“Захаванне зместу інтэрнэт-старонкі” дазваляе карыстальніку без асаблівых складанасцяў захаваць HTML код любой інтэрнэт-старонкі. Дастаткова ў полі “Please input an URL” увесці спасылку і націснуць кнопку “Атрымать старонку”. Пасля апрацоўкі фарміруюцца два тэкставыя дакументы (*.txt): з тэгамі HTML (малюнак 2) і без іх (малюнак 3). Для таго, каб захаваць дакумент з HTML тэгамі, трэба націснуць на спасылку “Download full html page”, адпаведна, каб захаваць дакумент без тэгаў, трэба націснуць “Download html page without tags”.
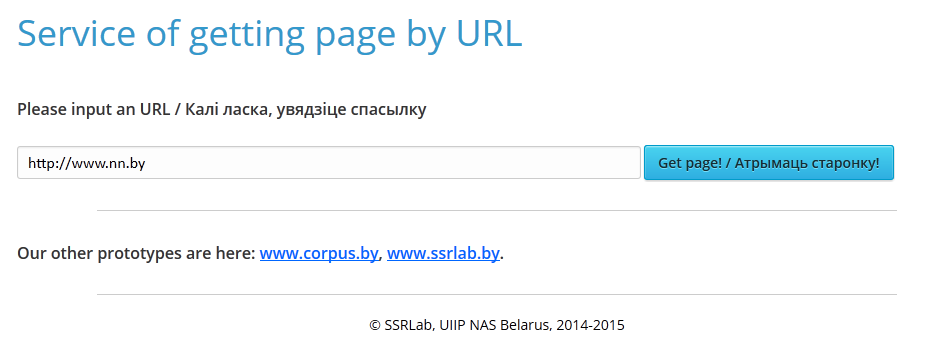 Малюнак 1 – Знешні інтэрфейс сэрвісу “Узяцця старонкі па спасылцы”
Малюнак 1 – Знешні інтэрфейс сэрвісу “Узяцця старонкі па спасылцы”
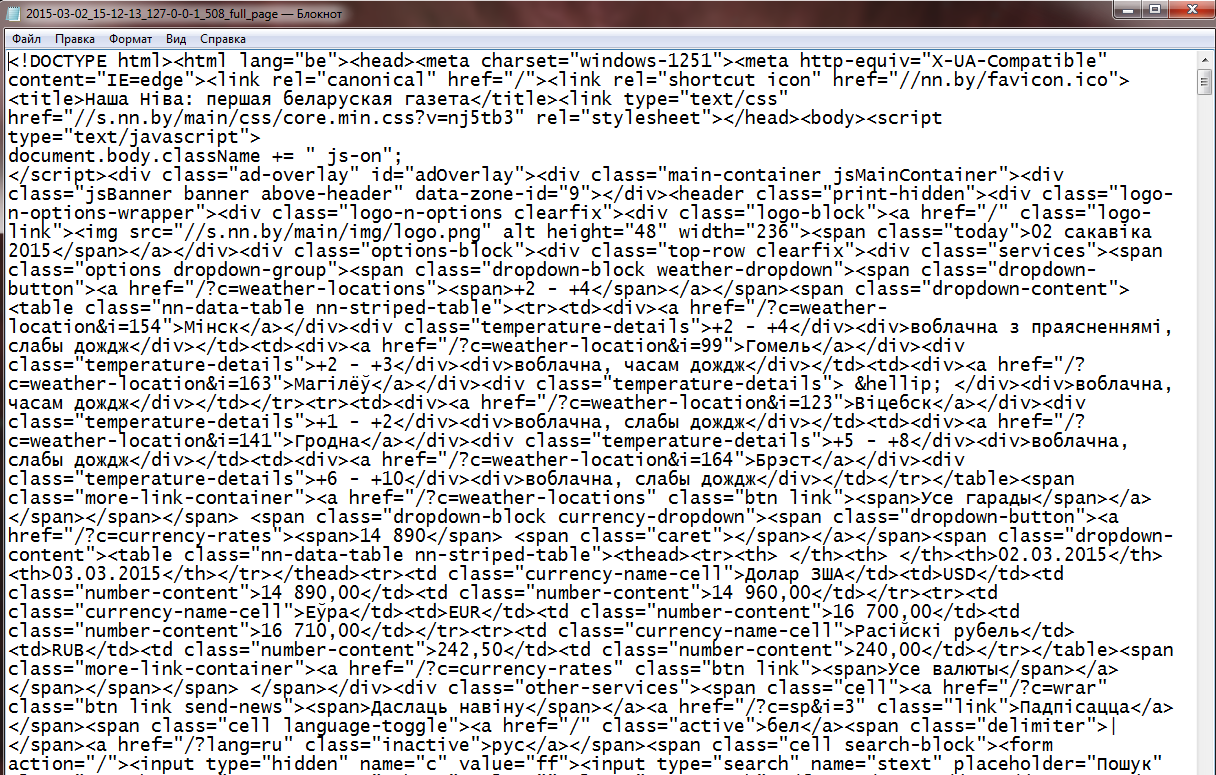 Малюнак 2 – Фрагмент дакумента з тэгамі
Малюнак 2 – Фрагмент дакумента з тэгамі
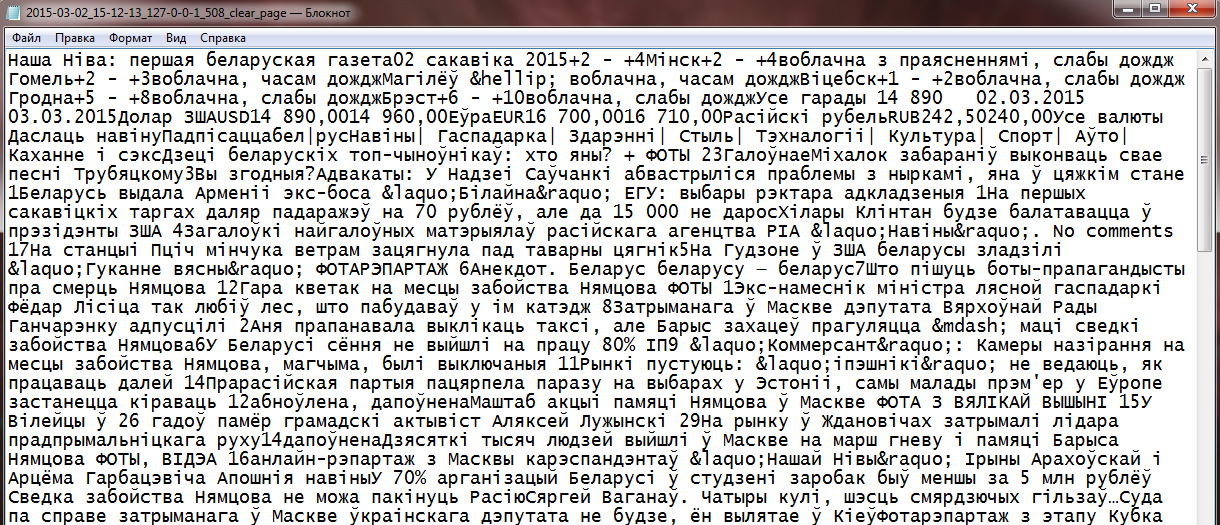 Малюнак 3 – Фрагмент дакумента без тэгаў
Малюнак 3 – Фрагмент дакумента без тэгаў
Доступ да сэрвіса праз API
Для доступу да сэрвіса “Захаванне зместу інтэрнэт-старонкі” праз API, неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/WebPageContentSaver/api.php. Праз масіў data перадаюцца наступныя параметры:
- url — URL мэтавай інтэрнэт-старонкі.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/WebPageContentSaver/api.php”,
data:{
“url”: “https://www.nn.by”
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з запрошаным URL (параметр url), URL выніковага файла з HTML-разметкай (параметр full) і URL выніковага файла, ачышчанага ад HTML-разметкі (параметр clear). Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“url”: “https://www.nn.by”,
“full”: “https://corpus.by/_cache/WebPageContentSaver/out/2018-05-17_13-56-14_80-94-162-88_939_full_page.txt”,“clear”: “https://corpus.by/_cache/WebPageContentSaver/out/2018-05-17_13-56-14_80-94-162-88_939_clear_page.txt”
}
]
Старонка сэрвісу: https://corpus.by/WebPageContentSaver/?lang=be