Сэрвіс «Распазнаванне дыктараў» вызначае найбліжэйшую мадэль дыктара, наяўную ў базе дадзеных, аналізуючы аўдыядадзеныя, выбраныя або прапанаваныя карыстальнікам. Прыватным выпадкам выкарыстання сэрвіса з’яўляецца магчымасць дадаць уласную мадэль дыктара для наступнага параўнання параметраў аўдыяфайлаў з параметрамі дадзенай мадэлі.
Асноўныя тэрміны і паняцці
Распазнаванне маўлення – аўтаматычны працэс пераўтварэння маўленчага сігналу ў лічбавую інфармацыю.
Распазнаванне па голасе – адна з форм біяметрычнай аўтэнтыфікацыі, якая дазваляе ідэнтыфікаваць асобу чалавека паводле сукупнасці ўнікальных характарыстык голасу. Адносіцца да дынамічных метадаў біяметрыі. Аднак, паколькі голас чалавека можа змяняцца ў залежнасці ад узросту, эмацыянальнага стану, здароўя, гарманальнага фону і цэлага шэрагу іншых фактараў, дадзены метад не з’яўляецца абсалютна дакладным.
Мадэль гаворачага – сукупнасць унікальных статыстычных і біяметрычных характарыстык голасу, атрыманая шляхам аналізу аўдыядадзеных, запісаных гаворачым. Можа ўключаць звесткі пра агульную манеру маўленчых паводзін.
Акустычная мадэль распазнавання маўлення – функцыя, якая прымае на ўваход невялікі ўчастак акустычнага сігналу (кадр) і выдае размеркаванне верагоднасцей розных фанем на гэтым кадры.
Практычная каштоўнасць
Праца сэрвіса з’яўляецца нагляднай дэманстрацыяй сучасных магчымасцей распазнавання мадэлі гаворачага. Магчымасць распазнаць такую мадэль адкрывае новыя перспектывы для шматлікіх галін чалавечай дзейнасці – перш за ўсё тых, што звязаныя з ідэнтыфікацыяй дадзеных і абаронай інфармацыі.
Тэхналогіі, падобныя да нашай, знаходзяць усё большае прымяненне ў крыміналістыцы – напрыклад, у фонаскапічнай экспертызе. Разнастайныя падраздзяленні сучасных банкаў (ад кол-цэнтраў да сістэм абароны персанальных дадзеных) выкарыстоўваюць галасавыя біяметрычныя тэхналогіі для ідэнтыфікацыі кліентаў і прафілактыкі махлярства.
Магчымасць распазнавання мадэлі гаворачага можа быць прыменена і ў навуковых і навукова-вытворчых галінах, у прыватнасці, у рабататэхніцы. З дапамогай ідэнтыфікацыйнай сістэмы робат можа «адрозніць» голас «гаспадара» ад іншых галасоў для выстаўлення прыярытэту вусных каманд.
Асаблівасці сэрвіса
На дадзены момант сэрвіс не валодае шырокай базай мадэляў дыктараў, аднак сістэмы, якія ім выкарыстоўваюцца, натрэніраваныя дастаткова, каб суаднесці мадэль гаворачага з наяўнымі прататыпамі і прапанаваць найбольш блізкі з іх. Акрамя таго, любы карыстальнік можа папоўніць базу сэрвіса, начытаўшы прапанаваныя тэксты праз мікрафон камп’ютара.
Распазнаванне маўлення, якое ажыццяўляецца сэрвісам у працэсе супастаўлення мадэляў, працуе на базе папулярнай праграмы Kaldi з адкрытым зыходным кодам. Згодна з артыкулам «Сравнительный анализ систем распознавания речи с открытым кодом», апублікаваным у 2017 годзе ў выданні «Міжнародны навукова-даследчы часопіс», сістэма Kaldi мае найвышэйшую дакладнасць распазнавання сярод усіх сістэм, прааналізаваных аўтарамі (Kaldi, CMU Sphinx, HTK, Julius, Iatros, RWTH ASR).
Алгарытм работы сэрвіса
Уваходныя дадзеныя алгарытму:
- Аўдыяфайл для аналізу (файл з базы сэрвіса, загружаны або запісаны карыстальнікам), Audio;
- Мадэлі дыктараў, Models;
- Алгарытмы распазнавання маўлення сістэмы Kaldi, KaldiSRA (Speech Recognition Algorithms);
- Алгарытмы пабудовы акустычнай мадэлі гаворачага сістэмы Kaldi, KaldiSAMC (Speaker Acoustic Model Construction).
Пачатак алгарытму.
Крок 1. Загрузка, выбар або запіс з дапамогай мікрафона аўдыёзапісу Audio.
Крок 2. Распазнанне асобных фанем у Audio з дапамогай KaldiSRA.
Крок 3. Пабудова згодна з акустыка-частотнымі параметрамі Audio статыстычнай біяметрычнай мадэлі дыктара SpeakerModel з дапамогай KaldiSAMC.
Крок 4. Параўнанне SpeakerModel з наяўнымі ў базе дадзеных сэрвіса мадэлямі дыктараў Models, выбар той мадэлі, матэматычная адлегласць да якой карацейшая.
Крок 5. Выдача назвы найбліжэйшай мадэлі дыктара карыстальніку.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Графічны карыстальніцкі інтэрфейс уяўляе сабой акно для працы з сэрвісам, якое мае 5 укладак: «Прыклад», «Дыктары», «Запісаць», «Загрузіць файл», «Дабавіць сябе».
1) Укладка «Прыклад»
Знешні выгляд акна ўкладкі «Прыклад» прадстаўлены на малюнку 1.
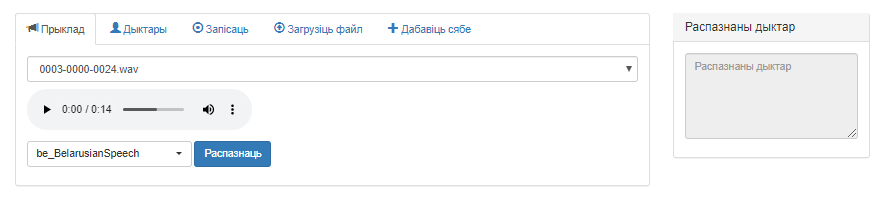
Малюнак 1 – Карыстальніцкі інтэрфейс сэрвіса «Распазнаванне дыктараў», укладка «Прыклад»
Акно змяшчае наступныя элементы:
- Выпадальнае меню выбару аўдыёфайлаў;
- Аўдыяплэер для прайгравання выбранага файла;
- Выпадальнае меню для пераключэння паміж раздзеламі базы дадзеных сэрвіса;
- Кнопка «Распазнаць», якая запускае работу сэрвіса;
- Поле «Распазнаны дыктар», у якім адлюстроўваюцца вынікі работы сэрвіса.
2) Укладка «Дыктары»
Знешні выгляд акна ўкладкі «Дыктары» прадстаўлены на малюнку 2.
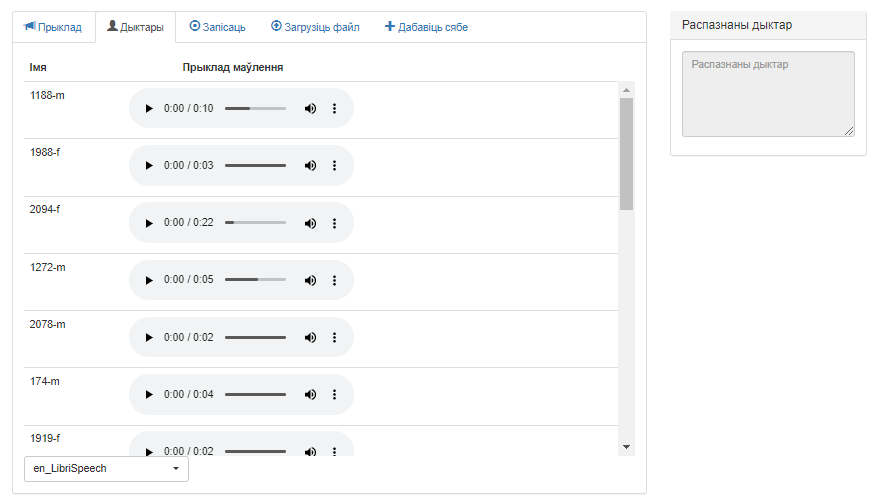
Малюнак 2 – Карыстальніцкі інтэрфейс сэрвіса «Распазнаванне дыктараў», укладка «Дыктары»
Акно змяшчае наступныя элементы:
- Табліца, кожны радок якой змяшчае «імя» дыктара і плэер для прайгравання аўдыёзапісу прыкладу яго маўлення;
- Выпадальнае меню для пераключэння паміж раздзеламі базы дадзеных сэрвіса;
- Поле «Распазнаны дыктар».
3) Укладка «Запісаць»
Знешні выгляд акна ўкладкі «Запісаць» прадстаўлены на малюнку 3.
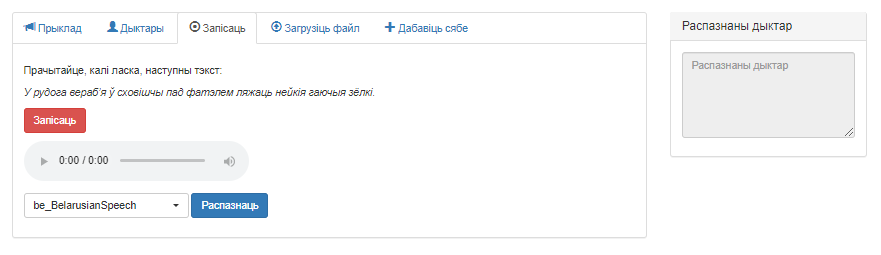
Малюнак 3 – Карыстальніцкі інтэрфейс сэрвіса «Распазнаванне дыктараў», укладка «Запісаць»
Акно змяшчае наступныя элементы:
- Кнопка «Запісаць» для стварэння аўдыязапісу з дапамогай мікрафона камп’ютара (пасля націскання ператвараецца ў кнопку «Стоп»);
- Аўдыяплэер для ўзнаўлення запісанага аўдыяфайла;
- Выпадальнае меню для пераключэння паміж раздзеламі базы дадзеных сэрвіса;
- Кнопка «Распазнаць», якая запускае работу сэрвіса;
- Поле «Распазнаны дыктар», у якім адлюстроўваюцца вынікі работы сэрвіса.
4) Укладка «Загрузіць файл»
Знешні выгляд акна ўкладкі «Загрузіць файл» прадстаўлены на малюнку 4.
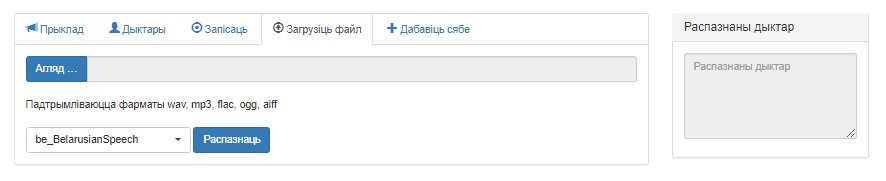
Малюнак 4 – Карыстальніцкі інтэрфейс сэрвіса «Распазнаванне дыктараў», укладка «Загрузіць файл»
Акно змяшчае наступныя элементы:
- Кнопка «Агляд…» для выбару файла для загрузкі з камп’ютара карыстальніка;
- Поле для вываду імені файла;
- Выпадальнае меню для пераключэння паміж раздзеламі базы дадзеных сэрвіса;
- Кнопка «Распазнаць», якая запускае работу сэрвіса;
- Поле «Распазнаны дыктар», у якім адлюстроўваюцца вынікі работы сэрвіса.
5) Укладка «Дабавіць сябе»
Знешні выгляд акна ўкладкі «Дабавіць сябе» прадстаўлены на малюнку 5.
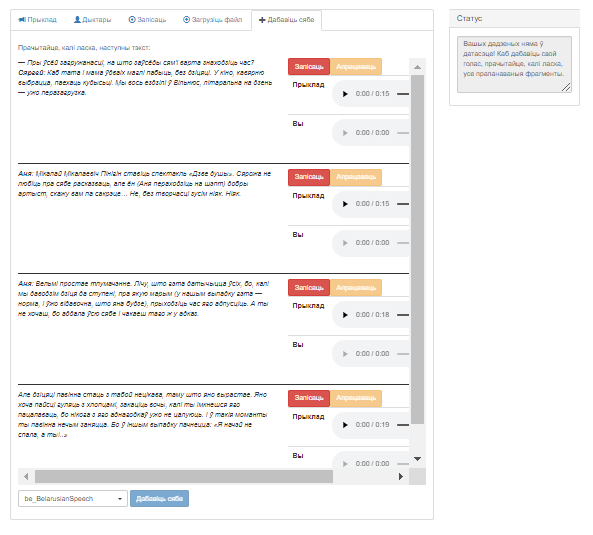
Малюнак 5 – Карыстальніцкі інтэрфейс сэрвіса «Распазнаванне дыктараў», укладка «Дабавіць сябе»
Акно змяшчае наступныя элементы:
- Табліца з тэкстамі для запісу. Кожны радок табліцы змяшчае наступныя элементы:
- Тэкст для запісу;
- Кнопка «Запісаць» для пачатку запісу аўдыя (пасля націскання ператвараецца ў кнопку «Стоп»);
- Кнопка «Апрацаваць» для запуску апрацоўкі запісанага аўдыяматэрыялу;
- Аўдыяплэер для прайгравання прыкладу аўдыязапісу тэксту;
- Аўдыяплэер для прайгравання карыстальніцкага аўдыязапісу.
- Выпадальнае меню для пераключэння паміж раздзеламі базы дадзеных сэрвіса (размешчана ўнізе ўкладкі);
- Кнопка «Дабавіць сябе» для дадавання карыстальніцкіх дадзеных у абраны раздзел базы дадзеных сэрвіса;
- Поле «Статус», у якім адлюстроўваецца бягучая інфармацыя пра стан працэсу ўзаемадзеяння карыстальніка з сэрвісам.
Карыстальніцкія сцэнары работы з сэрвісам
Сцэнар 1. Распазнаванне мадэлі дыктара па прапанаваных прыкладах аўдыязапісаў
- Перайсці на ўкладку «Прыклад».
- Выбраць патрэбны раздзел базы дадзеных.
- Выбраць патрэбны прыклад з дадзенага раздзела. Пры неабходнасці можна праслухаць прыклад з дапамогай аўдыяплэера.
- Націснуць кнопку «Распазнаць».
- Атрымаць вынік работы сэрвіса (назва мадэлі дыктара) у полі «Распазнаны дыктар»
Сцэнар 2. Знаёмства з базай дыктараў сэрвіса
- Перайсці на ўкладку «Дыктары».
- Выбраць патрэбны раздзел базы дадзеных.
- Выбраць патрэбнага дыктара па яго назве.
- Прайграць аўдыязапіс голасу дыктара.
Сцэнар 3. Вызначэнне статыстычна і біяметрычна найбліжэйшай да карыстальніка мадэлі дыктара паводле аўдыязапіса, зробленага з дапамогай мікрафона.
- Перайсці на ўкладку «Запісаць».
- Выбраць патрэбны раздзел базы дадзеных.
- Націснуць кнопку «Запісаць», вымавіць у мікрафон прапанаваны тэкст, націснуць кнопку «Стоп». Пры неабходнасці можна праслухаць аўдыязапіс з дапамогай аўдыяплэера.
- Націснуць кнопку «Распазнаць».
- Атрымаць вынік работы сэрвіса (назву найбліжэйшай мадэлі дыктара) ў полі «Распазнаны дыктар».
Сцэнар 4. Вызначэнне статыстычна і біяметрычна найбліжэйшай мадэлі дыктара паводле аўдыязапісу, загружанага з цвёрдага дыска камп’ютара.
- Перайсці на ўкладку «Загрузіць файл».
- Выбраць патрэбны раздзел базы дадзеных.
- Націснуць кнопку «Агляд…» і выбраць аўдыяфайл для загрузкі з камп’ютара (падтрымліваюцца фарматы wav, mp3, flac, ogg, aiff). Пры неабходнасці можна паглядзець назву загружанага файла ў адведзеным для гэтага полі.
- Націснуць кнопку «Распазнаць».
- Атрымаць вынік работы сэрвіса (назву найбліжэйшай мадэлі дыктара) ў полі «Распазнаны дыктар».
Сцэнар 5. Дадаванне карыстальніка ў якасці новага дыктара.
- Перайсці на ўкладку «Дабавіць сябе».
- Выбраць патрэбны раздзел базы дадзеных.
- Азнаёміцца з тэкстамі, прапанаванымі для запісу. Пры неабходнасці можна праслухаць прыклады аўдыязапісаў.
- Запісаць уласнае прачытанне тэксту з дапамогай кнопак «Запісаць» і «Стоп». Пры неабходнасці можна праслухаць аўдыязапіс з дапамогай аўдыяплэера.
- Націснуць кнопку «Апрацаваць», каб запусціць апрацоўку аўдыязапісу.
- Паўтарыць крокі 4–5 для ўсіх тэкстаў.
- Націснуць кнопку «Дабавіць сябе» ўнізе акна ўкладкі.
- Атрымаць пацверджанне паспяховага дадавання новага дыктара ў полі «Статус». Калі пацверджанне не атрымана, пераканацца, што крокі 4–7 былі выкананы карэктна і ў выпадку неабходнасці запісаць і апрацаваць адсутныя тэксты.
Доступ да сэрвіса праз API
На дадзены момант доступ да сэрвіса праз API адсутнічае.
Спасылкі на крыніцы
Старонка сэрвіса – https://corpus.by/SpeakerRecognizer/?lang=be
Сайт праграмы Kaldi – http://kaldi-asr.org/