Сэрвіс «Фанетычны мінімізатар» дазваляе карыстальніку на аснове корпуса тэкстаў на беларускай мове сфарміраваць мінімізаванае мноства сказаў, якія пакрываюць усе фанетычныя адзінкі, наяўныя ў зыходным корпусе. На ўваход сэрвісу падаецца ўведзены карыстальнікам тэкст або абраная карыстальнікам база тэкстаў. Карыстальнік можа вызначыць два параметры мінімізацыі: базавую адзінку, паводле якой адбываецца мінімізацыя, і мяжу пошуку, да якой адбываецца пошук па кожнай унікальнай фанетычнай адзінцы. На выхадзе атрымліваюцца тры тэкставыя файлы: файл з мінімізаваным корпусам сказаў, файл са спісам унікальных фанетычных адзінак і файл са спісам рэдкіх фанетычных адзінак.
Асноўныя тэрміны і паняцці
Сінтэзатар маўлення па тэксце — гэта сістэма, здольная генераваць маўленне па тэксце. Змяшчае два блокі: блок лінгвістычнай апрацоўкі тэксту да фанемнага выгляду з пазнакамі націску, інтанацый (прасодыі) і рытму, а таксама блок апрацоўкі маўленчага сігналу, які пераўтварае раней атрыманы фанемны выгляд у гукавы сігнал маўлення.
Фанетычная мінімізацыя — адмысловы адбор тэкстаў, у выніку якога аб’ём тэкставага корпуса максімальна зменшыцца, але пры гэтым будзе захавана фанетычная паўната.
Практычная каштоўнасць
Сэрвіс «Фанетычны мінімізатар» можа паспрыяць у вырашэнні шэрагу задач. Перш за ўсё, сэрвіс можа быць прыменены пры распрацоўцы сістэмы сінтэзу беларускага маўлення, заснаванай на моўнай мадэлі. Значна зменшаны аб’ём корпуса робіць стварэнне такіх сістэм даступным шырокаму колу распрацоўшчыкаў і даследчыкаў. Апрача таго, аўтаматызацыя адбору мінімізаванага фанетычна поўнага мноства тэкстаў на беларускай мове можа быць выкарыстана ў шэрагу разнастайных навуковых сфер, напрыклад, у лінгвістычных даследаваннях ці пры стварэнні адмысловых дапаможнікаў па вывучэнні беларускай фанетыкі.
Апісанне інтэрфейсу карыстальніка
Графічны інтэрфейс сэрвіса прадстаўлены на малюнку 1.
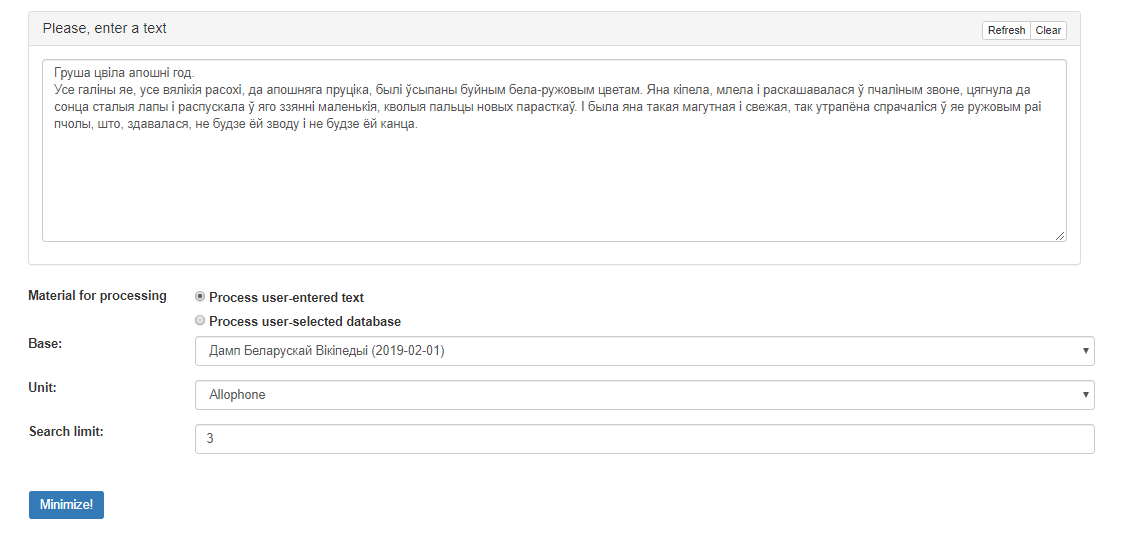
Малюнак 1 – Графічны інтэрфейс сэрвіса «Фанетычны мінімізатар»
Інтэрфейс змяшчае наступныя вобласці:
- тэкставае поле: поле для ўводу корпуса сказаў;
- радыё-кнопка: выбар спосабу падачы ўваходных дадзеных, якія будуць апрацоўвацца;
- селектар: выбар базы тэкстаў для апрацоўкі;
- селектар: выбар базавай адзінкі для апрацоўкі;
- тэкставы радок: радок для вызначэння колькаснай мяжы пошуку;
- кнопка «Мінімізаваць!», якая запускае апрацоўку і дае магчымасць атрымаць вынікі.
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Праца з карыстальніцкім тэкстам
1. Зайсці на старонку сэрвіса «Фанетычны мінімізатар».
2. Сярод групы опцый «Матэрыял для апрацоўкі» абраць опцыю «Апрацоўваць уведзены карыстальнікам тэкст».
3. Увесці ўваходны тэкст для апрацоўкі.
4. Абраць базавую адзінку для апрацоўкі.
5. Вызначыць мяжу пошуку.
6. Націснуць кнопку «Мінімізаваць!».
Сцэнар 2. Праца з базай, абранай карыстальнікам
1. Зайсці на старонку сэрвіса «Фанетычны мінімізатар».
2. Сярод групы опцый «Матэрыял для апрацоўкі» абраць опцыю «Апрацоўваць абраную карыстальнікам базу».
3. Абраць базу тэкстаў для апрацоўкі.
4. Абраць базавую адзінку для апрацоўкі.
5. Вызначыць мяжу пошуку.
6. Націснуць кнопку «Мінімізаваць!».
Вынікі працы сэрвіса прадстаўленыя на малюнках 2 і 3.


Малюнак 2, 3 – Вынікі працы сэрвіса «Фанетычны мінімізатар»
Алгарытм фанетычнай мінімізацыі
Алгарытм «Фанетычнага мінімізатара» дае магчымасць сфарміраваць мінімізаваны корпус тэкстаў, якія пакрываюць усе прысутныя ў зыходным корпусе гукавыя адзінкі.
У якасці фанетычнага прадстаўлення тэксту браўся алафонны тэкст у фармаце, які выкарыстоўвае сінтэзатар маўлення (https://corpus.by/TextToSpeechSynthesizer/?lang=be). Такі тэкст уяўляе сабой паслядоўнасць абазначэнняў алафонаў, паўз, словападзелаў і складападзелаў. Ніжэй прыведзены фрагмент арфаграфічнага тэксту і адпаведны яму алафонны тэкст.
Груша цвіла апошні год. Усе галіны яе, усе вялікія расохі, да апошняга пруціка, былі ўсыпаны бурным бела-ружовым цветам.
GH004,R022,U022,>,SH002,A323,/,>,C’002,V’002,I241,>,L002,A012,/,>,A221,>,P001,O012,>,SH002,N’004,I242,/,>,GH001,O032,T000,/,>,#P4,>,U203,>,S’001,E042,/,>,GH004,A233,>,L’002,I042,>,N004,Y323,/,>,J’012,A243,>,J’011,E040,/,>,#C3,>,U203,>,S’001,E043,/,>,V’012,A243,>,L’002,I043,>,K’002,I343,>,J’012,A342,/,>,R002,A222,>,S001,O023,>,H’002,I340,/,>,#C3,>,D004,A322,>,A221,>,P001,O012,>,SH002,N’004,A342,>,GH004,A231,/,>,P002,R012,U023,>,C’002,I342,>,K004,A330,/,>,#C3,>,B002,Y013,>,L’004,I241,/,>,W013,S001,Y021,>,P002,A312,>,N004,Y221,/,>,B002,U012,R001,>,N004,Y221,M001,/,>,B’002,E141,>,L004,A312,>,R002,U222,>,ZH002,O021,>,V012,Y211,M003,/,>,C’002,V’001,E042,>,T002,A321,M000,/,>,#P4
Коды алафонаў у гэтым запісе складаюцца з літарнай назвы фанемы (напрыклад, GH), знака мяккасці «’» (пры яе наяўнасці) і лічбавага кода, які ўказвае на тыя ці іншыя асаблівасці фанемы. У шэрагу эксперыментаў, апісаных ніжэй, будуць выкарыстоўвацца не толькі поўныя (напрыклад, ZH002), але і скарочаныя (напрыклад, ZH0) запісы алафонаў, у якіх адкідаюцца дзве апошнія лічбы, што ўказваюць на кантэкст алафона ў слове. Таксама ў дадзеным запісе можна назіраць знакі словападзелу «/» і складападзелу «>».
Уваходныя дадзеныя алгарытму:
- файл з корпусам сказаў у алафонным запісе, Fs;
- базавая фанетычная адзінка, unit;
- мяжа пошуку, lim (вызначае мінімальную неабходную колькасць кожнай унікальнай фанетычнай адзінкі).
Пачатак алгарытму.
Крок 1. Фарміраванне спісу сказаў. Выконваецца загрузка файла са спісам сказаў у алафонным запісе Fs. Фарміруецца спіс Ls = <s1, …, sN>, дзе sn – n‑ы сказ, n = 1, …, N.
Крок 2. Падбор сказаў з неабходнымі фанетычнымі адзінкамі. Ствараюцца пустое мноства Ls‘ для занясення ў яго абраных сказаў, а таксама лічыльнік фанетычных адзінак Cnt, дзе збіраюцца адпаведнасці фанетычных адзінак і іх колькасцяў у абраных сказах мноства Ls‘. Кожны сказ sn з мноства сказаў Ls праходзіць крокі 2.1–2.3.
Крок 2.1. Фарміраванне спісу фанетычных адзінак сказа. Вылучаюцца ўсе фанетычныя элементы сказа sn паводле абранай базавай фанетычнай адзінкі unit. Калі базавай фанетычнай адзінкай з’яўляецца алафон або склад, то падзел выконваецца па адпаведных раздзяляльных сімвалах, прысутных у алафонным запісе сказаў. У выпадку, калі базавай адзінкай з’яўляюцца камбінацыі вышэй названых адзінак, такія як дыфон, трыфон і інш., спярша адбываецца падзел на элементарныя адзінкі, з якіх потым паслядоўна складаюцца камбінацыі. Вынікам будзе мноства фанетычных адзінак Un = <u1, …, uM>, дзе um – m-я фанетычная адзінка сказа sn, m = 1, …, M.
Крок 2.2. Абранне сказа. Здзяйсняецца перабор фанетычных адзінак um з мноства Un. Калі чарговая фанетычная адзінка сустракаецца ў лічыльніку Cnt менш за lim разоў, то перабор прыпыняецца і адбываецца пераход да кроку 2.3. Іначай, калі перабраны ўсе фанетычныя адзінкі сказа, але ніводная не адпавядае вышэй указанай умове, пераходзім да наступнага сказа sn+1 і кроку 2.1. Калі ж апрацаваны сказ з’яўляецца апошнім сказам мноства (n = N), то пераходзім да кроку 3.
Крок 2.3. Занясенне сказа ў мноства абраных. Выконваецца перабор фанетычных адзінак um з мноства Un. Калі um адсутнічае ў лічыльніку Cnt, то ствараецца адпаведны запіс са значэннем адзінкі. Калі ж фанетычная адзінка ўжо ёсць у лічыльніку Cnt, то адпаведнае ёй значэнне павялічваецца на адзінку. Калі перабраны ўсе фанетычныя адзінкі сказа, адбываецца пераход да наступнага сказа sn+1 і кроку 2.1. Калі ж апрацаваны сказ з’яўляецца апошнім сказам спісу Ls (n = N), то здзяйсняецца пераход да кроку 3.
Крок 3. Мінімізацыя мноства абраных сказаў. Ствараецца пустое мноства Ls” для занясення ў яго толькі тых абраных сказаў з мноства Ls‘, якія ўтрымліваюць хаця б адзін фанетычны элемент, выдаленне якога зніжае агульную колькасць такіх элементаў ніжэй мяжы пошуку lim. Ствараецца копія лічыльніка фанетычных адзінак Cnt – Cnt‘, дзе збіраюцца адпаведнасці фанетычных адзінак і іх колькасцяў у мінімізаваным мностве Ls”. Кожны сказ s‘k з мноства сказаў Ls‘ праходзіць наступныя чатыры крокі.
Крок 3.1. Фарміраванне спісу фанетычных адзінак сказа. Вылучаюцца ўсе фанетычныя элементы сказа s‘k паводле абранай базавай фанетычнай адзінкі unit па аналогіі з крокам 2.1. Мноства фанетычных адзінак трансфармуецца ў мноства адпаведнасцяў фанетычных адзінак і іх колькасцяў у мностве. Такім чынам, вынікам кроку з’яўляецца мноства U‘k = <<u‘1, cnt1>, …, <u‘J, cntJ>>, дзе u‘j – j-я фанетычная адзінка, cntj – колькасць сустрэч фанетычнай адзінкі u‘j у сказе s‘k, j = 1, …, J.
Крок 3.2. Абранне сказа. Здзяйсняецца перабор фанетычных адзінак u‘j з мноства U‘k. Калі розніца колькасці сустрэч фанетычнай адзінкі u‘j у мностве абраных сказаў Ls‘ і мностве фанетычных адзінак бягучага сказа U‘k меншая за мяжу lim, то перабор прыпыняецца – адбываецца пераход да кроку 3.3. Іначай, калі перабраны ўсе фанетычныя адзінкі сказа, але ніводная не адпавядае вышэй указанай умове, – адбываецца пераход да кроку 3.4.
Крок 3.3. Занясенне сказа ў мінімізаванае мноства. Сказ s‘k заносіцца ў мінімізаванае мноства Ls‘‘. Адбываецца пераход да наступнага сказа s‘k+1 і кроку 3.1. Калі ж апрацаваны сказ з’яўляецца апошнім сказам мноства (k = K), то пераходзім да кроку 4.
Крок 3.4. Выдаленне сказа. Усе фанетычныя элементы сказа s‘k прадстаўлены ў астатніх сказах мноства Ls‘ у дастатковай колькасці, таму сказ не ўносіцца ў мінімізаваны спіс Ls”. Здзяйсняецца перабор фанетычных адзінак u‘j з мноства U‘k. Частоты кожнай фанетычнай адзінкі cntk адымаюцца ад частаты адпаведнай фанетычнай адзінкі ў лічыльніку Cnt‘. Калі перабраны ўсе фанетычныя адзінкі сказа, адбываецца пераход да наступнага сказа s‘k+1 і кроку 3.1. Калі ж апрацаваны сказ з’яўляецца апошнім сказам мноства (k = K), то пераходзім да кроку 4.
Крок 4. Фарміраванне выніку. Мноства сказаў Ls” сартыруецца паводле беларускага алфавіту, а лічыльнік Cnt‘ – паводле частаты. Вынік прыводзіцца ў наглядны тэкставы фармат, выводзіцца на экран і захоўваецца ў файле на серверы.
Канец алгарытму.
Доступ да сэрвіса праз API
Для доступу да сэрвіса “Фанетычны мінімізатар” праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/PhoneticMinimizer/api.php. Праз масіў data перадаюцца наступныя параметры:
- text — корпус тэкстаў на беларускай мове.
- unit — базавая фанетычная адзінка. Даступны наступныя базавыя адзінкі: allophone, dyphone, triphone, syllable, allophoneShort, dyphoneShort, triphoneShort, syllableShort.
- limit — мяжа пошуку, якая вызначае мінімальную неабходную колькасць кожнай унікальнай фанетычнай адзінкі.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/PhoneticMinimizer/api.php”,
data:{
“text“: “Усе галіны яе, усе вялікія расохі, да апошняга пруціка, былі ўсыпаны буйным бела-ружовым цветам. Яна кіпела, млела і раскашавалася ў пчаліным звоне, цягнула да сонца сталыя лапы і распускала ў яго ззянні маленькія, кволыя пальцы новых парасткаў. І была яна такая магутная і свежая, так утрапёна спрачаліся ў яе ружовым раі пчолы, што, здавалася, не будзе ёй зводу і не будзе ёй канца.”,
“unit”: “allophone”,
“limit”: “1“
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з наступнымі параметрамі:
- filename — назва файла на серверы, у якім захаваны атрыманы мінімізаваны корпус сказаў.
- MinimizedCorpusCnt — колькасць сказаў пасля мінімізацыі.
- UniqueUnitsCnt — колькасць унікальных фанетычных адзінак.
- RaritiesCnt — колькасць рэдкіх фанетычных адзінак (фанетычных адзінак, якіх было знойдзена менш за limit).
Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“filename”: “2020-01-17_17-28-54_80-94-171-2_288_minText.txt”,
“MinimizedCorpusCnt”: “1”,
“UniqueUnitsCnt”: “68”,
“RaritiesCnt”: “0”
}
]
Спасылкі на крыніцы
Старонка сэрвіса: https://corpus.by/PhoneticMinimizer/?lang=be
Перакрыжаваныя спасылкі