Другую частку размовы мы пачнем са спасылкі на некалькі прыкладаў працы сінтэзатара маўлення.
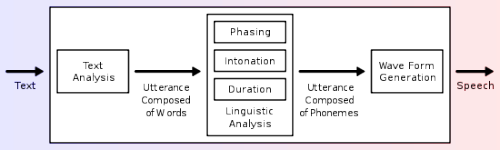
Спадар Юрась, у папярэдняй частцы Вы сказалі, што ваша лабараторыя адчынена для ўсіх, хто цікавіцца. У апошні год колькі да вас прыйшло людзей і падкажыце, куды ўвогуле звяртацца, каб трапіць у лабараторыю. Якія павінен быць узровень ведаў?
Людзей праз нас праходзіць вельмі шмат. Калі глядзець нашы справаздачы за год, ёсць нагрузкі па ВНУ: дыпломнікі – 7 чалавек за 2014 год, курсавыя – 2, практыканты – 13.
У сярэднім 30 чалавек – гэта людзі, якія па заданнях звязаны са сваімі ВНУ і праходзяць гэтыя заданні на практычным матэрыяле нашай лабараторыі. І сама лабараторыя – 15-18 чалавек.
Мы ездзім выступаць у розныя школы, выступаем на канферэнцыях. Спісы прыемна заўсёды паказаць, колькі людзей нас ведае. Кіеў, Талін, Беларусь, Украіна, Чэхія, Італія, Масква – спіс паездак за 2015 і мінулы год. Некаторы час назад да нас прыязджаў спецыяліст з Францыі, рабілі яму сустрэчы па ўсіх ВНУ, дзе ён меў магчымасць прачытаць лекцыі і правесці майстар-класы.
Усё больш нас запрашаюць. Мерапрыемстваў дастаткова, нават, бывае, складана планаваць, цяжка сказаць, што будзе на наступным тыдні: магчымыя сустрэчы, запрашэнні могуць узнікнуць у любы час. Мы стараемся быць вельмі адчыненымі.
Так, гэта вельмі добра. Тым больш гэта супадае з мэтай нашай суполкі NLProc.by: распаўсюд ведаў і развіццё галіны ў Беларусі.
Хто яшчэ ў нашай краіне займаецца камп’ютарнай лінгвістыкай?
Так, ёсць такія людзі. Напрыклад, наш кіраўнік, Барыс Мяфодзьевіч Лабанаў вырасціў цэлую школу ў Беларусі, яго вучнямі з’яўляюцца А.Б.Карнеўская, Б.В.Панчанка, А.С.Рылоў, Т.В.Леўкоўская, Г.В.Лосік, Л.І.Цырульнік, А.Г.Давыдаў, І.Э.Хейдараў, М.П.Дзегцяроў, В.У.Кісялёў і многія іншыя. Мы ўжо пятае пакаленне школы. Хтосьці з іх мае адносіны да вядомай кампаніі Сакрамент; хтосьці – да філіялу цэнтру маўленчай інфармацыі. Нашае адрозненне ў тым, што мы працуем пастаянна, улічваючы нашую адукацыйную мэту.
Мы займаемся кампіляцыйным метадам сінтэзу ў адрозненне ад вядомага unit selection метада на аснове алафонаў, па скарочанай базе агучкі (да 10 хвілін). З аднаго боку атрымоўваецца танней, каштуе 1-2 чалавекі-год на першую версію, і паляпшаць яго можна да бясконцасці. Метад на аснове Unit Selection каштуе каля 10 чалавека-год. Акрамя сінтэзу мы займаемся і распазнаваннем маўлення. Таксама зараз дадаем яго да мабільных робатаў.
Вельмі цікава, раскажыце.
Разам з сектарам робататэхнікі мы працуем над робатамі, якія размаўляюць па-беларуску. Адзін з іх быў прадэманстраваны на TIBO некалькі год таму.

Дзе можна іх выкарыстоўваць?
Напрыклад, для адукацыі, ці хатнія робаты, якія могуць распазнаваць каманды ад чалавека і ад іншых робатаў.
На якім этапе зараз праца?
Працуючы разам з сектарам робататэхнікі, мы дадалі першую версію сінтэзу. Здаецца, робата зараз разабралі, але ёсць відэафайл яго працы. Стараемся дабавіць маўленне і слых. Асабліва прапрацоўваем праблему электроннага слыху, таму што падчас руху робата ёсць гукі ад асяроддзя, якія не з’яўляюцца камандамі.
Дзякую, гэта вельмі цікава, чакаем дэманстрацыі робата, які размаўляе па-беларуску на якой-небудзь з сустрэч нашай суполкі. Наступнае пытанне будзе такое: якія, на Ваш погляд, зараз трэнды развіцця ў камп’ютарнай лінгвістыцы ў нашай краіне і свеце?
Так, гэта трэба размяжоўваць, таму што ў Беларусі шмат робіцца для свету, але пра гэта самі беларусы ня ведаюць. Недаўна даведаўся, што некаторыя кампаніі тут робяць прадукты для Samsung па разпазнаванні, вылучэнні прозвішчаў, імёнаў – гэта добры вынік.
Канешне, у нас рынак малы.
Напрыклад, IHS (раней Invention Machine), Сакрамент, некалькі іншых афшорных кампаній, Яндэкс можна назваць, таму што займаецца пошукам і іnformation retrieval.
Дарэчы, нядаўна, апошняя кампанія зрабіла сваю рэалізацыю tomita parser open source. І апошняе пытанне: з чаго пачынаць тым, хто пачынае цікавіцца галіною?
У нас ёсць напрацаваная база лабараторных працаў, у тым ліку па сінтэзе. Таксама па NooJ, шмат матэрыялаў можна знайсці на нашым сайце прататыпаў ці сайце лабараторыі, на якіх шмат адкрытых кавалкаў. Але ж толькі практыка – самы надзейны шлях. Раю шукаць нейкі open source праект, над якім дапамогуць працаваць тыя, у каго ёсць вопыт. Наконт кніг: тут іх вельмі шмат, адна горшая, другая лепшая. Але ж практыка лепш за ўсё!
Дзякую за інтэрв’ю. Да сустрэчы.
Дзякую Вам.
Крыніца тэксту: http://nlproc.by/post/120085283115