Сэрвіс «Праверка правапісу» прызначаны для праверкі правільнасці напісання слоў. На ўваход сэрвісу падаецца электронны тэкст, які патрабуе праверкі. Па націсканні кнопкі «Праверыць!» сэрвіс параўноўвае словы тэксту са словамі ў падключаных слоўніках. Знойдзеныя хаця б у адным са слоўнікаў словы ўваходнага тэксту сэрвіс кваліфікуе як напісаныя правільна і адкідае. Словы, не знойдзеныя ў слоўніках, сэрвіс кваліфікуе як напісаныя няправільна і выводзіць у выглядзе спіса ў алфавітным парадку.
Асноўныя тэрміны і паняцці
Арфаграфія, правапіс – аднастайнасць перадачы слоў і граматычных форм пісьмовага маўлення. Таксама збор правілаў, які забяспечвае гэтую аднастайнасць.
Вычытка – праверка напісанага тэксту перад адпраўкай замоўцу, публікацыяй ці іншым спосабам выкарыстання.
Перабор па слоўніку – спосаб вырашэння прыкладных лінгвістычных задач, які належыць да класа метадаў пошуку рашэння вычарпаннем усіх магчымых варыянтаў. Складанасць поўнага перабору ў агульным выпадку залежыць ад колькасці ўсіх магчымых варыянтаў рашэння задачы.
Практычная каштоўнасць
Сэрвіс мае шырокае кола прымянення і надзвычайную актуальнасць. Якасць вычыткі тэкстаў – гэта на цяперашні момант неад’емнае патрабаванне для многіх сфер дзейнасці, патрабаванне да камунікацыі паміж людзьмі і ўстановамі. Акрамя гэтага, арфаграфічна правільны электронны тэкст – патрабаванне, неабходнае да выканання для правільнага функцыянавання камп’ютарных сістэм чалавека-машынных камунікацый. Актуальнасць развіцця сэрвіса абумоўліваецца таксама ўскладненым доступам да сродкаў апрацоўкі беларускамоўнага тэксту. Так, існуе аматарскі пакет праверкі правапісу для MS Office Word, але ён патрабуе адмысловага пошуку, спампоўвання і ўсталявання [1]. Вычытка электроннага тэксту машыннымі сродкамі заўсёды застаецца актуальнай, паколькі праверка тэкстаў карыстальнікам уручную амаль гарантавана азначае пропуск памылак.
Асаблівасці сэрвіса
Сэрвіс ажыццяўляе праверку шляхам параўнання слоў уваходнага тэксту са словамі ў слоўнікавай базе. Гэтая слоўнікавая база на цяперашні момант уключае слоўнікі, пералічаныя ў табліцы 1.
Табліца 1 – Характарыстыка слоўнікаў, якімі карыстаецца сэрвіс «Праверка правапісу»
|
Уключаны па змаўчанні |
Назва слоўніка |
Каментары |
Мова слоўніка |
|
Так |
SBM1987 |
Паводле публікацыі «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987» | Беларуская |
|
Так |
SBM2008 |
Слоўнік беларускай мовы паводле Belarusian Grammar Database (bnkorpus.info). Authors: Symon Kakora, Aleś Bułojčyk, Uladź Koščanka. На ўмовах ліцэнзіі CC BY-SA 4.0 | Беларуская |
|
Так |
SBM2012initial |
Пачатковыя формы паводле публікацыі «Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. – Мінск : Беларус. навука, 2012» | Беларуская |
|
Так |
NOUN2013 |
Паводле публікацыі «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013» | Беларуская |
|
Так |
ADJECTIVE2013 |
Паводле публікацыі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013» | Беларуская |
|
Так |
NUMERAL2013 |
Паводле публікацыі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013» | Беларуская |
|
Так |
PRONOUN2013 |
Паводле публікацыі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013» | Беларуская |
|
Так |
VERB2013 |
Паводле публікацыі «Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013» | Беларуская |
|
Так |
ADVERB2013 |
Паводле публікацыі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013» | Беларуская |
|
Так |
ZALIZNIAK |
Паводле публікацыі «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. — Москва : Русский язык, 1980. — 880 c.» | Руская |
|
Так |
CMU |
Паводле «Carnegie Mellon University Pronouncing Dictionary» | Ангельская |
|
Не |
TTS |
Новыя словы для сэрвіса «Сінтэзатар маўлення па тэксце» | Беларуская |
|
Не |
S2016_01 |
Слоўнік даступны па спасылцы | Беларуская |
|
Не |
S2016_02 |
Слоўнік даступны па спасылцы | Руская |
|
Так |
S2016_03 |
Слоўнік даступны па спасылцы | Беларуская |
|
Не |
S2017_04 |
Слоўнік даступны па спасылцы | Беларуская |
|
Не |
S2017_05 |
Слоўнік даступны па спасылцы | Беларуская |
|
Не |
*UWP_BE |
Беларускія словы са слоўніка, які даступны па спасылцы | Беларуская |
|
Не |
*UWP_RU |
Рускія словы са слоўніка, які даступны па спасылцы | Руская |
Некаторыя з пералічаных слоўнікаў (пазначаныя *) знаходзяцца ў працэсе пастаяннага папаўнення і развіцця.
Сярод некалькіх існуючых на цяперашні момант сэрвісаў праверкі беларускага правапісу толькі сэрвіс «Праверка правапісу» створаны на аснове праведзенай папярэдне сур’ёзнай навуковай працы, паколькі ён быў распрацаваны як адзін з этапаў папярэдняй апрацоўкі і нармалізацыі тэксту для сінтэзатара маўлення.
Варта зазначыць, што дадзены сэрвіс ахоплівае арфаграфічны раздзел правапісу, але не граматыку, сінтаксіс ці пунктуацыю. Правільнасць дапасавання слоў і расстаноўкі знакаў прыпынку знаходзіцца па-за кампетэнцыяй сэрвіса і застаецца за карыстальнікам або іншымі сэрвісамі, якія таксама задзейнічаныя ў методыцы вычыткі электронных тэкстаў вялікага памеру пры дапамозе сэрвісаў платформы www.corpus.by. Праца сэрвіса і методыка апрабаваныя ў шматлікіх праектах лабараторыі распазнавання і сінтэзу маўлення і знаходзяцца ў стане пастаяннага развіцця і ўдасканальвання.
Сэрвіс «Праверка правапісу» здольны апрацоўваць як невялікія тэксты (ад аднаго ці некалькіх слоў), так і тэксты вялікага памеру. Напрыклад, сэрвісам быў паспяхова правераны правапіс заканадаўчых кодэксаў і літаратурных твораў аб’ёмам каля 470 000 сімвалаў з прабеламі.
Алгарытм працы сэрвіса
Уваходныя дадзеныя алгарытму:
- Карыстальніцкі тэкставы ўвод, UText;
- Карыстальніцкі ўвод слоў для ігнаравання, IgnoreList;
- Максімальная колькасць кантэкстаў, ContextsMax;
- Мноства абраных карыстальнікам слоўнікаў, Dictionaries;
- Мноства літар, з якіх можа складацца слова, AllLetters;
- Мноства лацінскіх сімвалаў у верхнім і ніжнім рэгістры, LettersLat, LettersLat ⊂ AllLetters;
- Мноства ўсіх сімвалаў беларускага алфавіта ў верхнім і ніжнім рэгістры, LettersBel, LettersBel ⊂ AllLetters;
- Мноства ўсіх сімвалаў рускага алфавіта ў верхнім і ніжнім рэгістры, LettersRus, LettersRus ⊂ AllLetters, LettersRus ⋂ LettersBel;
- Мноства ўсіх літар беларускага алфавіта, якія абазначаюць галосныя гукі, у верхнім і ніжнім рэгістры, VovelsBel, VovelsBel ⊂ LettersBel;
- Мноства ўсіх літар беларускага алфавіта, якія абазначаюць зычныя гукі, у верхнім і ніжнім рэгістры, ConsonantsBel, ConsonantsBel ⊂ LettersBel
Пачатак алгарытму.
Крок 1.1. Разбіццё карыстальніцкага тэксту UText на падмноствы радкоў Lines паводле сімвалаў пераводу радка, разбіццё падмностваў Lines на элементы Words; элементам Words лічыцца камбінацыя сімвалаў ад пачатку радка да прабелу, ад прабелу да прабелу і ад прабелу да канца радка, кожны сімвал Char якой адпавядае ўмове Char ∈ AllLetters. Падлік агульнай колькасці элементаў Words, запіс значэння ў пераменную WordsCount.
Крок 1.2. Разбіццё карыстальніцкага спіса выключэнняў IgnoreList на словы, якія складаюць мноства IgnoreListWords.
Крок 1.3. Фарміраванне выніковага мноства Result, якое складаецца з наступных элементаў: падмноства дадзеных для слоў і з кірылічнымі, і з лацінскімі літарамі MixedWords, падмноства дадзеных для слоў, якія не былі знойдзеныя ў слоўніках UnknownTokens. Стварэнне пераменных MixedWordsCount для захавання колькасці элементаў MixedWords і UnknownTokensCount для захавання колькасці элементаў UnknownTokens.
Крок 2.0. Праверка слова Words[A] (дзе A – нумар наступнага элемента мноства) на прыналежнасць да мноства IgnoreListWords. Калі Words[A] ∈ IgnoreListWords, здейсніць пераход да кроку 3.4, інакш – да кроку 2.1.
Крок 2.1. Праверка слова Words[A] на прыналежнасць да адной знакавай сістэмы – кірылічнай ці лацінскай. Для гэтага кожны сімвал Char слова Words[A] паслядоўна правяраецца на ўваходжанне ў мноствы LettersLat, LettersBel і LettersRus. Калі ўсе Char належаць толькі да мноства LettersLat або толькі да мностваў LettersBel і LettersRus, перайсці да кроку 3.1, інакш – здзейсніць крокі 2.1.1 – 2.1.4.
Крок 2.1.1. Падлік колькасці ўваходжанняў Words[A] у мноства Words, запіс значэння ў адмысловую пераменную Words[A].Count.
Крок 2.1.2. Фарміраванне прывязанага да Words[A] мноства кантэкстаў уваходжанняў Words[A], Contexts[A], кожны элемент якога ўключае максімальна магчымую колькасць B элементаў Words, якія ідуць да Words[A], і элементаў Words, якія ідуць пасля Words[A], прычым 0 ≤ B ≤ 3, B ∈ N. Колькасць элементаў Contexts[A] не можа перавышаць значэнне ContextsMax, у выпадку перавышэння будуць уключаныя толькі тыя кантэксты, якія ўвайші ў мноства да дасягнення ліміту.
Крок 2.1.3. Выдзяленне ў Words[A] сімвалаў Char і груп сімвалаў Char, якія не належаць да дамінуючай знакавай сістэмы слова – кірылічнай або лацінскай. “Дамінуючай знакавай сістэмай” лічыцца тая сістэма, да якой належыць першы сімвал або група сімвалаў да перарывання паслядоўнасці іншародным сімвалам. Запіс атрыманага “слова з выдзяленнем” у пераменную WordWithMarkedChars.
Крок 2.1.4. Фарміраванне чацвёркі <Words[A], Words[A].Count, Contexts[A], WordWithMarkedChars>, запіс чацвёркі ў мноства MixedWords, інкрэментацыя MixedWordsCount.
Крок 3.1. Нармалізацыя Words[A] – прывядзенне ў выгляд, прыдатны для параўнання з дадзенымі слоўнікаў, абраных карыстальнікам:
1) прывядзенне ўсіх сімвалаў слова ў ніжні рэгістр;
2) замена ўсіх магчымых сімвалаў апострафа («’», «ʼ», «’», «‘», «′») на адзіны карэктны сімвал «’»;
3) выдаленне націскаў;
4) калі першая літара слова – «ў», замена яе на літару «у».
Крок 3.2. Праверка з дапамогай рэгулярнага выразу, ці ёсць у Words[A] пары сімвалаў <Char + «у»>, дзе Char ∈ VovelsBel, і <Char + «ў»>, дзе Char ∈ ConsonantsBel. Калі такія пары ёсць, здзейсніць крокі 3.2.1 – 3.2.4, інакш – перайсці да кроку 3.3.
Крок 3.2.1. Падлік колькасці ўваходжанняў Words[A] у мноства Words, запіс значэння ў адмысловую пераменную Words[A].Count (аналагічна кроку 2.1.1).
Крок 3.2.2. Фарміраванне прывязанага да Words[A] мноства кантэкстаў уваходжанняў Words[A], Contexts[A], кожны элемент якога ўключае максімальна магчымую колькасць B элементаў Words, якія ідуць да Words[A], і элементаў Words, якія ідуць пасля Words[A], прычым 0 ≤ B ≤ 3, B ∈ N. Колькасць элементаў Contexts[A] не можа перавышаць значэнне ContextsMax, у выпадку перавышэння будуць уключаныя толькі тыя кантэксты, якія ўвайші ў мноства да дасягнення ліміту (аналагічна кроку 2.1.2).
Крок 3.2.3. Атрыманне з Words[A] слова са змененым ужываннем літар «у» і «ў» шляхам замены ўсіх пар сімвалаў <Char+ «у»> на <Char + «ў»> (Char ∈ VovelsBel) і <Char + «ў»> на <Char + «у»> (Char ∈ ConsonantsBel). Запіс слова ў пераменную RecommendedSpelling.
Крок 3.2.4. Фарміраванне чацвёркі <Words[A], Words[A].Count, Contexts[A], RecommendedSpelling>, запіс чацвёркі ў мноства UnknownTokens, інкрэментацыя UnknownTokensCount.
Крок 3.3. Здзейсніць пошук эквіваленту Words[A] сярод усіх элементаў падмностваў, якія складаюць мноства Dictionaries (інакш кажучы, здзейсніць пошук ува ўсіх слоўніках, абраных карыстальнікам). Калі Dictionaries = ∅ або Words[A] ∉ Dictionaries, здзейсніць крокі 3.3.1 – 3.3.3. Калі Words[A] ∈ Dictionaries, перайсці да кроку 3.4.
Крок 3.3.1. Падлік колькасці ўваходжанняў Words[A] у мноства Words, запіс значэння ў адмысловую пераменную Words[A].Count (аналагічна кроку 2.1.1).
Крок 3.3.2. Фарміраванне прывязанага да Words[A] мноства кантэкстаў уваходжанняў Words[A], Contexts[A], кожны элемент якога ўключае максімальна магчымую колькасць B элементаў Words, якія ідуць да Words[A], і элементаў Words, якія ідуць пасля Words[A], прычым 0 ≤ B ≤ 3, B ∈ N. Колькасць элементаў Contexts[A] не можа перавышаць значэнне ContextsMax, у выпадку перавышэння будуць уключаныя толькі тыя кантэксты, якія ўвайші ў мноства да дасягнення ліміту (аналагічна кроку 2.1.2).
Крок 3.3.3. Фарміраванне тройкі <Words[A], Words[A].Count, Contexts[A]>, запіс тройкі ў мноства UnknownTokens, інкрэментацыя UnknownTokensCount.
Крок 3.4. Калі значэнне A меншае за нумар апошняга элемента мноства Words, інкрэментаваць A і перайсці да кроку 2.0. Калі дасягнуты апошні элемент мноства Words, перайсці да кроку 4.
Крок 4. Вывад на экран падмностваў мноства Result і спадарожных дадзеных у наступным парадку:
| СЛОВЫ І З КІРЫЛІЧНЫМІ, І З ЛАЦІНСКІМІ СІМВАЛАМІ ({MixedWordsCount})
{MixedWords} ПАЗНАЧЦЕ СЛОВЫ БЕЗ ПАМЫЛАК І КЛІКНІЦЕ “ПЕРАПРАВЕРЫЦЬ!” ({UnknownTokensCount}) {UnknownTokens} ЗНОЙДЗЕНА ЎНІКАЛЬНЫХ НАПІСАННЯЎ СЛОЎ: {WordsCount} |
Далейшыя крокі алгарытму выконваюцца толькі ў выпадку націскання кнопкі “Пераправерыць!”
Крок 5.1. Выдаленне з мноства UnknownTokens элементаў, адзначаных карыстальнікам (з адпаведным змяншэннем значэння UnknownTokensCount) і занясенне выдаленых элементаў у мноства UserMarkedWords ⊂ Result. Стварэнне пераменнай UserMarkedWordsCount для захавання колькасці элементаў мноства UserMarkedWords.
Крок 5.2. Ачышчэнне поля вываду вынікаў. Вывад на экран падмностваў мноства Result і спадарожных дадзеных у наступным парадку:
| СЛОВЫ І З КІРЫЛІЧНЫМІ, І З ЛАЦІНСКІМІ СІМВАЛАМІ ({MixedWordsCount})
{MixedWords} ПАЗНАЧЦЕ СЛОВЫ БЕЗ ПАМЫЛАК І КЛІКНІЦЕ “ПЕРАПРАВЕРЫЦЬ!” ({UnknownTokensCount}) {UnknownTokens} ПАЗНАЧАНЫЯ СЛОВЫ БЕЗ ПАМЫЛАК ({UserMarkedWordsCount }) {UserMarkedWords} ЗНОЙДЗЕНА ЎНІКАЛЬНЫХ НАПІСАННЯЎ СЛОЎ: {WordsCount} |
Канец алгарытму.
Апісанне інтэрфейсу карыстальніка
Карыстальніцкі інтэрфейс сэрвіса прадстаўлены на малюнку 1.
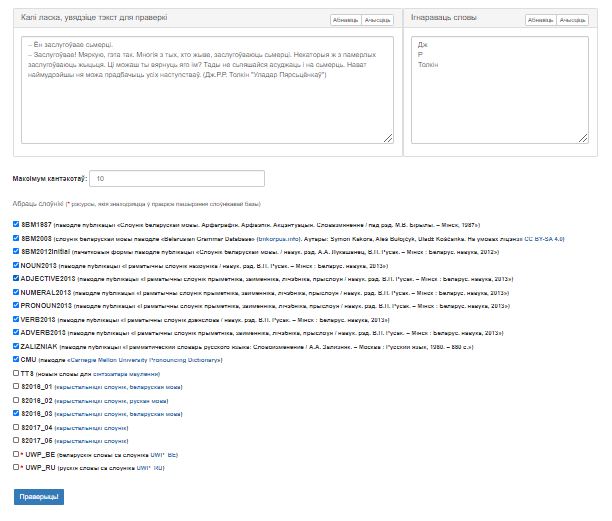
Малюнак 1 – Графічны інтэрфейс сэрвіса “Праверка правапісу”
Інтэрфейс змяшчае наступныя вобласці:
- поле ўводу электроннага тэксту;
- поле «Ігнараваць словы» – поле ўводу слоў, якія павінны ігнаравацца пры праверцы;
- поле «Максімум кантэкстаў» – задаць максімальную колькасць кантэкстаў невядомых слоў;
- поле выбару слоўнікаў;
- кнопка «Праверыць!», якая запускае апрацоўку і дае магчымасць атрымаць вынікі ў полі іх вываду.
Поле ўводу тэксту і поле ўводу слоў для ігнаравання аснашчаныя кнопкамі «Абнавіць» (вяртанне дадзеных па змаўчанні) і «Ачысціць» (выдаленне ўсіх дадзеных).
Пасля апрацоўкі тэксту сэрвісам у полі вываду вынікаў карыстальнік атрымлівае наступныя спісы інфармацыі:
- «Словы і з кірылічнымі, і з лацінскімі сімваламі (колькасць)» – змяшчае словы, у якіх адначасова ўжытыя і кірылічныя, і лацінскія сімвалы, што, верагодней за ўсё, з’яўляецца памылковым напісаннем;
- “«Пазначце словы без памылак і клікніце «Пераправерыць!» (колькасць)» – змяшчае невядомыя сэрвісу словы, у якіх, верагодна, змяшчаецца памылка, што з’яўляецца асноўным вынікам працы сэрвіса, патрэбным карыстальніку;
- «Знойдзена ўнікальных напісанняў слоў (колькасць)» – колькасць слоў ва ўваходным электронным тэксце.
Таксама пасля апрацоўкі тэксту сэрвісам пад дадзенымі спісамі з’явіцца кнопка «Пераправерыць!», па націсканні якой словы, адзначаныя карыстальнікам як напісаныя без памылак, будуць згрупаваныя ў спіс «Пазначаныя словы без памылак».
У правай калонцы выніковай табліцы выдзелены сімвалы, якія не належаць да дамінуючай знакавай сістэмы, з літар якой складаецца слова. «Дамінуючай знакавай сістэмай» лічыцца кірыліца альбо лацінка – у залежнасці ад таго, да якой з іх належыць сімвал ці камбінацыя сімвалаў, што працягваецца ад пачатку слова да іншароднага сімвала. Таксама ў правай калонцы даюцца прапановы па правільным напісанні невядомых сэрвісу слоў (на дадзены момант – толькі для некаторых выпадкаў няправільнага ўжывання літар «у» і «ў»).
Карыстальніцкія сцэнары працы з сэрвісам
Заўвага: для большай якасці праверкі беларускамоўнага тэксту сэрвісам «Праверка правапісу» рэкамендавана напачатку праверыць тэкст праз сэрвіс «Праверка правапісу «ў», прачытаўшы даведку па карыстанні ім.
Сцэнар 1. Праверка адвольнага тэксту цалкам
- Увесці ў поле ўводу тэкст, які патрабуе праверкі.
- Пераканацца, што поле «Ігнараваць словы» пустое. Калі ў ім ёсць нейкія дадзеныя, выдаліць іх уручную або націснуўшы кнопку «Ачысціць».
- У поле «Максімум кантэкстаў» увесці пажаданую колькасць кантэкстаў.
- У полі выбару слоўнікаў абраць патрэбныя слоўнікі, ставячы ці здымаючы значок насупраць слоўніка, альбо пакінуць пазнакі па змаўчанні.
- Націснуць кнопку «Праверыць!» і атрымаць вынік у полі вываду, якое з’явіцца ніжэй.
- Праглядзець спіс «Словы і з кірылічнымі, і з лацінскімі сімваламі (колькасць)», калі такі з’явіўся, і пры патрэбе ўнесці ў зыходны тэкст (напрыклад, у .doc-файл ці старонку) праўкі, замяніўшы няправільна ўжытыя лацінскія сімвалы кірылічнымі.
- Праглядзець спіс «Пазначце словы без памылак і клікніце «Пераправерыць!», знайсці словы з памылкамі і ўнесці ў зыходны тэкст праўкі.
- Захаваць зыходны тэкст.
Сцэнар 2. Праверка адвольнага тэксту з выкарыстаннем спіса слоў для ігнаравання.
- Увесці ў поле ўводу тэкст, які патрабуе праверкі.
- У поле «Ігнараваць словы» ўвесці словы, якія не маюць патрэбы ў праверцы і будуць ігнаравацца сэрвісам. Напрыклад, гэта загадзя невядомыя сэрвісу спецыфічныя словы, якія часта выкарыстоўваюцца ў вузкаспецыяльным тэксце: абрэвіятуры, тэрміналогія і г.д.
- У поле «Максімум кантэкстаў» увесці пажаданую колькасць кантэкстаў.
- У полі выбару слоўнікаў абраць патрэбныя слоўнікі, ставячы ці здымаючы значок насупраць слоўніка, альбо пакінуць пазнакі па змаўчанні.
- Націснуць кнопку «Праверыць!» і атрымаць вынік у полі вываду, якое з’явіцца ніжэй.
- Праглядзець спіс «Словы і з кірылічнымі, і з лацінскімі сімваламі (колькасць)», калі такі з’явіўся, і пры патрэбе ўнесці ў зыходны тэкст (напрыклад, у .doc-файл ці старонку) праўкі, замяніўшы няправільна ўжытыя лацінскія сімвалы кірылічнымі.
- Праглядзець спіс «Пазначце словы без памылак і клікніце «Пераправерыць!», знайсці словы з памылкамі і ўнесці ў зыходны тэкст праўкі.
- Захаваць зыходны тэкст.
Магчымы вынік працы сэрвіса прадстаўлены на малюнку 2.
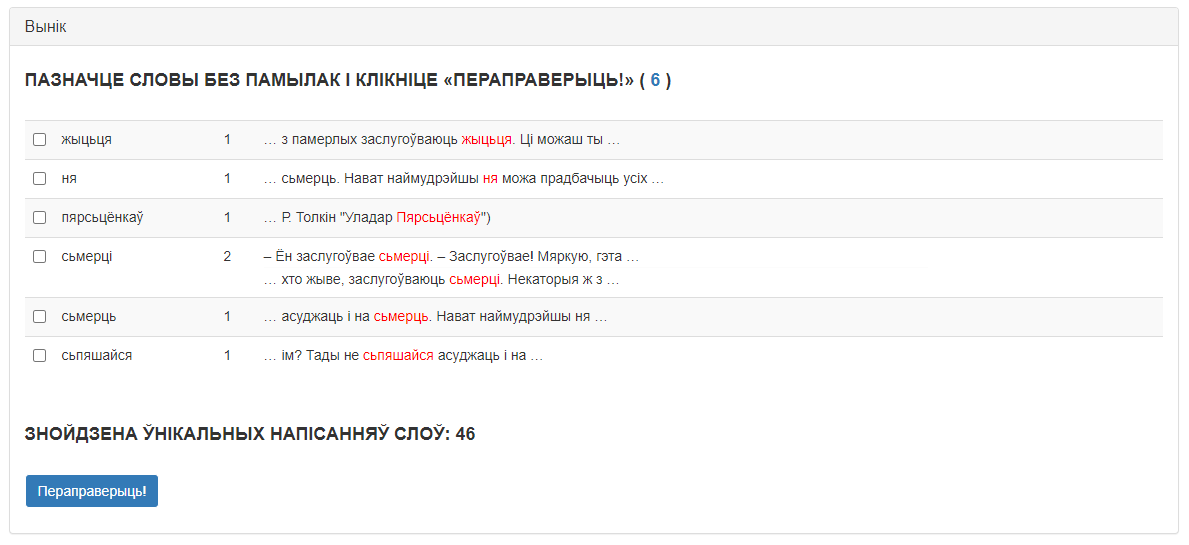
Малюнак 2. Вынік працы сэрвіса «Праверка правапісу»
Доступ да сэрвіса праз API
Для доступу да сэрвіса «Праверка правапісу» праз API неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/SpellChecker/api.php. Праз масіў data перадаюцца наступныя параметры:
- text — адвольны ўваходны тэкст.
- ignoreList — спіс слоў, якія не падлягаюць праверцы.
- maxContexts — абмежаванне па колькасці збіраных кантэкстаў.
- Маркеры выкарыстання слоўнікаў:
- sbm1987 — «Слоўнік беларускай мовы. Арфаграфія. Арфаэпія. Акцэнтуацыя. Словазмяненне / пад рэд. М.В. Бірылы. – Мінск, 1987»;
- sbm2008 — слоўнік беларускай мовы паводле Belarusian Grammar Database (bnkorpus.info);
- sbm2012initial — «Слоўнік беларускай мовы. / навук. рэд. А.А. Лукашанец, В.П. Русак. — Мінск : Беларус. навука, 2012»;
- noun2013 — назоўнікі паводле кнігі «Граматычны слоўнік назоўніка / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adjective2013 — прыметнікі паводле кнігі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- numeral2013 — лічэбнікі паводле кнігі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- pronoun2013 — займеннікі паводле кнігі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- verb2013 — дзеясловы паводле кнігі «Граматычны слоўнік дзеяслова / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- adverb2013 — прыслоўі паводле кнігі «Граматычны слоўнік прыметніка, займенніка, лічэбніка, прыслоўя / навук. рэд. В.П. Русак. – Мінск : Беларус. навука, 2013»;
- zalizniak — «Грамматический словарь русского языка: Словоизменение / А.А. Зализняк. — Москва : Русский язык, 1980. — 880 c.»;
- cmu — «Carnegie Mellon University Pronouncing Dictionary»;
- tts — слоўнік сістэмы сінтэзу маўлення па тэксце;
- S2016_01, S2016_02, S2016_03, S2017_04, S2017_05 — карыстальніцкія слоўнікі;
- uwp_be — беларускія словы, сабраныя сістэмай «Апрацоўка невядомых слоў»;
- uwp_ru — рускія словы, сабраныя сістэмай «Апрацоўка невядомых слоў».
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/SpellChecker/api.php”,
data:{
“text”: “– Ён заслугоўвае сьмерці.
– Заслугоўвае! Мяркую, гэта так. Многія з тых, хто жыве, заслугоўваюць сьмерці. Некаторыя ж з памерлых заслугоўваюць жыцьця. Ці можаш ты вярнуць яго ім? Тады не сьпяшайся асуджаць і на сьмерць. Нават наймудрэйшы ня можа прадбачыць усіх наступстваў. (Дж.Р.Р. Толкін «Уладар Пярсьцёнкаў»)”,
“ignoreList”: “Дж Р Толкін”,
“maxContexts”: 10,
“sbm1987”: 1,
“sbm2008”: 1,
“sbm2012initial”: 1,
“noun2013”: 1
},
success: function(msg){ },
error: function() { }
});
Сервер верне JSON-масіў з уваходным тэкстам (параметр text), спісам адсутных у слоўніку слоў (параметр result) і пашыранай табліцай вынікаў (параметр output). Напрыклад, па вышэй прыведзеным AJAX-запыце будзе сфарміраваны наступны адказ:
[
{
“text”: “Груша цвіла апошні грод.”,
“result”: “жыцьця
ня
пярсьцёнкаў
сьмерці
сьмерць
сьпяшайся”,
“output”: “<h2 class=”sub-caption-smaller”><b>ПАЗНАЧЦЕ СЛОВЫ БЕЗ ПАМЫЛАК І КЛІКНІЦЕ “ПЕРАПРАВЕРЫЦЬ!” ( <a href=”https://corpus.by/showCache.php?s=SpellChecker&t=out&f=2019-09-03_17-03-08_80-94-171-2_255_labeled_unknown.txt”>6</a> )</b></h2><br><table id=”misspellingTableId” class=”pale” width=”100%”><tbody><tr><td width=”2%”><input type=”checkbox” name=”token_0_status” value=”1″></td><td width=”13%”>жыцьця</td><td width=”5%” align=”center”>1</td><td width=”60%”>… з памерлых заслугоўваюць <font color=”red”>жыцьця</font>. Ці можаш ты … </td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_1_status” value=”1″></td><td width=”13%”>ня</td><td width=”5%” align=”center”>1</td><td width=”60%”>… сьмерць. Нават наймудрэйшы <font color=”red”>ня</font> можа прадбачыць усіх … </td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_2_status” value=”1″></td><td width=”13%”>пярсьцёнкаў</td><td width=”5%” align=”center”>1</td><td width=”60%”>… Р. Толкін «Уладар <font color=”red”>Пярсьцёнкаў</font>»)</td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_3_status” value=”1″></td><td width=”13%”>сьмерці</td><td width=”5%” align=”center”>2</td><td width=”60%”>– Ён заслугоўвае <font color=”red”>сьмерці</font>. – Заслугоўвае! Мяркую, гэта … <hr size=”1″ style=”opacity:0.2; margin: 1px 0px;”>… хто жыве, заслугоўваюць <font color=”red”>сьмерці</font>. Некаторыя ж з … </td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_4_status” value=”1″></td><td width=”13%”>сьмерць</td><td width=”5%” align=”center”>1</td><td width=”60%”>… асуджаць і на <font color=”red”>сьмерць</font>. Нават наймудрэйшы ня … </td><td width=”20%”></td></tr><tr><td width=”2%”><input type=”checkbox” name=”token_5_status” value=”1″></td><td width=”13%”>сьпяшайся</td><td width=”5%” align=”center”>1</td><td width=”60%”>… ім? Тады не <font color=”red”>сьпяшайся</font> асуджаць і на … </td><td width=”20%”></td></tr></tbody></table><br><h2 class=”sub-caption-smaller”><b>ЗНОЙДЗЕНА ЎНІКАЛЬНЫХ НАПІСАННЯЎ СЛОЎ: 46</b></h2><br><button type=”button” id=”RecheckButtonId” name=”RecheckButton” class=”blue-button”>Пераправерыць!</button>”
}
]
Спасылкі на крыніцы
Старонка сэрвіса: http://corpus.by/SpellChecker/?lang=be
Старонка сэрвіса «Праверка правапісу «ў»: http://corpus.by/ShortUSpellChecker/?lang=be
Старонка сэрвіса «Сінтэзатар маўлення па тэксце»: http://corpus.by/TextToSpeechSynthesizer/?lang=be
Перакрыжаваныя спасылкі
- Праверка арфаграфіі // Беларускі N-корпус [Электронны рэсурс]. — 2017. Рэжым доступу : http://bnkorpus.info/download.html. — Дата доступу : 07.03.2017.
- Казлоўская, Н.Д. Выкарыстанне камп’ютарна-лінгвістычных рэсурсаў платформы corpus.by пры перакладзе Кодэкса аб шлюбу і сям’і / Н.Д. Казлоўская, Г.Р. Станіславенка, А.В. Крывальцэвіч, М.У. Марчык, А.У. Бабкоў, І.В. Рэентовіч, Ю.С. Гецэвіч // Межкультурная коммуникация и проблемы обучения иностранному языку и переводу : сб. науч. ст. / редкол. : М.Г. Богова (отв. ред), Т.В. Бусел, Н.П. Грицкевич [и др.]. — Минск : РИВШ, 2017. — C. 137-142.
- Drahun, A. Semi-Automatic Proofreading of Belarusian and English texts / A. Drahun, Yu. Hetsevich, A. Bakunovich, Dz. Dzenisiuk, J. Shynkevich // International Conference NooJ 2019: Book of Abstracts. – Hammamet, Tunisia, 2019.
- Станіславенка, Г.Р. Рэдагаванне электронных масіваў тэкстаў на беларускай мове з выкарыстаннем камп’ютарна-лінгвістычных сэрвісаў платформы www.corpus.by / Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Карповские научные чтения / БГУ ; под ред. А.И. Головня [и др.]. — Минск : ИВЦ Минфина, 2016. — C. 262-267.
- Марчык, М.У. Вычытка і генерацыя тэкстаў вялікага памеру на беларускай мове / М.У. Марчык, Г.Р. Станіславенка, С.І. Лысы, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 305-310.