
Крок 2.2. Калі Token[Normalized] ∈ Punctuation (г.зн. раздзяляльнік з’яўляецца знакам прыпынку), дадаць да Result радок выгляду <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «ЗнакПрыпынку»>.
Крок 2.3. Калі Token[Normalized] = «newline», дадаць да Result радок выгляду < MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «ПераводРадка»>. Калі пры гэтым карыстальнік абраў опцыю «Паказваць вынік у зыходным фармаце», дадаць да Result сімвал пераводу радка.
Крок 2.4. Калі Token[Normalized] з выдаленымі пачатковымі і канцавымі сімваламі водступу роўны чаму заўгодна, апроч ∅, дадаць да Result радок выгляду <Token[Initial] + MediumDelimiter + LocalDelimiter + Token[Normalized] + LocalDelimiter + «НевядомаяКатэгорыя»>.
Крок 2.5. Калі ніводная з умоў у кроках 2.1. – 2.4. не выканана, перайсці да апрацоўкі наступнага Token.
Крок 3. Дадаць да канчатковага выніку працы функцыі радок выгляду <Result + LocalDelimiter + MediumDelimiter> з выдаленымі пачатковымі і канцавымі прабеламі, пасля чаго дадаць GeneralDelimiter. Перайсці да апрацоўкі наступнага Token або, калі апошні Token ужо быў апрацаваны, завяршыць алгарытм.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Знешні выгляд карыстальніцкага інтэрфейсу сэрвіса прадстаўлены на малюнку 1.
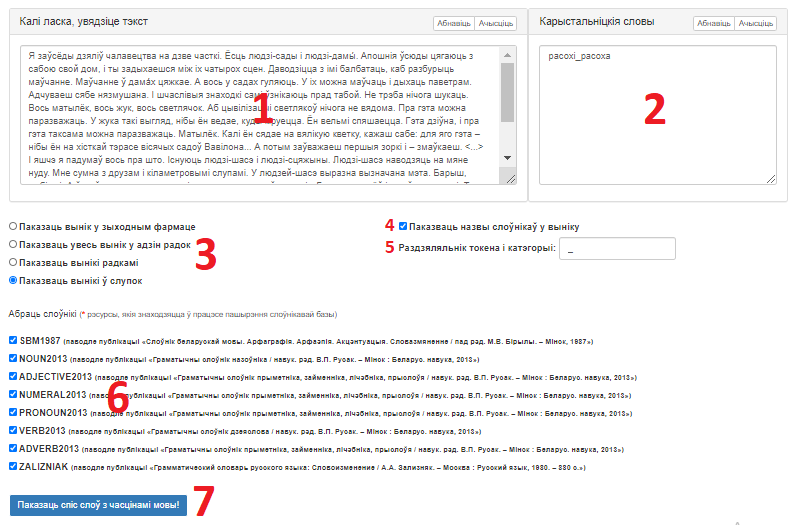
Малюнак 1 – Графічны інтэрфейс сэрвіса «Лематызатар»
Інтэрфейс мае наступныя вобласці:
- Поле ўводу тэксту для апрацоўкі. Забяспечана кнопкамі «Абнавіць» (вярнуць дадзеныя па змаўчанні) і «Ачысціць» (выдаліць усе дадзеныя);
- Поле ўводу вядомых слоў. Сюды павінны быць уведзены словы, пачатковая форма якіх вядомая карыстальніку (і, магчыма, невядомая сэрвісу) у фармаце [<словаформа> + <раздзяляльнік> + <пачатковая форма слова>]. Поле забяспечана кнопкамі «Абнавіць» і «Ачысціць»;
- Вобласць выбару фармату вынікаў працы сэрвіса. Змяшчае наступныя опцыі: «Паказваць вынік у зыходным фармаце», «Паказваць увесь вынік у адзін радок», «Паказваць вынікі радкамі», «Паказваць вынікі ў слупок»;
- Опцыя, якая адказвае за адлюстраванне для кожнай лемы назваў слоўнікаў, у якіх лема была знойдзена;
- Поле для ўказання раздзяляльніка;
- Вобласць выбару слоўнікаў, якія будуць задзейнічаныя ў апрацоўцы;
- Кнопка «Паказаць спіс слоў з часцінамі мовы!», якая запускае апрацоўку і дазваляе атрымаць вынік.
Пасля націскання кнопкі «Паказаць спіс слоў з часцінамі мовы!» ўнізе экрана з’явяцца два палі, якія змяшчаюць вынікі апрацоўкі:
- Поле «Словы з часцінамі мовы», у якім у выбраным карыстальнікам фармаце выводзяцца словаформы, іх лемы і назвы слоўнікаў, у якіх лемы былі знойдзеныя (калі карыстальнік актываваў адпаведную опцыю);
- Поле «Невядомыя словы», што змяшчае словы, якія сэрвісу не ўдалося апрацаваць.
Карыстальніцкія сцэнарыі працы з сэврісам
Сцэнар 1. Апрацоўка з вывадам вынікаў у зыходным фармаце.
- Увесці тэкст для апрацоўкі ў поле ўводу тэксту.
- Увесці сімвал або камбінацыю сімвалаў, якія будуць выкарыстоўвацца ў якасці раздзяляльніка, у поле для ўводу раздзяляльніка.
- Увесці вядомыя лемы ў фармаце [<словаформа> + <раздзяляльнік> + <пачатковая форма слова>].
- У вобласці выбару фармату вываду вынікаў выбраць опцыю «Паказваць вынік у зыходным фармаце».
- Вызначыць неабходнасць вываду назваў слоўнікаў, у якіх былі знойдзеныя лемы, з дапамогай адпаведнай опцыі.
- У вобласці выбару слоўнікаў выбраць слоўнікі, якія будуць задзейнічаныя ў апрацоўцы.
- Націснуць кнопку «Паказаць спіс слоў з часцінамі мовы!».
- Атрымаць вынік апрацоўкі (словаформы і іх лемы, а таксама спіс невядомых сэрвісу слоў) у палях, якія з’явяцца ўнізе экрана.
Магчымы вынік працы сэрвіса згодна з дадзеным сцэнарыем прадстаўлены на малюнку 2.
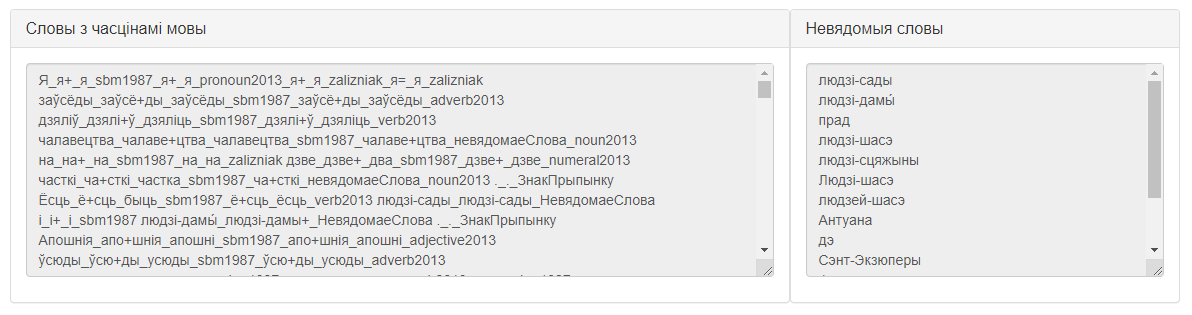
Малюнак 2 – Вынік працы сэрвіса «Лематызатар» згодна са сцэнарыем 1
Сцэнарый 2. Апрацоўка з вывадам вынікаў у адзін радок, радкамі або ў слупок.
- Увесці тэкст для апрацоўкі ў поле ўводу тэксту.
- Увесці сімвал або камбінацыю сімвалаў, якія будуць выкарыстоўвацца ў якасці раздзяляльніка, у поле для ўводу раздзяляльніка
- Увесці вядомыя лемы ў фармаце [<словаформа> + <раздзяляльнік> + <пачатковая форма слова>].
- У вобласці выбару фармату вываду вынікаў у залежнасці ад канкрэтнай неабходнасці выбраць адну з наступных опцый: «Паказваць увесь вынік у адзін радок», «Паказваць вынікі радкамі», «Паказваць вынікі ў слупок».
- Вызначыць неабходнасць вываду назваў слоўнікаў, у якіх былі знойдзеныя лемы, з дапамогай адпаведнай опцыі.
- У вобласці выбару слоўнікаў выбраць слоўнікі, якія будуць задзейнічаныя ў апрацоўцы.
- Націснуць кнопку «Паказаць спіс слоў з часцінамі мовы!».
- Атрымаць вынік апрацоўкі (словаформы і іх лемы, а таксама спіс невядомых сэрвісу слоў) у палях, якія з’явяцца ўнізе экрана.
Магчымы вынік працы сэрвіса згодна з дадзеным сцэнарыем прадстаўлены на малюнку 3.
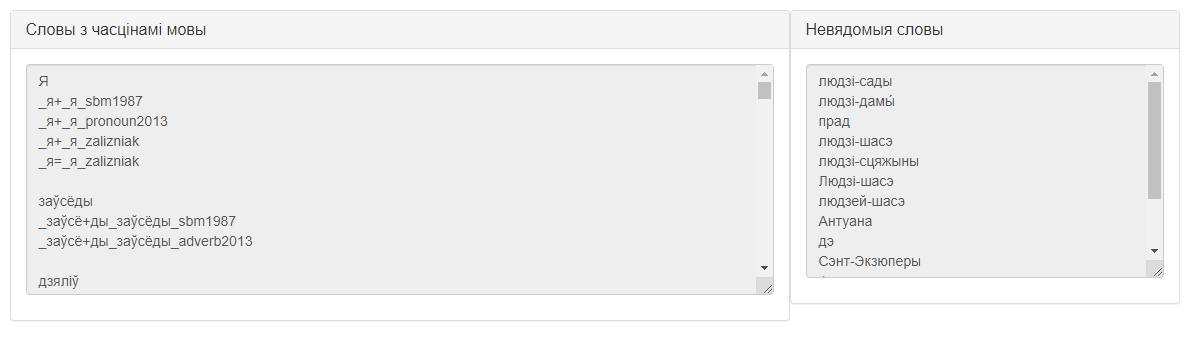
Малюнак 3 – Вынік працы сэрвіса «Лематызатар» згодна са сцэнарыем 2
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Лематызатар» праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/Lemmatizer/api.php. Праз масіў data перадаюцца наступныя параметры:
- text – адвольны ўваходны тэкст на беларускай або рускай мове.
- knownList – спіс слоў з вызначанымі карыстальнікам пачатковымі формамі.
- localDelimiter – раздзяляльнік выніковай інфармацыі – сімвал, які будзе раздзяляць слова, яго пачатковую форму і назву слоўніка ў выніковым спісе.
- dictionaryNames – маркер неабходнасці ўказання слоўнікаў, з якіх узятая інфармацыя.
- horizontalFormat – маркер неабходнасці выдачы ўсёй выніковай інфармацыі ў адзін радок; калі маркер не адзначаны, то інфармацыя па кожным слове размяшчаецца ў асобных радках.
- Маркеры выкарыстання слоўнікаў:
- sbm1987 – «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987».
- noun2013 – назоўнікі, згодна з выданнем «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- adjective2013 – прыметнікі, згодна з выданнем «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- numeral2013 – лічэбнікі, згодна з выданнем «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П.Русак. – Мінск : Бел. навука, 2013».
- pronoun2013 – займеннікі, згодна з выданнем «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- verb2013 – дзеясловы, згодна з выданнем «Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Бел. навука, 2013».
- adverb2013 – прыслоўі, згодна з выданнем «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П.Русак. – Мінск : Бел. навука, 2013».
- zalizniak – «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. – Москва : Русский язык, 1980. – 880 c.».
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/Lemmatizer/api.php”,
data:{
“text”: “Груша цвіла апошні год. Усе галіны яе, усе вялікія расохі, да апошняга пруціка, былі ўсыпаны буйным бела-ружовым цветам.”,
“knownList“: “расохі_расоха”,
“localDelimiter”: “|”,
“dictionaryNames”: 1,
“horizontalFormat”: 0,
“sbm1987”: 1
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з уваходным тэкстам (параметр text), выніковым спісам слоў з інфармацыяй пра іх пачатковыя формы (параметр result) і спіс невядомых сэрвісу слоў (параметр unknownWords). Напрыклад, паводле прыведзенага вышэй AJAX-запыту будзе сфарміраваны наступны адказ:
[
{
“text”: “Груша цвіла апошні год. Усе галіны яе, усе вялікія расохі, да апошняга пруціка, былі ўсыпаны буйным бела-ружовым цветам.”,
“result”: “гру+ша|груша|sbm1987
цвіла+|цвісці|sbm1987
апо+шні|апошні|sbm1987|апо+шні|апошні|sbm1987
го+д|год|sbm1987|го+д|год|sbm1987
.|ЗнакПрыпынку
усе+|увесь|sbm1987|усе+|увесь|sbm1987
галі+ны|галіна|sbm1987|галі+ны|галіна|sbm1987|галі+ны|галіна|sbm1987|галіны+|галіна|sbm1987|галі+ны|галіна|sbm1987|галі+ны|галіна|sbm1987
яе+|ён|sbm1987|яе+|ён|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987|яе+|яго|sbm1987
,|ЗнакПрыпынку
усе+|увесь|sbm1987|усе+|увесь|sbm1987
вялі+кія|вялікі|sbm1987|вялі+кія|вялікі|sbm1987
расохі|расоха|known
,|ЗнакПрыпынку
да+|да|sbm1987|да+|да|sbm1987
апо+шняга|апошні|sbm1987|апо+шняга|апошні|sbm1987|апо+шняга|апошні|sbm1987
пруціка|НевядомаеСлова
,|ЗнакПрыпынку
бы+лі|быль|sbm1987|бы+лі|быль|sbm1987|бы+лі|быль|sbm1987|бы+лі|быль|sbm1987|бы+лі|быль|sbm1987|былі+|быць|sbm1987
ўсы+паны|усыпаны|sbm1987|ўсы+паны|усыпаны|sbm1987|ўсы+паны|усыпаны|sbm1987|ўсы+паны|усыпаны|sbm1987
буйны+м|буйны|sbm1987|буйны+м|буйны|sbm1987|буйны+м|буйны|sbm1987|буйны+м|буйны|sbm1987|буйны+м|буйны|sbm1987
бе=ла-ружо+вым|бела-ружовы|sbm1987|бе=ла-ружо+вым|бела-ружовы|sbm1987|бе=ла-ружо+вым|бела-ружовы|sbm1987|бе=ла-ружо+вым|бела-ружовы|sbm1987|бе=ла-ружо+вым|бела-ружовы|sbm1987
цве+там|цвет|sbm1987|цве+там|цвет|sbm1987
.|ЗнакПрыпынку”,
“unknownWords”: “пруціка”
}
]
Спасылкі на крыніцы
Старонка сэрвіса – https://corpus.by/Lemmatizer/