Сэрвіс «Тэматычнае распазнаванне маўлення» дазваляе карыстальніку пераўтварыць маўленне ў электронны тэкст анлайн. На ўваход сэрвісу даецца фанаграма маўленчых слоў тэматычных даменаў памерам не больш за 20 MB, на выхадзе сэрвіс дае распазнаны электронны тэкст фанаграмы. Фанаграма можа быць выбрана з пададзеных прыкладаў, загружана на сэрвіс з цвёрдага дыску камп’ютара ў фармаце .wav, а таксама можа быць запісана праз магчымасці аўдыязапісу сэрвісу.
Практычная каштоўнасць
Распазнаванне маўлення мае вялікія навуковыя перспектывы і шырокія магчымасці прымянення ў шматлікіх сістэмах «чалавек-машына», якія будуюцца на аснове маўленчых зносін. Таксама існуюць іншыя сферы дзейнасці, якія асабліва патрабуюць паслугі па распазнаванні маўлення. Напрыклад, гэта журналістыка, стэнаграфія і многія іншыя.
У прыватнасці, распазнаванне беларускага маўлення, якое становіцца магчымым пры дапамозе дадзенага сэрвісу, дасць магчымасць паўнавартаснага развіцця беларускіх тэхнічных навук, у тым ліку робататэхнікі.
Асаблівасці сэрвісу
На дадзены момант сэрвіс з’яўляецца дэманстрацыйным і распазнае беларускае маўленне наступных тэматычных даменаў:
- вопратка;
- гарады;
- лікі;
- спантаннае маўленне.
Спіс даменаў будзе папаўняцца.
Сэрвіс выкананы і працуе паводле інструкцыі па стварэнні праграм на базе CMU Sphinx [1].
Карыстальніцкі інтэрфейс
Графічны інтэрфейс сэрвісу прадстаўлены на малюнку 1.
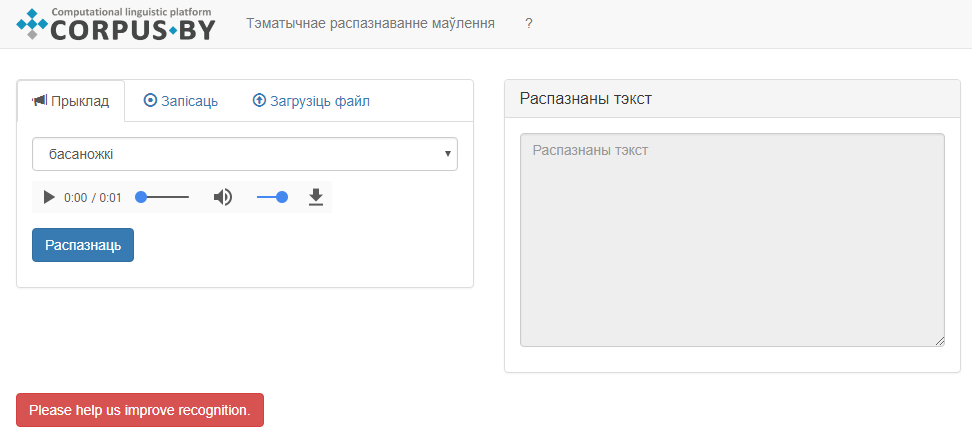
Малюнак 1. Знешні інтэрфейс сэрвісу «Тэматычнае распазнаванне маўлення»
Інтэрфейс мае дзве наступныя вобласці:
- вобласць уводу гукавога файла (злева), якая мае ўкладкі з наступнымі магчымасцямі:
- азнаёміцца з распазнаваннем маўлення дзякуючы ўбудаваным прыкладам;
- загрузіць файл для распазнавання з цвёрдага дыску;
- запісаць маўленчую фразу для распазнавання анлайн;
- вобласць вываду распазнанага электроннага тэксту (справа).
Карыстальніцкія сцэнары працы з сэрвісам
Сцэнар 1. Распазнаванне маўлення з убудаваных прыкладаў
- Зайшоўшы на старонку сэрвісу, націснуць укладку «Прыклад».
- Абраць адно з прапанаваных у выпадаючым спісе слоў і націснуць «Распазнаць». Вынік адлюструецца ў полі «Распазнаны тэкст» справа (малюнак 2).
- Таксама можна праслухаць аўдыязапіс абранага слова.

Малюнак 2. Распазнаванне маўлення з убудаваных прыкладаў
Сцэнар 2. Распазнаванне маўленчай фразы, запісанай анлайн
- Зайшоўшы на старонку сэрвісу, націснуць укладку «Запісаць».
- Націснуць наступную кнопку «Запісаць».
- Вымавіць фразу ў падключаны мікрафон і націснуць кнопку «Стоп» для заканчэння запісу.
- Націснуць кнопку «Распазнаць» для адлюстравання вынікаў (малюнак 3).

Малюнак 3. Запіс маўленчай фразы анлайн
Сцэнар 3. Распазнаванне гукавога файла з лакальнага дыску камп’ютара
- Націснуць укладку «Загрузіць файл».
- Націснуць кнопку «Агляд…». Адкрыецца акно аперацыйнай сістэмы для выбару файла на дыску. Выбраць файл у фармаце .wav з лакальнага дыску камп’ютара (малюнак 4).
- Націснуць кнопку «Загрузіць», пасля чаго ў полі вываду справа адразу адлюструюцца вынікі распазнавання.

Малюнак 4. Распазнаванне гукавога файла з лакальнага дыску камп’ютара
Доступ да сэрвіса праз API
Для доступу да сэрвіса “Тэматычнае распазнаванне маўлення” праз API, неабходна адправіць AJAX-запыт тыпу POST на адрас https://corpus.by/ThematicSpeechRecognizer/api.php. Праз масіў data перадаюцца наступныя параметры:
- requestType — тып запыту: “recognizeWav”.
- fileBlob — wav-файл, закадзіраваны ў “base64”.
- domain — назва дамена. Даступны наступныя дамены: “clothes”, “digits”, “cities”, “colors”, “control”, “months”, “numbers”, “player_buttons”, “week”, “bel_all”.
Прыклад AJAX-запыту:
$.ajax({
type: “POST”,
url: “https://corpus.by/ThematicSpeechRecognizer/api.php”,
data:{
“requestType”: “recognizeWav”,
“fileBlob”: “TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCBieSB0…”,
“domain”: “clothes”
},
success: function(msg){ },
error: function() { }
});
Сервер верне распазнаны тэкст.
Прыклад выкарыстання дадзенага API — вэб-сэрвіс «Тэматычнае распазнаванне маўлення», укладка «Запісаць» (https://corpus.by/ThematicSpeechRecognizer/).
Спасылкі на крыніцы
Старонка сэрвісу: https://corpus.by/ThematicSpeechRecognizer/?lang=be
Перакрыжаваныя спасылкі
- CMU Sphinx
- Казлоўская, Н.Д. Распрацоўка алгарытмаў дыктаранезалежнага распазнавання беларускага маўлення / Н.Д. Казлоўская, М.В. Шыбко, А.І. Пратасеня, Ю.С. Гецэвіч // Развитие информатизации и государственной системы научно-технической информации (РИНТИ-2017) : доклады XVI Международной конференции, Минск, 16 ноября 2017 г. / ОИПИ НАН Беларуси ; под науч. ред. А.В. Тузиков, Р.Б. Григянец, В.Н. Венгеров. — Минск : ОИПИ НАН Беларуси, 2017. — C. 299-304.