Сэрвіс «Вызначэнне мовы тэксту» прызначаны для вызначэння мовы пададзенага на ўваход адвольнага тэксту. На дадзены момант сэрвіс распазнае 5 моў: беларускую, рускую, украінскую, ангельскую і нямецкую.
Асноўныя тэрміны і паняцці
Ідэнтыфікацыя мовы (або ўгадванне мовы) – праблема, якая адносіцца да сферы апрацоўкі тэкстаў на натуральнай мове і заключаецца ў вызначэнні таго, на якой мове прадстаўлены кантэнт. У рамках тэхналогій, якія прымяняюць вылічальныя падыходы, дадзеная праблема разглядаецца як асаблівы выпадак катэгарызацыі тэксту і вырашаецца рознымі статыстычнымі метадамі.
Практычная каштоўнасць
Праблема папярэдняга аўтаматычнага вызначэння мовы тэксту стаіць перад многімі сучаснымі дадаткамі, якія займаюцца апрацоўкай і перапрацоўкай тэксту – напрыклад, сістэмамі машыннага перакладу, рознымі праграмамі для парсінгу, сістэмамі сінтэзу маўлення. Правільнае распазнаванне хаця б асноўнай мовы значна эканоміць рэсурсы падобных сістэм, павышае іх прадукцыйнасць, карэктуе працу алгарытмаў.
Рашэнне праблемы распазнавання мовы тэксту вельмі запатрабаванае ў інтэрнэце. Асабліва гэта тычыцца ідэнтыфікацыі мовы карыстальніка, паколькі такая ідэнтыфікацыя, разам з тэхналогіяй геалакацыі, дазваляе здзейсніць тонкую наладку сайта або дадатка пад патрэбы карыстальніка, зрабіць кантэнт максімальна зразумелым і даступным. Наш сэрвіс мае доступ праз API, што робіць яго добрым памочнікам для вэб-распрацоўшчыка.
Асаблівасці сэрвіса
Вызначэнне мовы тэксту ажыццяўляецца сэрвісам з дапамогай статыстычнага метаду і метаду прымянення правіл. Прыярытэтнасць статыстыкі над правіламі або правіл над статыстыкай вызначаецца становішчам спецыяльнай пераменнай-тумблера. Магчымасць змянення становішча дадзенага тумблера на дадзены момант схаваная ад карыстальніка, аднак пры неабходнасці яна заўжды можа быць задзейнічана распрацоўшчыкам. Гэтак жа лёгка можа быць зменены парог адчувальнасці алгарытму, мінімальная і максімальная колькасць сімвалаў тэксту, які падлягае апрацоўцы (для забеспячэння прадукцыйнасці да дадзены момант гэтыя параметры роўныя 80 і 1680 адпаведна).
У планах па развіцці сэрвіса – магчымасць вызначэння некалькіх моў мультымоўнага тэксту і выдача статыстыкі па выкарыстанні кожнай асобнай мовы, пашырэнне моўнай палітры, прымяненне новых правіл ідэнтыфікацыі.
Алгарытм працы сэрвіса
Асноўны алгарытм
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, Text;
- Мінімальная даўжыня тэкставага ўводу, MinLength. Роўная 80 сімвалам;
- Максімальная даўжыня тэкставага ўводу, MaxLength. Роўная 1680 сімвалам;
- Пераменная-тумблер, якая адказвае за выкарыстанне дадатковай сістэмы правіл і выключэнняў, UseRules. Роўная false;
- Пераменная-тумблер, якая адказвае за прымяненне ў працы з тэкстам толькі правіл (без статыстыкі), UseRulesOnly. Роўная false;
- Пераменная-тумблер, якая адказвае за прыярытэт правіл над статыстыкай, UseRulesPriory. Роўная true.
Пачатак алгарытму.
Крок 1. Праверка ўмовы Text = ∅. Калі ўмова правільная, завяршыць алгарытм з вынікам false.
Крок 2.1. Выдаленне пачатковых і канцавых прабелаў з Text, вызначэнне кадзіроўкі тэксту.
Крок 2.2. Калі даўжыня Text большая за MaxLength, выдаліць з Text усе сімвалы, якія ідуць пасля сімвала пад нумарам MaxLength. Інакш, калі даўжыня Text меншая за MinLength, завяршыць алгарытм з вынікам false.
Крок 2.3. Ператварыць усе сімвалы Text у сімвалы кадзіроўкі UTF-8 і прывесці іх да ніжняга рэгістра.
Крок 3.1. Калі UseRulesOnly = true, прымяніць да Text функцыю вызначэння мовы паводле правіл, запісаць вынік працы функцыі ў пераменную Res, выдаць карыстальніку значэнне пераменнай Res і завяршыць алгарытм. Інакш – перайсці да наступнага кроку.
Крок 3.2. Прымяніць да Text функцыю статыстычнага вызначэння мовы, запісаць вынік працы функцыі ў пераменную Res.
Крок 3.3. Калі UseRules=true, здзейсніць наступныя крокі алгарытму. Інакш – выдаць карыстальніку значэнне пераменнай Res і завяршыць алгарытм.
Крок 3.4. Прымяніць да Text функцыю вызначэння мовы паводле правіл, запісаць вынік працы функцыі ў пераменную ResRules.
Крок 3.5. Калі UseRulesPriory = true, выдаць карыстальніку значэнне пераменнай ResRules і завяршыць алгарытм. Інакш – выдаць карыстальніку значэнне пераменнай Res і завяршыць алгарытм.
Канец алгарытму.
Функцыя вызначэння мовы паводле правіл
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, апрацаваны ў кроках 2.1. – 2.3. асноўнага алгарытму, Text;
- Двухмерная матрыца правіл для кожнай мовы, LangRules. Кожны радок матрыцы змяшчае сімвал або камбінацыю сімвалаў, якія характэрныя для той ці іншай мовы;
- Пераменная-тумблер, якая адказвае за неабходнасць адпаведнасці тэксту ўсім правілам пры вызначэнні мовы тэксту паводле правіл, MatchAllRules. Роўная true.
Пачатак алгарытму.
Крок 1. Праверка ўмоў Text = ∅ і LangRules = ∅. Калі хаця б адна з умоў выканана, завяршыць алгарытм з вынікам false.
Крок 2. Для кожнага радка матрыцы LangRules выканаць крокі 2.1. – 2.2.
Крок 2.1. Стварыць пераменную Freq для падліку выкананых правіл (гэта значыць выпадкаў знаходжання патрэбных сімвалаў або камбінацый сімвалаў у радку) і ініцыялізаваць значэннем 0.
Крок 2.2. Для кожнага правіла Rule у кожным радку матрыцы LangRules выканаць крокі 2.2.1. – 2.2.3.
Крок 2.2.1. Стварыць пераменную Term і запісаць у яе колькасць уваходжанняў у Text сімвала або камбінацыі сімвалаў, якія адпавядаюць правілу Rule.
Крок 2.2.2. Калі Term > 1, інкрэментаваць Freq.
Крок 2.2.3. Калі MatchAllRules=true, праверыць, ці роўнае значэнне Freq колькасці Rules для дадзенага радка матрыцы LangRules. Калі роўнае, вярнуць назву бягучага радка матрыцы LangRules (г. зн. назву мовы) і завяршыць алгарытм. Інакш – праверыць умову Freq > 0. Калі ўмова правільная, вярнуць назву бягучага радка матрыцы LangRules і завяршыць алгарытм.
Крок 3. Калі ў кроку 2 не адбылося звароту выніку, завяршыць алгарытм з вынікам false.
Канец алгарытму.
Функцыя статыстычнага вызначэння мовы тэксту
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, апрацаваны ў кроках 2.1. – 2.3. асноўнага алгарытму, Text;
- Двухмерная матрыца, кожны радок якой змяшчае ўсе сімвалы алфавіту пэўнай мовы, Langs;
- Двухмерная матрыца для запісу вынікаў працы функцыі для кожнай асобнай мовы, LangRes;
- Парог адчувальнасці, DetectRange. Роўны 75;
- Пераменная-тумблер UseStrLenPerLang. Калі роўная true, агульная колькасць сімвалаў алфавіта, якія сустрэліся ў Text, будзе прыярытэтнейшая за суадносіны колькасці сімвалаў, якія сустрэліся, да агульнай колькасці сімвалаў алфавіта мовы, калі роўная false, то наадварот. Роўная true;
- Пераменная-тумблер ReturnAllResults, якая адказвае за зварот выніку аналізу ўсіх моў замест звароту найлепшага выніку. Роўная false.
Пачатак алгарытму.
Крок 1. Калі Text = ∅, завяршыць алгарытм з вынікам false.
Крок 2. Для кожнага радка Lang матрыцы Langs выканаць крокі 2.1. – 2.3.
Крок 2.1. Запісаць у радок LangRes, які адпавядае Lang, значэнне 0. Стварыць пераменную Freq для наступнага запісу колькасці сімвалаў мовы, якія сустрэліся ў Text адзін ці больш разоў, і ініцыялізаваць яе значэннем 0. Стварыць пераменную FullLangSymbols для наступнага запісу агульнай колькасці ўваходжанняў сімвалаў мовы ў Text і ініцыялізаваць яе значэннем 0. Стварыць масіў CurLang і запісаць у яго ўсе сімвалы алфавіта бягучай мовы (якая адпавядае Lang).
Крок 2.2. Для кожнага сімвала LangItem масіву CurLang выканаць крокі 2.2.1. – 2.2.2.
Крок 2.2.1. Стварыць пераменную Temp і запісаць у яе агульную колькасць уваходжанняў сімвала LangItem у Text.
Крок 2.2.2. Калі Temp > 1, інкрэментаваць Freq і павялічыць значэнне FullLangSymbols на велічыню Temp.
Крок 2.3. Калі UseStrLenPerLang = true, запісаць у радок матрыцы LangRes, які адпавядае бягучай мове, значэнне FullLangSymbols, інакш – запісаць у радок матрыцы LangRes, які адпавядае бягучай мове, акругленае ў большы бок значэнне, вылічанае паводле формулы:
[значэнне] = (100 / [колькасць сімвалаў алфавіта CurLang]) * Freq.
Крок 3. Адсартаваць матрыцу LangRes паводле змяншэння значэнняў, запісаных у кроку 2.3.
Крок 4. Калі ReturnAllResults = true, вярнуць усю матрыцу LangRes і завяршыць алгарытм. Інакш – праверыць умову [значэнне верхняга элемента LangRes] ⩾ DetectRange. Калі ўмова правільная, вярнуць назву мовы, якая адпавядае верхняму радку матрыцы LangRes і завяршыць алгарытм, інакш – вярнуць null і завяршыць алгарытм.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Знешні выгляд інтэрфейсу сэрвіса прадстаўлены на малюнку 1.
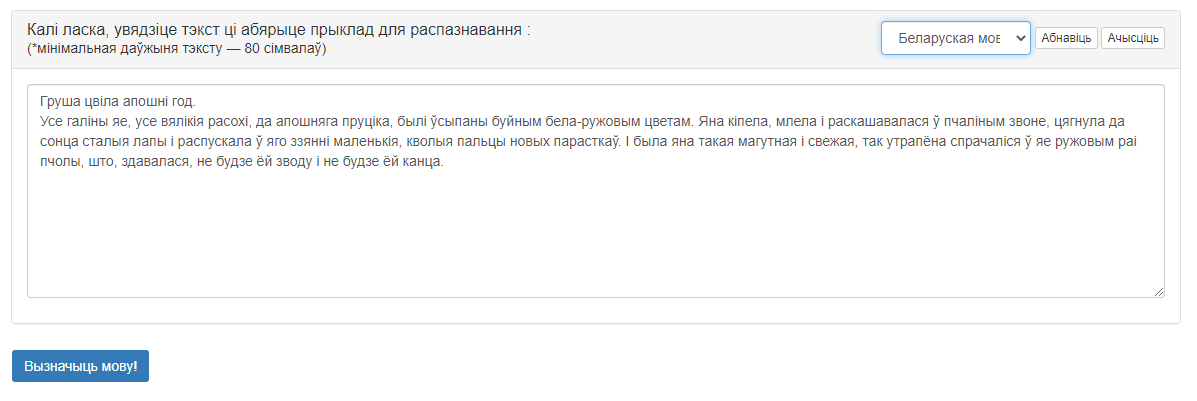
Малюнак 1 – Графічны інтэрфейс сэрвіса «Вызначэнне мовы тэксту»
Інтэрфейс мае наступныя вобласці:
- Выпадальнае меню для выбару прыкладу тэксту на адной з моў;
- Поле ўводу тэксту для распазнавання. Поле забяспечана кнопкамі «Абнавіць» (запаўненне згодна з выбраным пунктам выпадальнага меню) і «Ачысціць» (выдаленне ўсіх дадзеных);
- Кнопка «Вызначыць мову!», якая запускае апрацоўку і дазваляе атрымаць вынік.
Пасля націскання на кнопку «Вызначыць мову!» унізе экрана з’яўляецца поле выдачы вынікаў апрацоўкі.
Карыстальніцкія сцэнарыі працы з сэрвісам
Сцэнарый 1. Вызначэнне мовы тэставага тэксту
- Выбраць тэставы тэкст з дапамогай выпадальнага меню. У выпадку непажаданага змянення зместу тэкставага поля націснуць кнопку «Абнавіць».
- Націснуць кнопку «Вызначыць мову!».
- Атрымаць вынік (назву вызначанай мовы) у полі выдачы вынікаў.
Сцэнарый 2. Вызначэнне мовы карыстальніцкага тэксту
- Націснуць кнопку «Ачысціць» для ачысткі поля ўводу альбо ачысціць поле ўводу ўручную.
- Увесці тэкст у поле ўводу.
- Націснуць кнопку «Вызначыць мову!».
- Атрымаць вынік (назву вызначанай мовы) у полі выдачы вынікаў.
Магчымы вынік працы сэрвіса згодна з прапанаванымі сцэнарыямі прадстаўлены на малюнку 2.

Малюнак 2 – Вынік працы сэрвіса «Вызначэнне мовы тэксту»
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Вызначэнне мовы тэксту» праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/LanguageIdentifier/api.php. Праз масіў data перадаюцца наступныя параметры:
- text – адвольны ўваходны тэкст памерам ад 80 сімвалаў.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/LanguageIdentifier/api.php”,
data:{
“text”: “Had I the heavens’ embroidered cloths,
Enwrought with golden and silver light,
The blue and the dim and the dark cloths
Of night and light and the half-light,
I would spread the cloths under your feet:
But I, being poor, have only my dreams;
I have spread my dreams under your feet;
Tread softly because you tread on my dreams.”
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з уваходным тэкстам (параметр text) і кодам вызначанай мовы (параметр result). Напрыклад, паводле прыведзенага вышэй AJAX-запыту будзе сфарміраваны наступны адказ:
[
{
“text”: “Had I the heavens’ embroidered cloths,
Enwrought with golden and silver light,
The blue and the dim and the dark cloths
Of night and light and the half-light,
I would spread the cloths under your feet:
But I, being poor, have only my dreams;
I have spread my dreams under your feet;
Tread softly because you tread on my dreams.”,
“result”: “en”
}
]
Спасылкі на крыніцы
Старонка сэрвіса – https://corpus.by/LanguageIdentifier/