Сэрвіс «Генератар алфавітна-прадметнага паказальніка» дае магчымасць канвертаваць тэкст табліц універсальнай дзесятковай класіфікацыі (УДК) у алфавітна-прадметны паказальнік (АПП). На ўваход сэрвісу падаюцца табліцы УДК у фармаце «код класа — апісанне класа» праз табуляцыю, па адным класе на радок. Вынікам працы сэрвіса з’яўляецца фрагмент АПП.
Асноўныя тэрміны і паняцці
Алфавітна-прадметны паказальнік (АПП) — паказальнік, які складаецца з упарадкаванага па алфавіце мноства слоў, словазлучэнняў і фраз натуральнай мовы, якія абазначаюць прадметы якой-небудзь галіны навукі або практычнай дзейнасці [1].
АПП для УДК — масіў адпаведнасцяў «тэрміналагічная адзінка – каардынацыйны код/індэкс». Кожная адпаведнасць уяўляе сабой асобную прадметную рубрыку [2].
Універсальная дзесятковая класіфікацыя (УДК) — міжнародная класіфікацыйная сістэма, якая адпавядае найбольш істотным патрабаванням да класіфікацый: міжнароднасць, універсальнасць, пашыральнасць. Табліцы УДК былі перакладзены і апублікаваны цалкам ці часткова на больш чым 40 мовах, а выкарыстоўваецца УДК прыкладна ў 130 краінах свету. На тэрыторыі Беларусі УДК дзейнічае на працягу апошніх 50 год. Аднак толькі ў 2016 годзе з’явілася афіцыйнае выданне УДК на беларускай мове. Алфавітна-прадметны паказальнік (АПП), які складае больш за чвэрць выдання, быў падрыхтаваны пры дапамозе алгарытму, які аўтаматызаваў працэс яго стварэння [2].
Практычная каштоўнасць
З дапамогай дадзенага сэрвіса згенераваны АПП для выдання «Універсальная дзесятковая класіфікацыя» [3].
Алгарытм аўтаматызаванага стварэння алфавітна-прадметнага паказальніка УДК на беларускай мове
Алгарытм дае магчымасць сфарміраваць АПП УДК па тэкстах яе табліц і арыентаваны на працу з беларускім выданнем УДК, але аддзеленасць лінгвістычных і тэматычных рэсурсаў, якія выкарыстоўваюцца ў алгарытме, ад самога алгарытму дазваляе адаптаваць яго для працы з УДК на іншых мовах.
Уваходныя дадзеныя алгарытму: поўны тэкст асноўных табліц УДК TUDC.
Рэсурсы алгарытму:
- тэкставы файл Fsc, які змяшчае спіс стоп-класаў;
- тэкставы файл Fsw, які змяшчае спіс стоп-слоў;
- тэкставы файл Fdic, які змяшчае характэрную для УДК лексіку з указаннем пэўных граматычных характарыстык;
- тэкставы файл Fdom, які змяшчае спіс адпаведнасцяў «код класа – дамен».
Уваход:
Крок 1. Загрузка рэсурсаў. Адбываецца загрузка файлаў Fsc, Fsw, Fdic, Fdom з адмысловымі рэсурсамі ў памяць камп’ютара, фарміруюцца адпаведныя спісы.
Крок 1.1. Фарміраванне спісу стоп-класаў. Адбываецца загрузка файла са спісам стоп-класаў Fsc. Фарміруецца спіс Lsc = <sc1, …, scA>, дзе sca – a-ты стоп-клас, a = 1, …, A.
Крок 1.2. Фарміраванне спісу стоп-слоў. Адбываецца загрузка файла са спісам стоп-слоў Fsw. Фарміруецца спіс Lsw = <sw1, …, swB>, дзе swb – b-е стоп-слова, b = 1, …, B.
Крок 1.3. Фарміраванне спецыялізаванага слоўніка. Адбываецца загрузка файла-слоўніка Fdic. Фарміруецца спіс Ldic = <<w1,wa1,wc1,wi1>, …, <wC,waC,wcC,wiC>>, дзе wc – c-е слова слоўніка, wac – націск c-га слова слоўніка, wcc – катэгорыя c-га слова слоўніка, wic – пачатковая форма c-га слова слоўніка, c = 1, …, C.
Крок 1.4. Фарміраванне спісу прыналежнасці класаў даменам. Адбываецца загрузка файла Fdom. Фарміруецца спіс Ldom = <<cl1,dom1>, …, <clD,domD>>, дзе cld – d-ты клас спісу, domd – дамен, які адпавядае d-му класу спісу, d = 1, … , D.
Крок 2. Фарміраванне спісу класаў УДК. Уваходны тэкст TUDC разбіваецца на асобныя запісы – класы УДК; у кожным запісе вылучаецца код класа і апісанне класа. Такім чынам на аснове ўваходнага тэксту TUDC фарміруецца спіс LUDC = <Cl1, … , ClN>, дзе Cln = <Notn, Capn>, Notn – n-ты код класа, Capn – n-е апісанне класа, n = 1, …, N.
Крок 3. Апрацоўка спісу класаў УДК. Ствараецца спіс адпаведнасцяў «слова – мноства кодаў класаў» Lres, у які будуць заносіцца вынікі апрацоўкі. Кожны элемент Cln спісу LUDC праходзіць крокі 3.1–3.6.
Крок 3.1. Фільтрацыя паводле спісу стоп-класаў. Адбываецца вызначэнне, ці прыналежыць код класа Notn спісу стоп-класаў Lsc. Калі прыналежнасць выяўлена, то адбываецца пераход да наступнага элементу Cln+1 і кроку 3.1 (пры n = N – да кроку 4). Іначай – да кроку 3.2.
Крок 3.2. Вылучэнне слоў. У апісанні класа Capn вылучаюцца ўсе сімвальныя паслядоўнасці, якія адпавядаюць шаблону будовы слова Ptw. Выкарыстоўваючы сінтаксіс рэгулярных выразаў PCRE (https://www.pcre.org/original/doc/html/pcrepattern.html), дадзены шаблон можна прадставіць наступным чынам:
Ptw = [set1][set1set2]* ,
дзе set1 – мноства сімвалаў, з якіх можа пачынацца слова, set2 – мноства сімвалаў, з якіх можа складацца, але не можа пачынацца слова, set1set2 = set1 ∪ set2. У склад мноства set1 уваходзяць літары беларускага алфавіту; у склад мноства set2 – злучок, апостраф, сімвалы націскаў і інш.
Вылучаныя ў апісанні класа Capn словы заносяцца ў спіс Wcap = <wrd1, … , wrdM>, дзе wrdm – m-е вылучанае слова, m = 1, …, M.
Крок 3.3. Нармалізацыя слоў. Кожнае слова wrdm са спісу Wcap прыводзіцца да нармалізаванай электроннай формы (словы прыводзяцца да ніжняга рэгістра; адбываецца ўніфікацыя апострафаў, замена літары «ў» на «у» ў пачатку слова і інш.). Вынікам дадзенай апрацоўкі з’яўляецца спіс нармалізаваных слоў W’cap = <wrd’1, … , wrd’M>, дзе wrd’m – m-е нармалізаванае слова, m = 1, …, M.
Крок 3.4. Фільтрацыя паводле спісу стоп-слоў. Для кожнага слова са спісу W’cap адбываецца вызначэнне, ці прыналежыць яно спісу стоп-слоў Lsw. Калі прыналежнасць не выяўлена, то слова заносіцца ў спіс W”cap = <wrd”1, … , wrd”K>, дзе wrd’k – k-е дапушчальнае слова, k = 1, …, K.
Крок 3.5. Фільтрацыя паводле часціны мовы і прывядзенне да пачатковай формы. Для кожнага слова са спісу W”cap адбываецца вызначэнне часціны мовы wc і пачатковай формы wi паводле спісу характэрнай для УДК лексікі Ldic. Калі бягучае слова з’яўляецца назоўнікам, прыметнікам або дзеепрыметнікам, то яго пачатковая форма wi заносіцца ў спіс W”’cap = <wrd”’1, … , wrd”’J>, дзе wrd’j – j-е дапушчальнае слова ў пачатковай форме, j = 1, …, J.
Крок 3.6. Занясенне ў выніковы спіс. Кожнае слова са спісу W”’cap заносіцца ў выніковы спіс Lres. Калі ў выніковым спісе Lres бягучае слова яшчэ не сустракаецца, то слова дадаецца ў выглядзе новага элемента, у адпаведнасць якому ставіцца масіў з адным элементам – кодам апрацоўваемага класа Notn. Калі ж слова ўжо занесена ў выніковы спіс Lres, то код апрацоўваемага класа Notn заносіцца ў масіў кодаў класаў, адпаведных апрацоўваемаму слову.
Крок 4. Прысвойванне даменаў. Адбываецца перабор элементаў спісу Lres. У кожным элеменце Lres да кожнага кода класа вызначаецца тэматычны дамен dom паводле спісу Ldom. Коды класаў, дамены якіх супадаюць, групуюцца ў адзін масіў.
Такім чынам, вынікам з’яўляецца спіс Lres = <<wrd1, ent1>, …, <wrdR, entR>, дзе wrdr – r-е слова выніковага спісу, r = 1, …, R; у сваю чаргу entr = <<dom1, Lnot1>, …, <domS, LnotS>>, дзе doms – s-ты дамен, да якога адносіцца слова wrdr, s = 1, …, S; і ўрэшце Lnots = <not1, …, notT>, дзе nott – t-ты код класа, адпаведнага дамену doms, да якога адносіцца слова wrdr, t = 1, …, T.
Крок 5. Фарміраванне выніку. Адбываецца сартыроўка выніковага спісу Lres паводле беларускага алфавіту і прывядзенне да тэкставага фармату з неабходным фарматаваннем. Вынік TASI выводзіцца на экран і захоўваецца ў адпаведным файле на серверы.
Канец алгарытму [2].
У выніку выканання апісанага алгарытму на аснове табліц УДК на беларускай мове фарміруецца АПП. Варта адзначыць, што прапанаваны алгарытм з’яўляецца прыдатным для пашырэння на іншыя мовы, бо лінгвістычныя і тэматычныя рэсурсы, выкарыстаныя ў ім, аддзелены ад алгарытму і могуць быць распрацаваны для іншай мовы.
Апісанне інтэрфейсу карыстальніка
Інтэрфейс сэрвіса прадстаўлены на малюнку 1.

Малюнак 1. Інтэрфейс сэрвіса «Генератар алфавітна-прадметнага паказальніка»
Інтэрфейс змяшчае наступныя вобласці:
- поле ўводу ўваходных дадзеных;
- опцыя «Атрымаць дадатковую інфармацыю» — сэрвіс прадставіць інфармацыю пра словы, якія не атрымалася апрацаваць з-за адсутнасці той ці іншай неабходнай інфармацыі ў базе, а таксама падасць спіс знойдзеных ва ўваходным тэксце амографаў;
- кнопка «Згенераваць алфавітна-прадметны паказальнік», дзякуючы якой можна атрымаць вынік.
Карыстальніцкі сцэнар працы з сэрвісам
Для карэктнай працы вэб-сэрвіса табліцы УДК павінны быць пададзены ў наступным фармаце: класы УДК аддзелены адзін ад аднаго пераводам радка, у межах аднаго запісу код класа аддзелены ад апісання класа табуляцыяй (малюнак 1).
Сцэнар 1. Генерацыя АПП
- Увесці ў поле ўводу карэктныя ўваходныя дадзеныя.
- Націснуць кнопку «Згенераваць алфавітна-прадметны паказальнік». Вынікі будуць мець выгляд, прадстаўлены на малюнку 2.
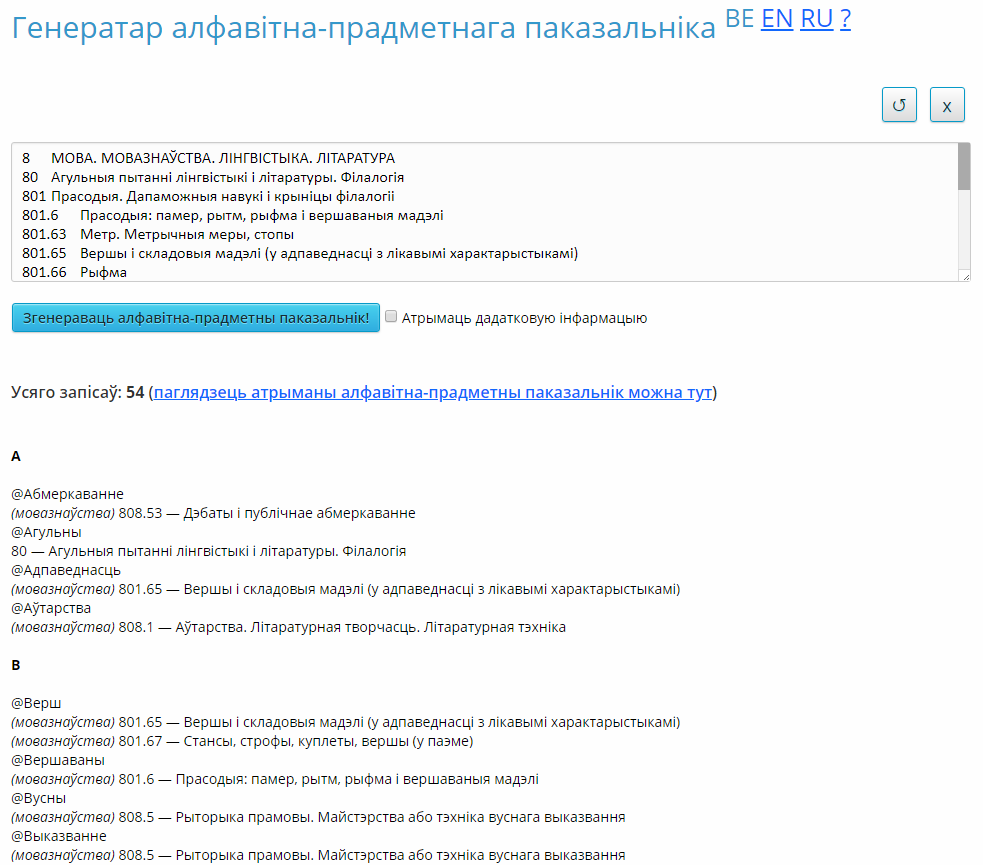
Малюнак 2. Вынікі генерацыі АПП
Сцэнар 2. Генерацыя АПП з дадатковай інфармацыяй
Сэрвіс дае магчымасць карыстальніку не толькі генераваць АПП на падставе ўведзенага тэксту, але і адсочваць пэўную дадатковую інфармацыю датычна працэсу апрацоўкі (для гэтага патрэбна адзначыць пункт «Атрымаць дадатковую інфармацыю»). Сэрвіс прадставіць інфармацыю пра словы, якія не атрымалася апрацаваць з-за адсутнасці той ці іншай неабходнай інфармацыі ў базе, а таксама падасць спіс знойдзеных ва ўваходным тэксце амографаў. У табліцы прадстаўлены прыклад выніковага АПП, згенераванага на падставе фрагменту табліц УДК пры дапамозе вэб-сэрвіса «Генератар алфавітна-прадметнага паказальніка».
- Увесці ў поле ўводу карэктныя ўваходныя дадзеныя.
- Паставіць птушку на опцыі «Атрымаць дадатковую інфармацыю».
- Націснуць кнопку «Згенераваць алфавітна-прадметны паказальнік». Вынікі будуць мець выгляд, прадстаўлены на малюнку 3.

Малюнак 3. Вынікі генерацыі АПП з дадатковай інфармацыяй. Пры апрацоўцы дадзенага ўваходнага тэксту дадатковай інфармацыі не выяўлена.
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Генератар алфавітна-прадметнага паказальніка» праз API, неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/AlphabeticalSubjectIndexGenerator/api.php. Праз масіў data перадаюцца наступныя параметры:
- text — фрагмент табліц УДК у фармаце «код класа — апісанне класа» праз табуляцыю, па адным класе на радок.
- additionalInfo — маркер неабходнасці дадатковай інфармацыі.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/AlphabeticalSubjectIndexGenerator/api.php”,
data:{
“text”: “8 МОВА. МОВАЗНАЎСТВА. ЛІНГВІСТЫКА. ЛІТАРАТУРА
80 Агульныя пытанні лінгвістыкі і літаратуры. Філалогія
801 Прасодыя. Дапаможныя навукі і крыніцы філалогіі
801.6 Прасодыя: памер, рытм, рыфма і вершаваныя мадэлі
801.63 Метр. Метрычныя меры, стопы
801.65 Вершы і складовыя мадэлі (у адпаведнасці з лікавымі характарыстыкамі)
801.66 Рыфма
801.67 Стансы, строфы, куплеты, вершы (у паэме)
801.7 Дапаможныя філалагічныя дысцыпліны
801.8 Філалагічныя і лінгвістычныя крыніцы. Зборнікі тэкстаў”,
“additionalInfo”: 1
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з уваходным фрагментам табліц УДК (параметр text), выніковым фрагментам алфавітна-прадметнага паказальніка і адрасам, дзе вынік захаваны, (параметр result і ResultUrl адпаведна), колькасцю сэнсавых адзінак у выніку (параметр ResultCnt), спісам невядомых сэрвісу слоў і адрасам, дзе гэты спіс захаваны, (параметры UnknownWordsList і UnknownWordsListUrl адпаведна), спісам амографаў і адрасам, дзе гэты спіс захаваны, (параметры HomographList і HomographListUrl адпаведна), спісам слоў, для якіх не ўдалося вызначыць націск, і адрасам, дзе гэты спіс захаваны, (параметры UnaccentedWordsList і UnaccentedWordsListUrl адпаведна). Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “8 МОВА. МОВАЗНАЎСТВА. ЛІНГВІСТЫКА. ЛІТАРАТУРА <…>“,
“result”: “<b>А</b><br><br>@Агульны<br>80 — Агульныя пытанні лінгвістыкі і літаратуры. Філалогія<br> <…>“,
“UnknownWordsList”: “”,
“UnknownWordsListUrl”: “”,
“HomographList”: “”,
“HomographListUrl”: “”,
“UnaccentedWordsList”: “”,
“UnaccentedWordsListUrl”: “”,
“ResultCnt”: 31,
“ResultUrl”: “https://corpus.by/showCache.php?s=AlphabeticalSubjectIndexGenerator&t=out&f=2018-06-25_17-17-47_80-94-162-88_326_out.txt”
}
]
Спасылкі на крыніцы
Старонка сэрвіса: https://corpus.by/AlphabeticalSubjectIndexGenerator/?lang=be
Артыкулы па тэме: https://ssrlab.by/tag/udc
Перакрыжаваныя спасылкі
- Профессиональное образование. Словарь. Ключевые понятия, термины, актуальная лексика. — М.: НМЦ СПО. С.М. Вишнякова. 1999.
- Лысы, С. І. Аўтаматызаваная генерацыя алфавітна-прадметнага паказальніка Універсальнай дзесятковай класіфікацыі на беларускай мове / С. І. Лысы, Г. Р. Станіславенка, Ю. С. Гецэвіч // Информатика. – 2018. − Т. 15, № 2. – С. 7–16.
- Універсальная дзесятковая класіфікацыя : звыш 10 000 асноўных і дапаможных класаў / Аб’яднаны інстытут праблем інфарматыкі Нацыянальнай акадэміі навук Беларусі, Нацыянальная бібліятэка Беларусі; [рэдакцыйная калегія: Ю. С. Гецэвіч, С. А. Пугачова, Г. Р. Станіславенка і інш. ; укладальнікі алфавітна‑прадметнага паказальніка: С. І. Лысы, Г. Р. Станіславенка, Ю. С. Гецэвіч]. – Мінск, 2016. – 370 с.
- Драгун, А. Я. Аўтаматызаваныя сродкі атрымання расшыфроўкі і спісаў кодаў беларускамоўнай Універсальнай дзесятковай класіфікацыі / А. Я. Драгун, Я. С. Зяноўка, М. С. Галаўчак, С. С. Маеўскі, Ю. С. Гецэвіч // Материалы VII Международного конгресса «Библиотека как феномен культуры» : Краеведение и страноведение в сохранении культурного разнообразия, Минск, 21–22 октября 2020 г. / Национальная библиотека Беларуси ; [сост.: Т. В. Кузьминич, А. А. Суша]. – Минск, 2020. – С. 300-306.
- Універсальная дзесятковая класіфікацыя : Асноўная табліца. Класы 0-9. Дапаможныя табліцы. Алфавітна-прадметны паказальнік : першае скарочанае выданне на беларускай мове.
- Hetsevich, Yu.S. Preparation of the First UDC Abridged Edition in Belarusian / Yu.S. Hetsevich, A.M. Skopinava, T.I. Okrut, S.A. Hetsevich, S.A. Pugachova // Extensions and Corrections to the UDC. – 2014-2015. – №36-37. – P. 23-30.
- Станіславенка, Г.Р. Выкарыстанне камп’ютарна-лінгвістычных сродкаў для перакладу ўніверсальнай дзесятковай класіфікацыі дамена “тэатр” з англійскай на беларускую мову і генерацыя алфавітна-прадметнага паказальніка / Г.Р. Станіславенка, Ю.С. Гецэвіч, С.І. Лысы // Актуальные вопросы германской филологии и лингводидактики: материалы XX Междунар. науч.-практ. конф. / Брест. гос. ун-т имени А.С. Пушкина; редкол.: Е. Г. Сальникова [и др.]. — Брест : Альтернатива, 2016. — C. 264-266.
- Станиславенко, А.Г. Этапы подготовки первого издания УДК на беларусском языке / А.Г. Станиславенко, С.И. Лысы, Ю.С. Гецевич // Информация в современном мире : доклады Международной конференции, Москва, 25-26 октября 2017 г. / ВИНИТИ РАН. — Москва : ВИНИТИ РАН, 2017. — C. 297-303.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.