Сэрвіс «Праверка правапісу «ў» распрацаваны для хуткай праверкі вялікіх электронных тэкстаў на беларускай мове з мэтай пошуку і выпраўлення адной з найбольш распаўсюджаных памылак – памылкі ў напісанні літар «у» і «ў».
На ўваход сэрвісу падаецца тэкст на беларускай мове ў звычайным выглядзе. Калі карыстальнік націсне кнопку «Праверыць!», сэрвіс абазначыць магчымыя памылкі двух тыпаў: па-першае, калі літара «у» напісана ў пазіцыі, дзе, верагодна, павінна быць літара «ў»; па-другое, калі напісана літара «ў», дзе, верагодна, павінна быць літара «у».
Асноўныя тэрміны і паняцці
Ў – у нескладовае (кароткае) – 22-я літара беларускага алфавіта. Беларуская кірыліца – адзіная славянская моўная знакавая сістэма, у якой ужываецца дадзеная літара (за выключэннем выпадкаў ужывання літары ва ўкраінскай мовазнаўчай літаратуры). Гук [ў], які абазначаецца літарай «ў», у залежнасці ад месца ў слове і паходжання слова чаргуецца з гукамі [у] [в] і [л]. Больш падрабязна – https://be.wikipedia.org/wiki/%D0%8E.
Практычная каштоўнасць
– Сэрвіс будзе карысны для вырашэння пытанняў аўтаматызацыі вычыткі і рэдагавання тэкстаў на беларускай мове. З гэтай прычыны сэрвіс уключаны ў «Методыку вычыткі электронных тэкстаў вялікага памеру пры дапамозе сэрвісаў Corpus.by» (https://ssrlab.by/5406).
– Таксама сэрвіс будзе карысны для паляпшэння якасці сінтэзу маўлення з дапамогай аўтаматызаваных сістэм. Адным з важных момантаў у сінтэзаванні маўлення з’яўляецца тое, што ўваходны тэкст мусіць не мець арфаграфічных памылак. Іначай, відавочна, вынікам працы сінтэзатара маўлення па тэксце будзе некарэктны гукавы тэкст, які рэжа слых.
Асаблівасці сэрвіса
– У працэсе пошуку магчымых памылак сэрвіс не толькі вызначае, галосны ці зычны знаходзіцца перад «у», але таксама аналізуе сімвалы, якія не з’яўляюцца літарамі, у выпадку, калі літара «у» знаходзіцца ў пачатку слова. Гэтыя сімвалы могуць мець непасрэдны ўплыў на напісанне слова.
– Не ўсе словы беларускай мовы падпарадкоўваюцца агульным правілам напісання літары «ў». З гэтай прычыны ў сэрвісе прадстаўлена магчымасць выкарыстоўваць слоўнік выключэнняў (далучаецца спецыяльнай опцыяй) альбо карыстальніцкі спіс выключэнняў. Сэрвіс апрацоўвае тэкст з аглядкай на дадзеныя мноствы слоў.
– Для напісання абрэвіятур з літарай «у» беларуская мова мае адмысловыя правілы. Але, паколькі сэрвіс не адрознівае абрэвіятуры ад іншых слоў аўтаматычна, для атрымання дакладных вынікаў карыстальніку прапануецца ўвесці абрэвіятуры, якія сустракаюцца ў тэксце, у адпаведнае поле.
– Знакамі прыпынку сэрвіс лічыць наступныя сімвалы: «,», «.», «:», «;», «!», «?», «–», «—», «(», «)». Сімвалы «[», «]», «{», «}», «_», «%», «№», «#», «^», «$», «@» і іншыя для алгарытму працы сэрвіса знакамі прыпынку не з’яўляюцца. Злучок («-») з’яўляецца знакам прыпынку (атаясамліваецца з працяжнікам) толькі ў тым выпадку, калі ён аточаны абапал прабеламі.
Алгарытм працы сэрвіса
Уваходныя дадзеныя алгарытму:
-
Карыстальніцкі тэкставы ўвод, UText;
-
Мноства ўсіх сімвалаў арабскіх лічбаў, асноўных кірылічных і лацінскіх сімвалаў у верхнім і ніжнім рэгістры, LettersAndNumbers;
-
Мноства ўсіх сімвалаў беларускага алфавіта ў верхнім і ніжнім рэгістры, LettersBel, LettersBel ⊂ LettersAndNumbers;
-
Мноства ўсіх кірылічных і лацінскіх сімвалаў у верхнім рэгістры, Uppercase, Uppercase ⊂ LettersAndNumbers;
-
Мноства ўсіх кірылічных і лацінскіх сімвалаў у ніжнім рэгістры, Lowercase, Lowercase ⊂ LettersAndNumbers;
-
Мноства ўсіх літар беларускай мовы, якія абазначаюць галосныя гукі, у верхнім і ніжнім рэгістры, Vovels, Vovels ⊂ LettersBel;
-
Мноства ўсіх літар беларускай мовы, якія абазначаюць зычныя гукі, у верхнім і ніжнім рэгістры, Consonants, Consonants ⊂ LettersBel;
-
Мноства знакаў прыпынку, PunctuationMarks;
-
Слоўнік выключэнняў, DicExceptions;
-
Карыстальніцкі спіс слоў-выключэнняў, UserExceptions;
-
Булевая пераменная, якая адказвае за прымяненне слоўніка выключэнняў, BoolDic;
-
Карыстальніцкі спіс абрэвіятур, UserAbbreviations.
Пачатак алгарытму.
Крок 1.1. Разбіўка UText на мноства Lines паводле сімвалаў пераводу радка.
Крок 1.2. Фарміраванне мноства выключэнняў Exceptions. Калі BoolDic = true, Exceptions фарміруецца з дадзеных DicExceptions, калі BoolDic = false – з дадзеных UserExceptions.
Крок 1.3. Фарміраванне мноства абрэвіятур Abbreviations з карыстальніцкага спіса абрэвіятур UserAbbreviations. У дадзенае мноства ўваходзяць усе абрэвіятуры UserAbbreviations, у якіх кожны сімвал Char ∈ LettersBel.
Крок 1.4. Стварэнне мностваў ErrU і ErrUn для захавання інфармацыі аб памылковым ужыванні адпаведна літар «у» («У») і «ў» («Ў»), ErrU = ∅, ErrUn = ∅.
Крок 2.1. Разбіўка наступнага па парадку элемента мноства Lines[Z] на двухмерны масіў слоў з раздзяляльнікамі WordsAndSeparators з дапамогай рэгулярнага выразу. «Словам з раздзяляльнікам» лічыцца кожная новая частка Lines[Z], якая складаецца з мноства сімвалаў Char і адпавядае наступнаму правілу: першы Char ∈ LettersAndNumbers, наступныя Char ∈ LettersAndNumbers (іх можа быць 0 або больш), заключны Char ∉ LettersAndNumbers (сустракаецца 0 або больш разоў). Слова Word і раздзяляльнік Separator – гэта асобныя элементы масіву.
Крок 2.2. Калі Lines[Z] = ∅, здзейсніць інкрэментацыю Z і перайсці да кроку 2.1.
Крок 2.3. Калі Word[X] ∈ Exceptions, адбываецца інкрэментаванне X і пераход да новага Word[X]. Інакш ажыццяўляецца фарміраванне мноства кантэкстаў Contexts. Кожны элемент мноства Contexts прывязаны да адпаведнага элемента мноства Chars (гл. Крок 2.4.) і складаецца з Y пар «Word – Separator», якія папярэднічаюць дадзенаму элементу, і Y такіх жа пар, якія ідуць пасля дадзенага элемента (0 ⩽ Y ⩽ 3, Y ∈ N).
Крок 2.4. Разбіўка элементаў WordsAndSeparators на мноства сімвалаў Chars, стварэнне пераменных LastLetter – для захавання Char, які папярэднічае бягучаму Char, і LastSeparator – для захавання сімвала, які раздзяляе бягучае праверанае мноства з папярэднім. LastSeparator можа быць знакам прыпынку, прабелам, а таксама далучаць да сябе адзін ці больш Char ∉ LettersAndNumbers & PunctuationMarks.
Крок 2.5. Калі Chars[A] = «у» або «У», прычым Word[X] ∉ Abbreviations і Word[X] ≠ «У», здзейсніць крокі 2.5.1 – 2.5.3, інакш перайсці да кроку 2.6.
Крок 2.5.1. Калі A = 0, праверыць, ці LastSeparator ∈ PunctuationMarks. Калі так, інкрэментаваць A і перайсці да кроку 2.5. Калі не, праверыць, ці LastLetter ∈ Vovels. Калі так, то дадаць да мноства ErrUn пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘«у» пасля галоснай «{LastLetter}» без знакаў прыпынку’ (тут і далей змест Comment можа змяняцца ў залежнасці ад мовы карыстальніцкага інтэрфейсу).
Крок 2.5.2. Калі элемент Chars[A-1] зададзены і Chars[A-1] ∈ Vovels, праверыць, ці правільна, што элемент Chars[A+1] роўны сімвалам «м», «М», «с» ці «С», а таксама ці правільна, што A+2 складае велічыню мноства Chars. Калі хаця б адна з пералічаных умоў не выканана, то дадаць да мноства ErrUn пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘«у» пасля галоснай {LastLetter}’.
Крок 2.5.3. Калі элемент Chars[A-1] зададзены і роўны сімвалу «-» (злучок), то праверыць, ці зададзены элемент Chars[A-2] і ці Chars[A-2] ∈ Vovels. Калі абедзве ўмовы выкананыя, то дадаць да мноства ErrUn пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘«у» пасля галоснай {LastLetter} і злучка’.
Крок 2.6. Калі Chars[A] = «ў», здзейсніць крокі 2.6.1. – 2.6.5. Інакш перайсці да кроку 2.7.
Крок 2.6.1. Калі A = 0, праверыць, ці LastSeparator ∈ PunctuationMarks. Калі так, то дадаць да мноства ErrU пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘«ў» не выкарыстоўваецца пасля знака прыпынку’. Калі не, то праверыць, ці LastLetter ∈ Consonants. Калі так, то дадаць да мноства ErrU пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘«ў» пасля зычнай «{LastLetter}» без знакаў прыпынку’.
Крок 2.6.2. Калі элемент Chars[A-1] зададзены і Chars[A-1] ∈ Consonants, то дадаць да мноства ErrU пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘«ў» пасля зычнай «{LastLetter}»’.
Крок 2.6.3. Калі элемент Chars[A-1] зададзены і Chars[A-1] = «-» (злучок), то праверыць, ці зададзены элемент Chars[A-2] і ці Chars[A-2] ∈ Consonants. Калі так, то дадаць да мноства ErrU пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘«ў» пасля зычнай «{LastLetter}» і злучка’.
Крок 2.6.4. Калі элемент Chars[A-1] зададзены і Chars[A-1] = «М» або «м», прычым A+2 складае велічыню мноства Chars, то дадаць да мноства ErrU пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘запазычанае слова на «-ум»’.
Крок 2.6.5. Калі элемент Chars[A-1] зададзены і Chars[A-1] = «С» або «с», прычым A+2 складае велічыню мноства Chars, то дадаць да мноства ErrU пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘запазычанае слова на «-ус»’.
Крок 2.7. Калі Chars[A] = «Ў», прычым хаця б адзін элемент мноства Chars ∈ Lowercase, то дадаць да мноства ErrU пяцёрку <LastLetter, LastSeparator, Chars[A], Context[Chars[A]], Comment>, дзе Comment = ‘ВЯЛІКАЯ «Ў» ДАЗВАЛЯЕЦЦА ТОЛЬКІ Ў ТЭКСТАХ, ДЗЕ ЎСЕ СЛОВЫ ПІШУЦЦА ВЯЛІКІМІ ЛІТАРАМІ’.
Крок 2.8. Калі дасягнуты апошні элемент мноства Chars, абнуліць A і задаць новае значэнне пераменнай LastLetter = Chars[B], дзе B – велічыня мноства Chars, а LastSeparator зрабіць роўным парнаму элементу бягучага элемента Words масіву WordsAndSeparators. Калі пры гэтым дасягнуты апошні элемент масіву WordsAndSeparators, інкрэментаваць Z, абнуліць X і A і перайсці да кроку 2.1. Калі апошні элемент мноства Chars не дасягнуты, то здзейсніць інкрэментацыю A і перайсці да кроку 2.5. Калі дасягнуты апошні элемент мноства Lines, перайсці да кроку 3.
Крок 3. Паслядоўна вывесці на экран змест мностваў ErrUn і ErrU.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Графічны інтэрфейс сэрвіса прадстаўлены на малюнку 1.
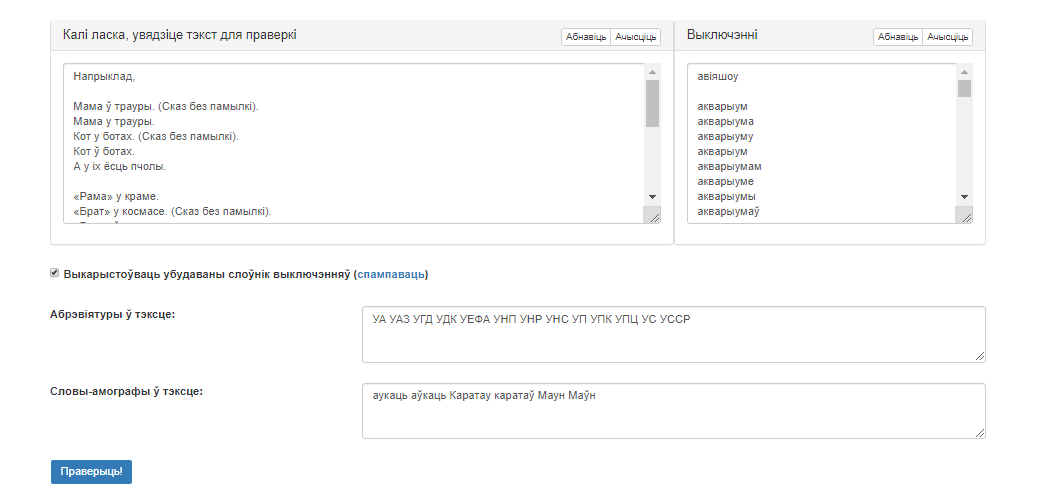
Малюнак 1 – Графічны інтэрфейс сэрвіса «Праверка правапісу «ў»
Інтэрфейс мае наступныя вобласці:
-
Поле для карыстальніцкага ўводу тэксту для праверкі
-
Поле «Выключэнні» для карыстальніцкага ўводу выключэнняў
-
Опцыя «Слоўнік выключэнняў» (далучае да праверкі слоўнік выключэнняў, які мае прыярытэт над зместам поля «Выключэнні»)
-
Поле для ўводу абрэвіятур, якія могуць сустрэцца ў тэксце
-
Кнопка «Праверыць!»: па націсканні дадзенай кнопкі карыстальнік атрымлівае вынік апрацоўкі тэксту сэрвісам
Палі ўводу тэксту для праверкі і ўводу выключэнняў забяспечаны кнопкамі «Абнавіць» (вяртанне дадзеных па змаўчанні) і «Ачысціць» (выдаленне ўсіх дадзеных).
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Атрыманне дадзеных пра памылковае ўжыванне літар «у» («У») і «ў» («Ў») з апорай на карыстальніцкі спіс выключэнняў
1. Увесці з клавіятуры ці скапіраваць з буфера абмену тэкст у адпаведнае поле ўводу.
2. Увесці ўласны спіс выключэнняў у поле «Выключэнні» ці дапоўніць/зменшыць спіс, прапанаваны па змаўчанні.
3. Пераканацца, што сцяжок «Слоўнік выключэнняў» зняты (калі не, то зняць яго).
4. Пры неабходнасці адрэдагаваць змест поля «Абрэвіятуры ў тэксце».
5. Націснуць кнопку «Праверыць!» і атрымаць вынікі.
Сцэнар 2. Атрыманне дадзеных пра памылковае ўжыванне літар «у» («У») і «ў» («Ў») з апорай на слоўнік выключэнняў
1. Увесці з клавіятуры ці скапіраваць з буфера абмену тэкст у адпаведнае поле ўводу.
2. Пераканацца, што сцяжок «Сслоўнік выключэнняў» адзначаны (калі не, то адзначыць яго).
3. Пры неабходнасці адрэдагаваць змест поля «Абрэвіятуры ў тэксце».
4. Націснуць кнопку «Праверыць!» і атрымаць вынікі.
Магчымы вынік працы сэрвіса прадстаўлены на малюнку 2.

Малюнак 2 – вынік працы сэрвіса «Праверка правапісу «ў»
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Праверка правапісу «ў» праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/ShortUSpellChecker/api.php. Праз масіў data перадаюцца наступныя параметры:
- inputText — адвольны ўваходны тэкст на беларускай мове.
- exceptions — спіс выключэнняў.
- abbreviations — спіс абрэвіятур.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/ShortUSpellChecker/api.php”,
data:{
“inputText“: “Кот ў ботах.
На Ўкраіне паўднёва-усходні вецер.
Тата любіць бульбў.”,
“exceptions“: “авіяшоу акварыум”,
“abbreviations“: “УНР УДК“
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з уваходным тэкстам (параметр text), табліцу выпадкаў памылковага ўжывання літары «ў» (параметр res_unc) і табліцу выпадкаў памылковага ўжывання літары «у» (параметр res_uc). Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “Кот ў ботах.
На Ўкраіне паўднёва-усходні вецер.
Тата любіць бульбў.”,
“res_unc“: “<table class=”pale” width=”100%”><tbody><tr><td width=”50%” valign=”top”><b>Сустрэлася</b></td><td width=”50%” valign=”top”><b>Каментар</b></td></tr><tr><td width=”50%” valign=”top”>«<font color=”red”>а-у</font>»: …ботах.
На Ўкраіне паўднёв<font color=”red”>а-у</font>сходні вецер.
Тата любіць …”</td><td width=”50%” valign=”top”> <i>(«у» пасля галоснай «а» і злучка)</i></td></tr></tbody></table>”,
“res_uc“: “<table class=”pale” width=”100%”><tbody><tr><td width=”50%” valign=”top”><b>Сустрэлася</b></td><td width=”50%” valign=”top”><b>Каментар</b></td></tr><tr><td width=”50%” valign=”top”>«<font color=”red”>т ў</font>»: …Ко<font color=”red”>т ў</font> ботах.
На Ўкраіне …”</td><td width=”50%” valign=”top”> <i>(«ў» пасля зычнай «т» без знакаў прыпынку)</i></td></tr><tr><td width=”50%” valign=”top”>«<font color=”red”>Ў</font>»: …ў ботах.
На <font color=”red”>Ў</font>краіне паўднёва-усходні вецер.
Тата …”</td><td width=”50%” valign=”top”> <i>(ВЯЛІКАЯ «Ў» ДАЗВАЛЯЕЦЦА ТОЛЬКІ Ў ТЭКСТАХ, ДЗЕ ЎСЕ СЛОВЫ ПІШУЦЦА ВЯЛІКІМІ ЛІТАРАМІ)</i></td></tr><tr><td width=”50%” valign=”top”>«<font color=”red”>бў</font>»: …вецер.
Тата любіць буль<font color=”red”>бў</font>.…”</td><td width=”50%” valign=”top”> <i>(«ў» пасля зычнай «б»)</i></td></tr></tbody></table>”
}
]
Старонка сэрвіса – https://corpus.by/ShortUSpellChecker/?lang=be
Перакрыжаваныя спасылкі
- Гецэвіч, Ю.С. Камп’ютарна-лінгвістычныя сэрвісы www.corpus.by для аўтаматычнай апрацоўкі тэкстаў / Я.С. Качан, С.І. Лысы, Ю.С. Гецэвіч, Г.Р. Станіславенка, А.В. Гюнтар // Нацыянальна-культурны кампанент у літаратурнай і дыялектнай мове : зб. навук. арт. / Брэсц. дзярж. ун-т імя А. С. Пушкіна ; рэдкал.: С. Ф. Бут-Гусаім [і інш.]. – Брэст : БрДУ, 2016. — C. 93-104.
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Казлоўская, Н.Д. Этапы і асаблівасці перакладу юрыдычнай лексікі на прыкладзе Кодэкса аб шлюбе і сям’і з выкарыстаннем камп’ютарна-лінгвістычных рэсурсаў / Н.Д. Казлоўская, А.У. Бабкоў, Ю.С. Гецэвіч, А.В. Крывальцэвіч, Г.Р. Станіславенка, М.У. Марчык, І.В. Рэентовіч // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы I Респ. науч.-практ. конф. с междунар. участием, Минск, 23–24 февр. 2017 г. / БГУ, факультет социокультурных коммуникаций ; редкол. : О.Г. Прохоренко (отв. ред.) [и др.]. — Минск : Изд. центр БГУ, 2017. — C. 189-191.
- Станіславенка, Г.Р. Рэдагаванне электронных масіваў тэкстаў на беларускай мове з выкарыстаннем камп’ютарна-лінгвістычных сэрвісаў платформы www.corpus.by / Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 262-267.
- Марчык, М.У. Вычытка тэксту вялікага памеру на беларускай мове / М.У. Марчык, С.І. Лысы, Ю.С. Гецэвіч // Лингвистика, лингводидактика, лингвокультурология: актуальные вопросы и перспективы развития : материалы II Междунар. науч.-практ. конф., Минск, 1–2 марта 2018 г. / редкол. : О. Г. Прохоренко (отв. ред.) [и др.]. — Минск : Издательский центр БГУ, 2018. — C. 58-63.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.