Сэрвіс “Падлік частотнасці слоў” вырашае задачу па атрыманні статыстыкі ўжывання адвольных сімвальных паслядоўнасцей у электронным тэксце. Прыватным выпадкам гэтай задачы з’яўляецца задача падліку частаты ўжывання слоў у электронным тэксце.
Асноўныя тэрміны і паняцці
Колькасць ужыванняў – абсалютнае колькаснае значэнне ўваходжанняў зададзенай паслядоўнасці сімвалаў (слова) у вызначаную сукупнасць словаўжыванняў (тэкст).
Частотнасць ужывання – тэрмін лексікастатыстыкі, прызначаны для азначэння адноснага колькаснага паказчыка ўваходжанняў зададзенай паслядоўнасці сімвалаў (слова) у вызначаную сукупнасць словаўжыванняў (тэкст). Частотнасць ужывання Freqx вылічваецца паводле формулы
Freqx = Qx / Qall ,
дзе Qx – колькасць ужыванняў слова x, Qall – агульная колькасць словаўжыванняў. У большасці выпадкаў частотнасць ужывання выражаецца ў працэнтах:
Freqx = Qx / Qall * 100% .
“Масавая доля” ўжывання – рабочы тэрмін, які абазначае, колькі фізічна колькасць сімвалаў усіх уваходжанняў зададзенай паслядоўнасці (слова) складае ад агульнай колькасці сімвалаў тэксту. “Масавая доля” ўжывання MFracx выражаецца ў працэнтах і вылічваецца паводле формулы
MFracx = (Symbx * Qx / Symball) * 100% ,
дзе Symbx – колькасць сімвалаў, з якіх складаецца слова x, Qx – колькасць ужыванняў слова x, Symball – агульная колькасць сімвалаў тэксту.
Практычная каштоўнасць
Сэрвіс будзе карысны:
– для лексікографаў, якія займаюцца складаннем частотных слоўнікаў;
– для лінгвістаў, якія займаюцца вызначэннем славеснага каркаса пэўнай мовы (слоў, ведання якіх будзе дастаткова для разумення большасці тэкстаў на гэтай мове);
– для лінгвістаў, якія займаюцца даследаваннямі ў вобласці лінгвістычнай тыпалогіі на падставе аналізу пісьмовых крыніц;
– для спецыялістаў, якія займаюцца вычыткай тэкстаў (знаходжанне памылковых ужыванняў слоў паводле шаблона памылковага ўжывання);
– для патрэб стылістычнай карэктуры тэкстаў – вызначэння занадта частага ўжывання пэўнага слова (і наступнай ручной замены яго сінанімічным) і знаходжання “слоў-паразітаў”.
Асаблівасці сэрвіса
– Сэрвіс дазваляе апрацоўваць тэксты на многіх натуральных і штучных сімвальных мовах (калі сімвалы алфавіта мовы ўведзены ў адмысловае поле);
– У выпадку працы з беларускай мовай сэрвіс вызначае літары У і Ў як звычайныя асобныя сімвалы, таму, напрыклад, слова “узвышша” ў кантэкстах “пад узвышшам” і “на ўзвышшы” будзе вызначана як два асобныя словаўжыванні;
– Сэрвіс не выконвае распазнаванне злучкоў і знакаў пераносу слова ў зыходным тэксце, лічачы злучок і знак пераносу як адзіны сімвал. Калі тэкставы рэдактар, з якога ўзяты зыходны тэкст, аўтаматычна не выдаляе пераносы пры капіраванні, для атрымання карэктных вынікаў карыстальніку давядзецца ўручную выдаліць сімвалы пераносаў;
– На дадзены момант сэрвіс вызначае толькі абсалютную колькасць ужыванняў слоў.
Алгарытм працы сэрвіса
Уваходныя дадзеныя алгарытму:
-
Карыстальніцкі тэкставы ўвод, UText;
-
Мноства слоў, якія ігнаруюцца, IgnWordsList;
-
Мноства сімвалаў, з якіх можа складацца слова, AccSymbList;
-
Мноства сімвалаў, з якіх можа складацца, але з якіх не можа пачынацца слова AccNotStartSymbList;
-
Мноства «Шукаць толькі наступныя словы», WordsForSearchList;
-
Колькасць кантэкстаў QCont;
-
Адчувальнасць да рэгістра CaseSens;
-
Указанне, ці выводзіць асобна левыя і правыя кантэксты LandRCont.
Пачатак алгарытму.
Крок 1. Фарміраванне мностваў UText, IgnWordsList, AccSymbList, AccNotStartSymbList, WordsForSearchList. Мноства UText разбіваецца на падмноствы Paragraphs[1…X з дапамогай рэгулярнага выразу, які раздзяляе элементы тэксту паводле сімвала перавода радка. Дадзеныя мноствы, у сваю чаргу, разбіваюцца на элементы Word[1…X]. Мноствы IgnWordsList, WordsForSearchList, калі яны не пустыя, разбіваюцца на элементы IgnWord[1…X] і SearchWord[1…X] адпаведна з дапамогай рэгулярнага выразу, які раздзяляе элементы тэксту паводле ўсіх сімвалаў водступу. Адзначаныя разбіўкі неабходныя толькі для праграмнай рэалізацыі алгарытму, таму атрыманыя падмноствы і элементы (за выключэннем элементаў Word[X]) не будуць выкарыстоўвацца ў яго далейшым апісанні.
Крок 2.1. Падлік унікальных элементаў мноства UText і карэктыроўка яго складу. З дадзенага мноства выключаюцца элементы, якія не адпавядаюць наступным умовам: Word[X] ∈ AccSymbList (пасімвальная праверка), Word[X] ∈ WordsForSearchList (калі WordsForSearchList = ∅, дадзеная ўмова не правяраецца), Word[X][1] ∉ AccNotStartSymbList, Word[X] ∉ IgnWordsList. Пры гэтым, калі нейкі элемент мноства WordsForSearchList ∉ UText, пошук па ім ажыццяўляцца не будзе.
Крок 2.2. Калі ўмова CaseSens = false, адбываецца прывядзенне ўсіх элементаў UText да ніжняга рэгістра і атаясамліванне аднолькавых элементаў, затым – пераход да кроку 2.3. Калі ўмова CaseSens = true, адбываецца просты пераход да кроку 2.3.
Крок 2.3. Падлік колькасці аднолькавых элементаў Q[Word[X]] мноства UText і фарміраванне для кожнага такога элемента мноства кантэкстаў Contexts = {LContexts, RContexts} пры LandRCont = true, Contexts = {SingCont} пры LandRCont = false. Пры гэтым таксама, калі LandRCont = true, здзяйсняецца фарміраванне левых і правых кантэкстаў для кожнага ўваходжання кожнага элемента UText, калі LandRCont = false, фарміруюцца адзіныя кантэксты для кожнага ўваходжання кожнага элемента UText.
Крок 3. Вывад вынікаў. Калі LandRCont = true, фарміруецца вывад вынікаў на экран у выглядзе табліцы, кожны радок якой складаецца з чацвёрак <Q[Word[X]], LContexts[X], Word[X], RContexts[X]>, калі LandRCont = false, здзяйсняецца вывад, які складаецца з троек <Q[Word[X]], Word[X], SingCont[X]>. Пры гэтым для кожнага элемента Word[X] будзе выведзена толькі QCont першых элементаў мноства Contexts.
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Для атрымання неабходнай статыстыкі карыстальнік мае магчымасць увесці адвольны тэкст у поле “Калі ласка, увядзіце тэкст” (лічба “1” на малюнку 1) і задаць (скарэктаваць) змест чатырох мностваў для настройкі працы сэрвіса пад канкрэтную задачу.
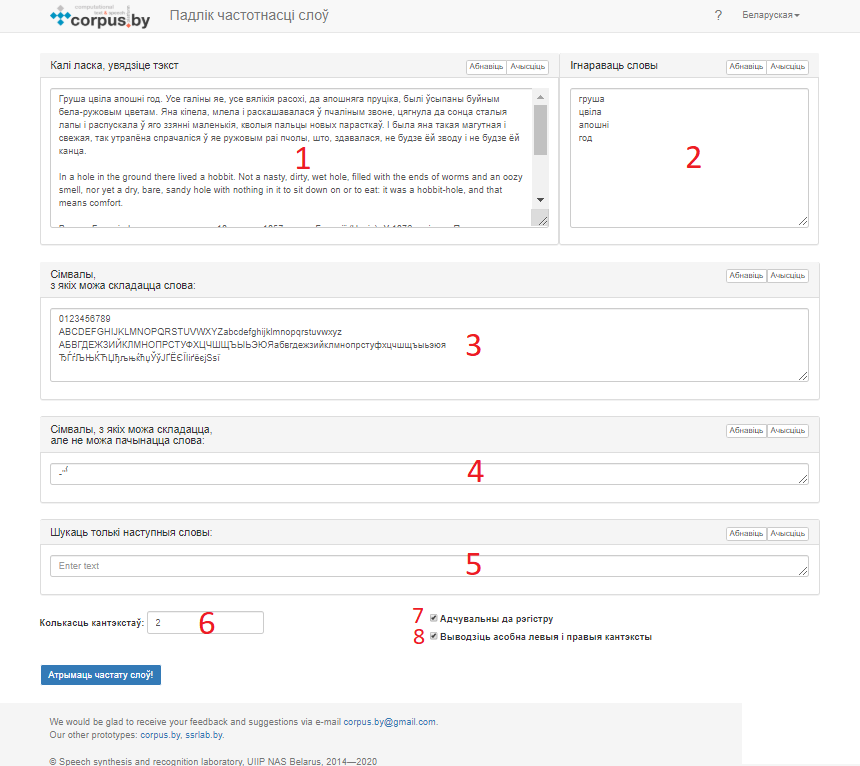
Малюнак 1 – Карыстальніцкі інтэрфейс сэрвіса “Падлік частотнасці слоў”
Першае мноства – паслядоўнасць сімвалаў (словы), якія будуць праігнараваныя сэрвісам падчас падрыхтоўкі статыстыкі (поле “Ігнараваць словы”, лічба “2” на малюнку 1).
Другое мноства – сімвалы, з якіх можа складацца слова. Сюды карыстальнік можа змясціць алфавіт альбо мноства сімвалаў, якія будуць ужывацца для распазнавання слоў у тэксце (поле “Сімвалы, з якіх можа складацца слова”, лічба “3” на малюнку 1).
Па змаўчанні ў полі “Сімвалы, з якіх можа складацца слова” змешчаныя ўсе літарныя сімвалы кадзіроўкі “Windows-1251” і сімвалы лічбаў:
0123456789
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюя
ЂЃѓЉЊЌЋЏђљњќћџЎўЈҐЁЄЇІіґёєјЅѕї
Важна: калі паслядоўнасць “сімвалы ад прабелу да прабелу” змяшчае вакол сябе сімвалы, якіх няма ў другім мностве, пры ўказанні станоўчай колькасці кантэкстаў яны будуць выведзеныя з боку іх размяшчэння. Калі ўказаная паслядоўнасць змяшчае сімвалы, якіх няма ў другім мностве, унутры сябе, яны будуць успрынятыя сістэмай як раздзяляльнікі паслядоўнасці.
Трэцяе мноства – сімвалы, з якіх можа складацца, але не можа пачынацца слова. Па змаўчанні гэта сімвалы асноўнага і частковага націскаў, апостраф і злучок (поле “Сімвалы, з якіх можа складацца, але не можа пачынацца слова”, лічба “4” на малюнку 1).
Важна: пры апрацоўцы дадзенага мноства алгарытм улічвае рэгістр сімвалаў.
Чацвёртае мноства – спіс, які змяшчае словы, па якіх (і толькі па якіх) карыстальнік жадае атрымаць статыстыку (поле “Шукаць толькі наступныя словы”, лічба “5” на малюнку 1).
Калі пакінуць дадзенае поле пустым, сэрвіс выведзе статыстыку па ўсіх словах, якія сустракаюцца ў тэксце, улічваючы дадзеныя мностваў 1, 2 і 3.
Важна: Першае мноства (“Ігранаваць словы”) мае прыярытэт над чацвёртым. Гэта значыць, што, калі слова адначасова занесена і ў першае, і ў чацвёртае мноства, яно будзе праігнаравана сэрвісам.
Карыстальнік можа атрымліваць пэўную колькасць кантэкстаў кожнай са знойдзеных сімвальных паслядоўнасцей, пазначыўшы ў полі “Колькасць кантэкстаў” (лічба “6” на малюнку 1) цэлы станоўчы лік (любыя іншыя дадзеныя будуць успрынятыя сэрвісам як лік “0”). Апроч таго, карыстальнік мае наступныя магчымасці:
– пазначыць, ці патрэбна пры падліку статыстыкі ўлічваць рэгістр літар, з якіх складаюцца словы ўваходнага тэксту, словы, якія ігнаруюцца, і словы, вызначаныя для пошуку (опцыя “Адчувальны да рэгістра”, лічба “7” на малюнку 1)
– пазначыць фармат вываду канчатковых дадзеных (опцыя “Выводзіць асобна левыя і правыя кантэксты”, лічба “8” на малюнку 1). Кантэкст уключае ў сябе да трох слоў перад і да трох слоў пасля знойдзенага слова і складаецца са слоў, змешчаных ад пачатку да канца кожнага радка тэксту (мяжа радка вызначаецца нябачным карыстальніку сімвалам пераводу радка).
Палі для ўводу асноўных дадзеных забяспечаныя кнопкамі “Абнавіць” (вяртанне дадзеных поля па змаўчанні) і “Ачысціць” (выдаленне ўсіх дадзеных). Выніковая табліца забяспечаная кнопкай “Капіраваць” для капіравання дадзеных у тэкставым фармаце; таксама табліцу можна адсарціраваць па любым з яе слупкоў.
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Атрыманне статыстыкі па ўсіх словах уваходнага тэксту
1. Увесці з клавіятуры ці скапіраваць з буфера абмену адвольны тэкст у поле ўводу тэксту.
2. Ачысціць дадзеныя поля “Ігнараваць словы”. Палі “Сімвалы, з якіх можа складацца слова” і “Сімвалы, з якіх можа складацца, але не можа пачынацца слова” пакінуць без змен, поле “Шукаць толькі наступныя словы” пакінуць пустым.
3. Указаць патрэбную колькасць кантэкстаў у полі “Колькасць кантэкстаў”.
4. Вызначыць, ці патрэбна ўлічваць рэгістр і выводзіць асобна левыя і правыя кантэксты з дапамогай адпаведных опцый.
5. Націснуць кнопку “Атрымаць частату слоў!” і атрымаць статыстыку.
Вынікі будуць мець выгляд, падобны да адлюстраванага на малюнках 2 і 3.

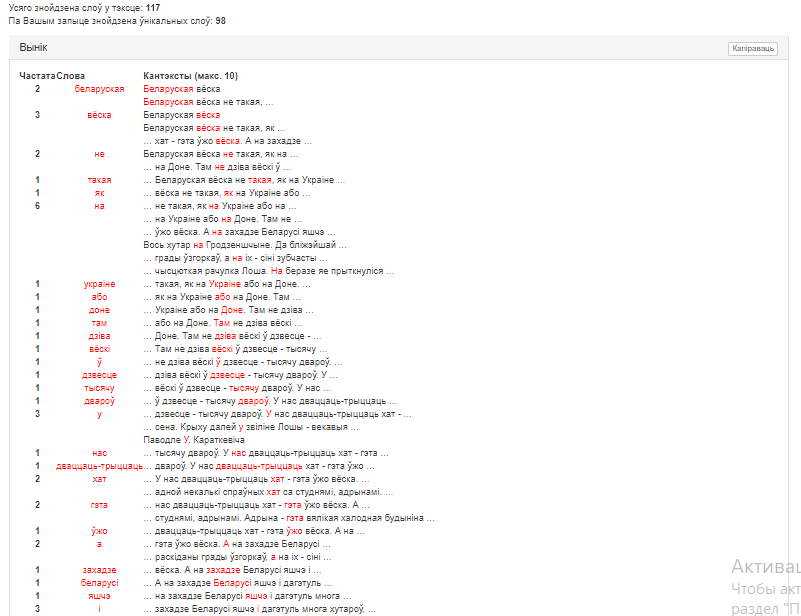
Малюнкі 2, 3 – Атрыманне статыстыкі па ўсіх словах уваходнага тэксту
Сцэнар 2. Атрыманне статыстыкі па асобных словах уваходнага тэксту
1. Увесці з клавіятуры ці скапіраваць з буфера абмену адвольны тэкст у поле ўводу тэксту.
2. Запоўніць поле “Ігнараваць словы” (пры неабходнасці).
3. Змяніць змест палёў “Сімвалы, з якіх можа складацца слова” і “Сімвалы, з якіх можа складацца, але не можа пачынацца слова” (пры неабходнасці).
4. Задаць патрэбныя словы для пошуку з дапамогай поля “Шукаць толькі наступныя словы”
5. Указаць патрэбную колькасць кантэкстаў у полі “Колькасць кантэкстаў”.
6. Вызначыць, ці патрэбна ўлічваць рэгістр і выводзіць асобна левыя і правыя кантэксты з дапамогай адпаведных опцый.
7. Націснуць кнопку “Атрымаць частату слоў!” і атрымаць статыстыку.
Прыклад запаўнення палёў і вызначэнне опцый прадстаўлены на малюнку 4, вынік працы сэрвіса пры падобных уводных дадзеных – на малюнку 5.
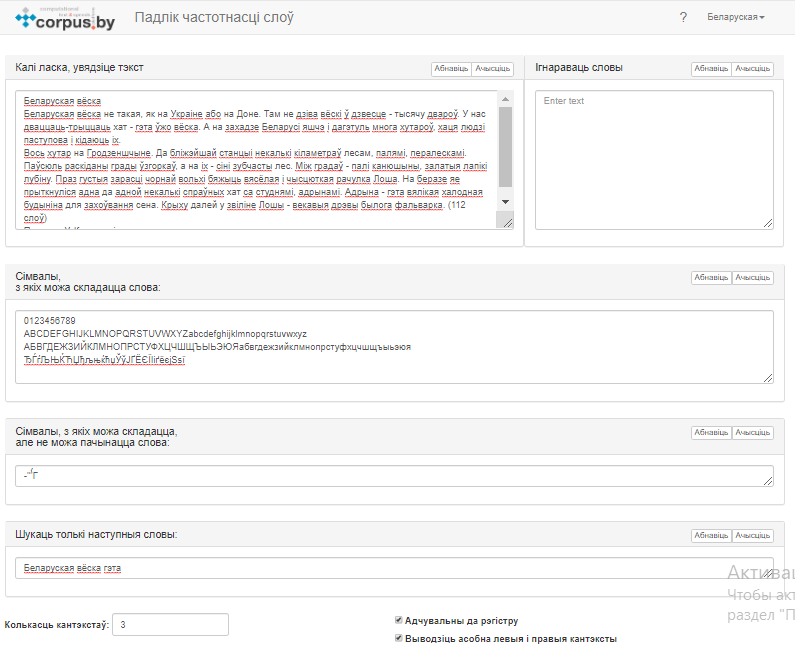
Малюнак 4 – Атрыманне статыстыкі па асобных словах уваходнага тэксту – прыклад зыходных дадзеных

Малюнак 5 – Атрыманне статыстыкі па асобных словах уваходнага тэксту – прыклад выніку працы сэрвіса
Доступ да сэрвіса праз API
Для доступу да сэрвіса “Падлік частотнасці слоў” праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/WordFrequencyCounter/api.php.
Элементы ўваходнага масіву data маюць наступныя параметры
- text — адвольны ўваходны тэкст.
- stop_words — спіс стоп-слоў – слоў, падлік якіх не павінен весціся. Словы падаюцца праз прабел ці перавод радка.
- words_to_count — спіс слоў для падліку. Уводзіцца пры неабходнасці падліку канкрэтных слоў. Словы падаюцца праз прабел ці перавод радка.
- symbols_of_words — спіс сімвалаў, з якіх можа складацца слова.
- symbols_in_words — спіс сімвалаў, з якіх можа складацца, але не можа пачынацца слова.
- contextsMax — максімальная колькасць кантэкстаў. Пры значэнні “0” вывад кантэкстаў не адбываецца.
- caseSensitive — маркер адчувальнасці да рэгістра. Пры значэнні “1” падлік частотнасці слоў адбываецца з улікам рэгістра, пры значэнні “0” – без уліку рэгістра.
- contextSensitive — маркер вываду левага і правага кантэкстаў у асобных слупках злева і справа ад слова. Пры значэнні “1” левы і правы кантэксты выводзяцца ў асобных слупках злева і справа ад слова, пры значэнні “0” – левы і правы кантэксты выводзяцца ў адным слупку разам са словам.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/WordFrequencyCounter/api.php”,
data:{
“text”: “Груша цвіла апошні год.”,
“stop_words”: “груша цвіла апошні”,
“words_to_count”: “”,
“symbols_of_words”: “0123456789\nABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz\nАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюя\nЂЃѓЉЊЌЋЏђљњќћџЎўЈҐЁЄЇІіґёєјЅѕї”,
“symbols_in_words”: “-‘’ʼ̀́”,
“contextsMax“: “2″,
“caseSensitive“: “1″,
“contextSensitive“: “1″
}
success: function(msg){ }
});
Сервер верне JSON-масіў з уваходным тэкстам (параметр text), колькасцю слоў ва ўваходным тэксце (параметр wordsCnt), колькасцю ўнікальных слоў ва ўваходным тэксце (параметр uniqueCnt) і выніковай табліцай (параметр result). Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “Груша цвіла апошні год.”,
“wordsCnt”: 4,
“uniqueCnt”: 1,
“result”: “<table class=”sort”><thead><tr><td>Частата</td><td>Левыя кантэксты (макс. 2)</td><td>Слова</td><td>Правыя кантэксты (макс. 2)</td></tr></thead><tbody><tr valign=”top”><td width=”100″ align=”center”><b>1</b></td><td align=”right”><br></td><td width=”150″ align=”center”><font color=”red”>Груша</font></td><td> цвіла апошні год.<br></td></tr></tbody></table>”
}
]
Старонка сэрвіса – https://corpus.by/WordFrequencyCounter/?lang=be
Перакрыжаваныя спасылкі
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Станіславенка, Г.Р. Рэдагаванне электронных масіваў тэкстаў на беларускай мове з выкарыстаннем камп’ютарна-лінгвістычных сэрвісаў платформы www.corpus.by / Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 262-267.
- Гецэвіч, Ю.С. Праектаванне інтэрнэт-сервісаў для працэсараў сінтэзатара маўлення па тэксце з магчымасцю прадстаўлення бясплатных электронных паслуг насельніцтву / Ю.С. Гецэвіч, С.І. Лысы // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2014) : доклады XIII Международной конференции (Минск, 20 ноября 2014 г.). – Минск : ОИПИ НАН Беларуси, 2014. — C. 265-269.