Сэрвіс «Падлік частотнасці сімвалаў» дае статыстычную і даведачную інфармацыю пра сімвалы ў тэксце, што дазваляе выявіць і выправіць іх памылковае выкарыстанне. На ўваход сэрвісу падаецца адвольны электронны тэкст ці паслядоўнасць сімвалаў. Сэрвіс падлічвае агульную колькасць сімвалаў уваходнага тэксту і колькасць унікальных сімвалаў у тэксце. На выхадзе для кожнага ўнікальнага сімвала адлюстроўваецца інфармацыя:
- код па стандарце Unicode;
- назва (для тых сімвалаў, якія ёсць у базе);
- частата ўжывання сімвала:
- абсалютная;
- адносная;
- кантэкст ужывання, сустрэты сэрвісам упершыню.
Выніковыя дадзеныя выводзяцца карыстальніку ў форме табліцы.
Асноўныя тэрміны і паняцці
Агульная колькасць сімвалаў – колькасць усіх сімвалаўжыванняў у тэксце.
Колькасць унікальных сімвалаў – колькасць усіх сімвалаў тэксту (ужытых 1 і болей разоў)
Абсалютная частата ўжывання сімвала (FreqAbs) – колькасць выпадкаў ужывання пэўнага сімвала ў тэксце.
Адносная частата ўжывання сімвала (FreqRel) – доля колькасці выпадкаў ужывання пэўнага сімвала адносна ўсіх сімвалаўжыванняў тэксту. Вылічваецца па формуле:
FreqRel = FreqAbs / ChUseAll * 100% ,
дзе ChUseAll – агульная колькасць сімвалаўжыванняў.
Unicode – стандарт кадзіравання сімвалаў, які ўключае ў сябе знакі амаль усіх пісьмовых моў свету. На сённяшні дзень дадзены стандарт з’яўляецца найбольш пашыраным у Інтэрнэце.
Практычная каштоўнасць
Сэрвіс прымяняецца пры вырашэнні шматлікіх задач.
Напрыклад, апрацоўка тэксту дадзеным сэрвісам – адзін з этапаў методыкі вычыткі тэксту вялікага памеру, дзе сэрвіс дапамагае выявіць няправільнае ўжыванне сімвалаў у тэксце. Так, карыстальнік мусіць прагледзець выніковы спіс сімвалаў і праверыць у ім наступныя моманты:
- ці аднолькавая колькасць дужак, напрыклад, /(/, /)/, /[/, /]/;
- ці аднолькавая колькасць падвоеных двукоссяў /“/, /”/, /«/, /»/, /„/, /“/;
- ці прысутнічае ў тэксце сімвал /”/, які насамрэч з’яўляецца сімвалам секунды, а не двукоссем, і пры няправільным ужыванні мусіць быць заменены на адно з двукоссяў;
- ці прысутнічае ў тэксце сімвал /’/, які па стандарце Unicode завецца апострафам, але ў беларускім друку ў ролі апострафа не ўжываецца і мусіць быць заменены сімвалам /’/ (Alt+0146);
- ці правільна выкарыстоўваецца злучок /-/, кароткі /–/, доўгі /—/ працяжнікі;
- ці прысутнічаюць лацінскія літары ў кірылічным тэксце.
Так, напрыклад, калі колькасць левых і правых дужак не супадае, то, хутчэй за ўсё, у тэксце ёсць пунктуацыйныя памылкі. Па знойдзеных памылковых ужываннях сімвалаў неабходна ўнесці праўкі ў тэкст, пажадана пераправерыць сэрвісам яшчэ раз скарэктаваны тэкст, і перайсці да наступнага этапу вычыткі (гл. методыку).
Асаблівасці сэрвіса
– На дадзены момант база назваў сімвалаў пакрывае ўсе сімвалы, якія сустракаюцца адначасова ў табліцы Unicode і ASCII, г. зн. аб’ём базы – 256 уваходжанняў (для сімвала назва не ўведзена). Калі назва сімвала не знойдзена сэрвісам у базе, карыстальніку ў якасці адказу будзе выведзены сімвал «–».
– Сэрвіс вызначае частотнасць толькі тых сімвалаў, якія сустракаюцца ў табліцы Unicode. Паводзіны сэрвіса пры спробе апрацоўкі іншых сімвалаў не даследаваліся.
– Кантэксты ўжывання сімвалаў фарміруюцца наступным чынам: зыходнае мноства сімвалаў паслядоўна дзеліцца на падмноствы, кожнае з якіх складаецца максімум з 28 сімвалаў. Гэта значыць, што даўжыня апошняга кантэксту будзе роўнай рэшце ад дзялення агульнай даўжыні карыстальніцкага ўводу на 28.
Алгарытм работы сэрвіса
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, UText;
- Карыстальніцкі ўвод у поле «Шукаць толькі наступныя сімвалы», SearchOnly;
- Мноства сімвалаў табліцы Юнікода, Unicode;
- Мноства сімвалаў табліцы ASCII, ASCII ⊂ Unicode;
- Мноства імёнаў сімвалаў ASCII, ASCIINames.
Пачатак алгарытму.
Крок 1.1. Фарміраванне падмностваў Line па наступных умовах: Lines ⊂ UText, мінімальны аб’ём Line = 1 сімвалаўжыванне (ChUse), стандартны (і максімальны) аб’ём Line = 28 ChUse. Падмноствы Line фарміруюцца паступовым аддзяленнем максімальнага аб’ёму Line ад UText: напрыклад, пры даўжыні UText = 116 ChUse будуць сфарміраваныя чатыры падмноствы даўжынёю 28 ChUse і адно падмноства даўжынёю 4 ChUse.
Крок 1.2. Фарміраванне мноства сімвалаўжыванняў CharsUse паводле карыстальніцкага тэксту UText. Запіс колькаснай велічыні аб’ёму мноства CharsUse у пераменную ChUseAll.
Крок 1.3. Фарміраванне мноства СhForSearch, якое складаецца з унікальных сімвалаў карыстальніцкага ўводу SearchOnly;
Крок 1.4. Фарміраванне CharsUniq – падмноства асацыяцый ўнікальных сімвалаў мноства CharsUse, у якіх ключом выступае кожны наступны ўнікальны сімвал <|CharUniq[X]|>, а значэннем – абсалютная частата яго ўжывання [ChFreqAbs[X]]. Абсалютная частата ўжывання ChFreqAbs[X] вылічваецца з дапамогай інкрэментавання пры кожнай новай сустрэчы CharUniq[X] у CharsUse.
Крок 1.5. Калі СhForSearch ≠ ∅, здзяйсняецца карэкцыя мноства CharUniq – выдаленне з яго ўсіх CharUniq[X] ∉ СhForSearch. Запіс колькаснай велічыні аб’ёму мноства CharUniq у пераменную UniqChars.
Крок 2.1. Фарміраванне троек <CharQniq[X], Line[X], ChFreqAbs[X]>, дзе Line[X] – першае па парадку падмноства Line, у якім ужыты CharUniq[X].
Крок 2.2. Вылічэнне адноснай частаты ўжыванняў FreqRel[X] для кожнага сімвала па формуле FreqRel[X] = ChFreqAbs[X] / ChUseAll * 100%.
Крок 2.3. Вызначэнне Code[X] – кодаў сімвалаў CharQniq[X], Code[X] ∈ Unicode.
Крок 2.4. Фарміраванне Name – мноства імёнаў сімвалаў CharQniq[X]. Калі Code[X] ∈ ASCII і Code[X] ≠ , у Name[X] запісваецца імя сімвала NamesASCII[X] на мове інтэрфейсу сэрвіса, калі Code [X] ∉ ASCII альбо Code [X] = , у Name[X] запісваецца сімвал «–».
Крок 3. Фарміраванне выніковай табліцы, кожны радок якой уяўляе сабой шасцёрку <CharUniq[X], Code[X], Name[X], ChFreqAbs[X], FreqRel[X], Line[X]>. Вывад значэнняў пераменных ChUseAll, UniqChars і выніковай табліцы карыстальніку.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Графічны інтэрфейс сэрвіса прадстаўлены на малюнку 1.
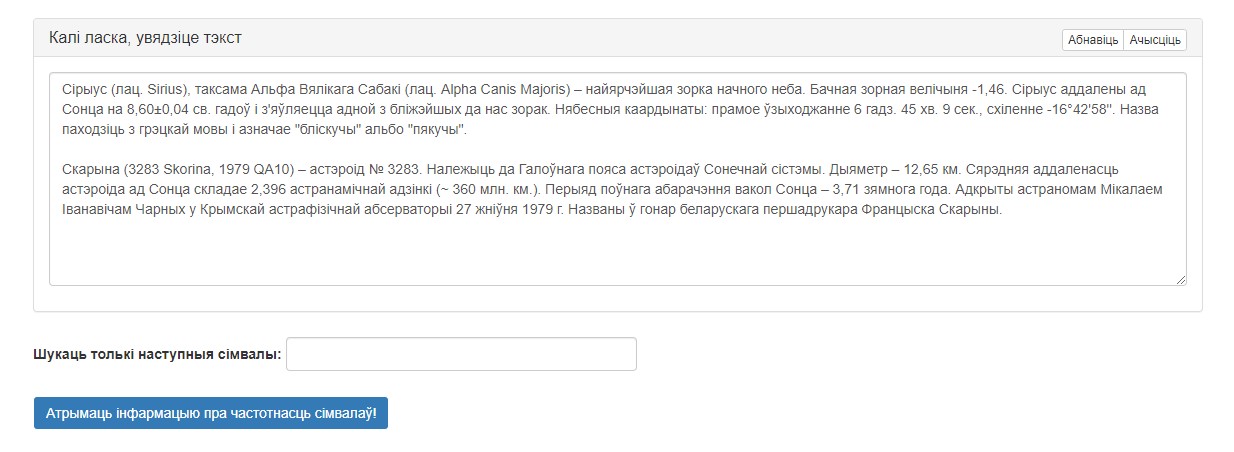
Малюнак 1. Інтэрфейс сэрвіса «Падлік частотнасці сімвалаў»
Інтэрфейс змяшчае наступныя вобласці:
- Поле ўводу электроннага тэксту, забяспечанае кнопкамі «Абнавіць» (вяртанне дадзеных па змаўчанні) і «Ачысціць» (выдаленне ўсіх дадзеных з поля);
- Поле ўводу «Шукаць толькі наступныя сімвалы»;
- Кнопка «Атрымаць інфармацыю пра частотнасць сімвалаў!», якая запускае апрацоўку тэксту і дае магчымасць атрымаць вынікі;
- Поле вываду выніковых дадзеных (з’яўляецца пасля першага націскання кнопкі «Атрымаць інфармацыю пра частотнасць сімвалаў!»).
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Атрыманне інфармацыі па ўсіх унікальных сімвалах тэксту (сцэнар апісаны ў рамках алгарытму вычыткі тэкстаў).
- Увесці ў поле ўводу электронны тэкст ці паслядоўнасць сімвалаў.
- Націснуць кнопку «Атрымаць інфармацыю пра частотнасць сімвалаў!».
- Пры неабходнасці адсартаваць дадзеныя: націснуць на загаловак слупка, па якім патрэбна адсартаваць спіс. Пры паўторным націску на адзін і той жа загаловак спіс адсартуецца ў адваротным парадку.
- Прагледзець спіс знойдзеных сімвалаў, шукаючы магчымыя выпадкі іх няправільнага ўжывання, няроўнай колькасці дужак і да т.п.
- Унесці праўкі ў зыходны тэкст.
- (Пажадана) пераправерыць сэрвісам тэкст з ужо ўнесенымі праўкамі і захаваць яго.
Сцэнар 2. Атрыманне інфармацыі пра пэўныя сімвалы тэксту.
- Увесці ў поле ўводу электронны тэкст ці паслядоўнасць сімвалаў.
- Увесці ў поле ўводу «Шукаць толькі наступныя сімвалы» сімвалы для пошуку. Сімвалы могуць паўтарацца, прабел таксама лічыцца сімвалам.
- Націснуць кнопку «Атрымаць інфармацыю пра частотнасць сімвалаў!».
- Пры неабходнасці адсартаваць дадзеныя: націснуць на загаловак слупка, па якім патрэбна адсартаваць спіс. Пры паўторным націску на адзін і той жа загаловак спіс адсартуецца ў адваротным парадку.
Прыклад выніковых дадзеных пры працы па сцэнары 1 прадстаўлены на малюнку 2.
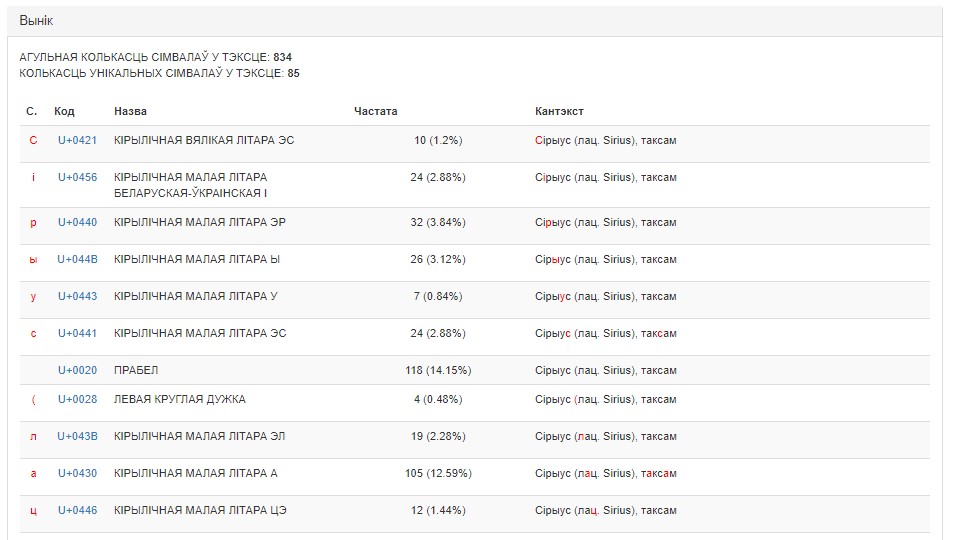
Малюнак 2. Вынікі апрацоўкі тэксту сэрвісам «Падлік частотнасці сімвалаў»
Прыклад выніковых дадзеных, адсартаваных па колькасці ўжыванняў сімвалаў, прадстаўлены на малюнку 3.
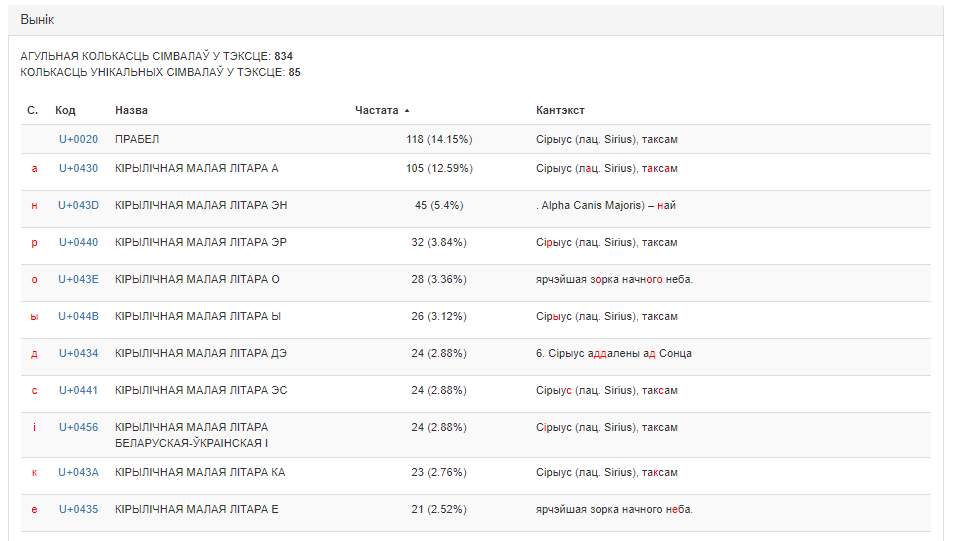
Малюнак 3. Вынікі апрацоўкі тэксту сэрвісам «Падлік частотнасці сімвалаў», адсартаваныя па колькасці ўжыванняў сімвалаў (ад большай да меншай)
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Падлік частотнасці сімвалаў» праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/CharacterFrequencyCounter/api.php. Праз масіў data перадаюцца наступныя параметры:
- text – адвольны ўваходны тэкст.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/CharacterFrequencyCounter/api.php”,
data:{
“text”: “Тэкст.”
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з уваходным тэкстам (параметр text) і выніковай табліцай частотнасці сімвалаў (параметр result). Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “Тэкст.”,
“result”: “THE TOTAL NUMBER OF CHARACTERS USED: <b>6</b><br>
THE TOTAL NUMBER OF UNIQUE CHARACTERS USED: <b>6</b><br>
<br>
<table class=”sort” align=”center” width=”100%”><thead><tr><td>C.</td><td>Code</td><td>Name</td><td colspan=”2″>Frequency</td><td>Context</td></tr></thead><tbody><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>Т</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/0422/”>U+0422</a></td>
<td width=”300″>CYRILLIC CAPITAL LETTER TE</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td><font color=”red”>Т</font>экст.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>э</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/044D/”>U+044D</a></td>
<td width=”300″>CYRILLIC SMALL LETTER E</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Т<font color=”red”>э</font>кст.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>к</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/043A/”>U+043A</a></td>
<td width=”300″>CYRILLIC SMALL LETTER KA</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Тэ<font color=”red”>к</font>ст.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>с</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/0441/”>U+0441</a></td>
<td width=”300″>CYRILLIC SMALL LETTER ES</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Тэк<font color=”red”>с</font>т.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>т</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/0442/”>U+0442</a></td>
<td width=”300″>CYRILLIC SMALL LETTER TE</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Тэкс<font color=”red”>т</font>.</td>
</tr><tr valign=”top”>
<td width=”36″ align=”center”><font color=”red”>.</font></td>
<td width=”76″ align=”center”><a href=”https://unicode-table.com/en/002E/”>U+002E</a></td>
<td width=”300″>FULL STOP</td>
<td align=”right”>1</td>
<td align=”center”>16.67%</td>
<td>Тэкст<font color=”red”>.</font></td>
</tr></tbody></table>”
}
]
Спасылкі на крыніцы
Старонка сэрвіса: https://corpus.by/CharacterFrequencyCounter/?lang=be
Методыка вычыткі электроннага тэксту вялікага памеру: https://ssrlab.by/5406
Табліца сімвалаў Unicode: https://unicode-table.com
Перакрыжаваныя спасылкі
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Drahun, A. Semi-Automatic Proofreading of Belarusian and English texts / A. Drahun, Yu. Hetsevich, A. Bakunovich, Dz. Dzenisiuk, J. Shynkevich // International Conference NooJ 2019: Book of Abstracts. – Hammamet, Tunisia, 2019.
- Марчык, М.У. Вычытка тэксту вялікага памеру на беларускай мове / М.У. Марчык, С.І. Лысы, Ю.С. Гецэвіч // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы II Междунар. науч.-практ. конф., Минск, 1–2 марта 2018 г. / редкол. : О. Г. Прохоренко (отв. ред.) [и др.]. — Минск : Издательский центр БГУ, 2018. — C. 58-63.